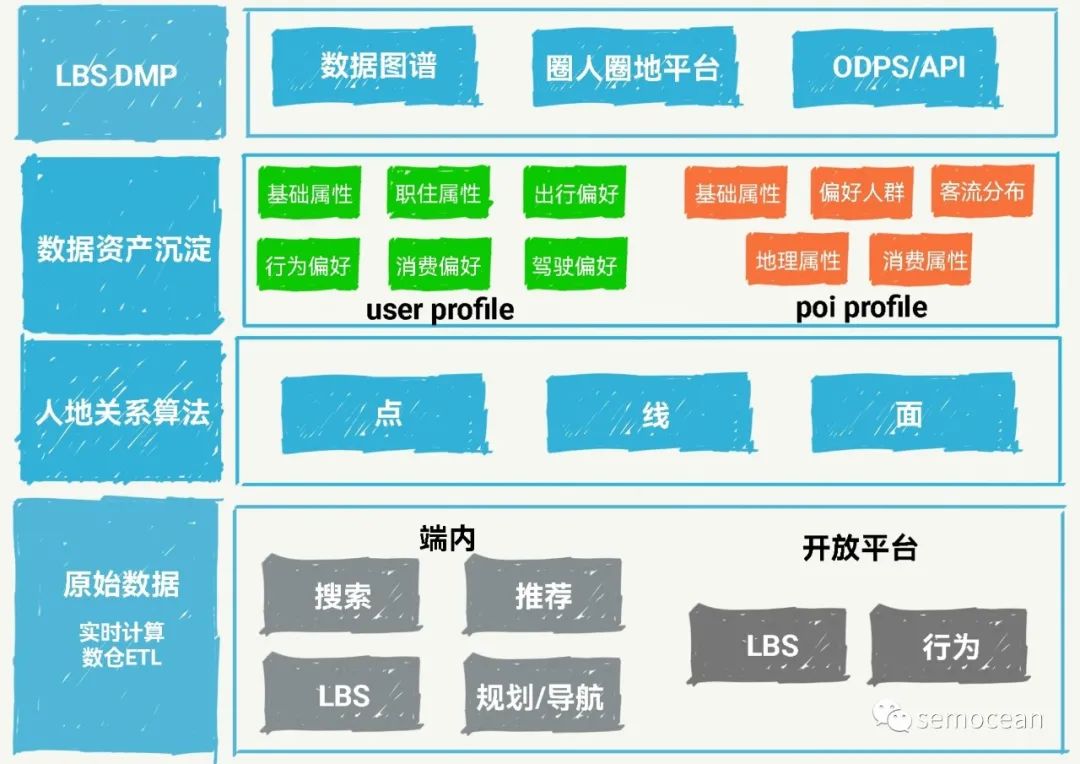
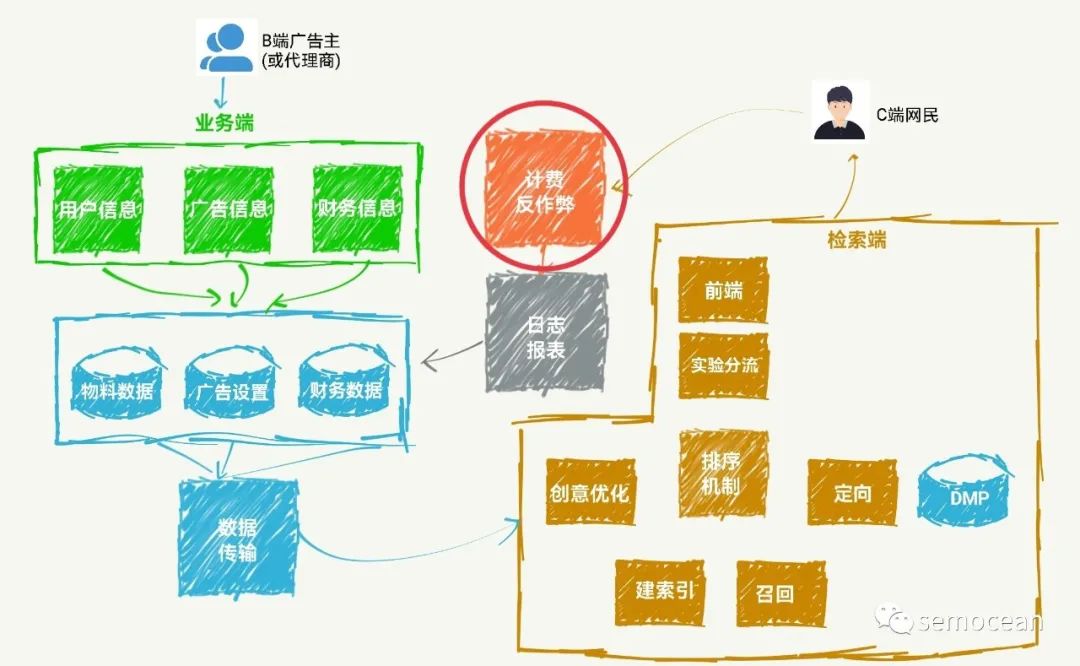
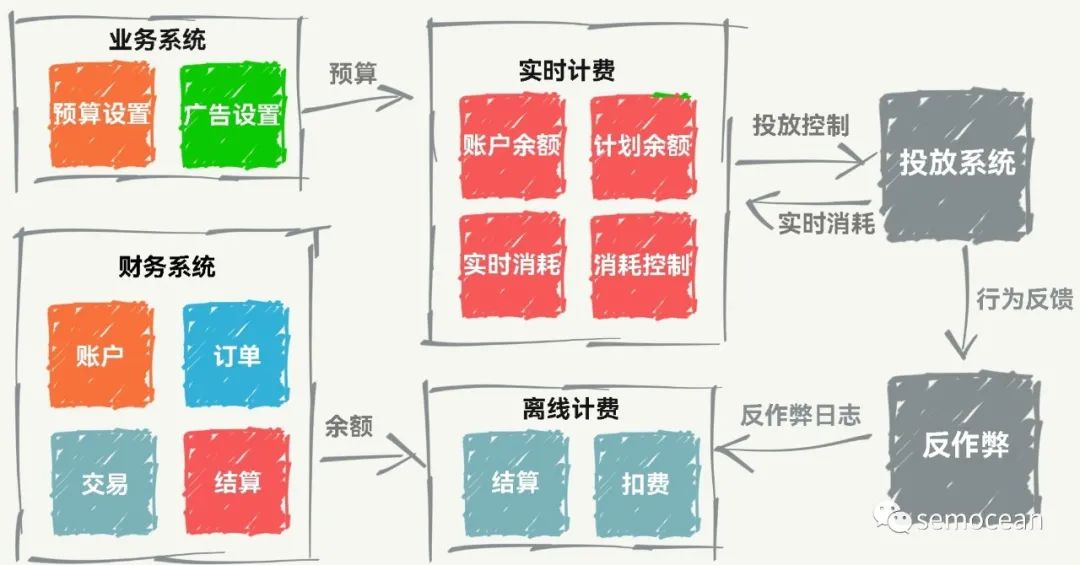
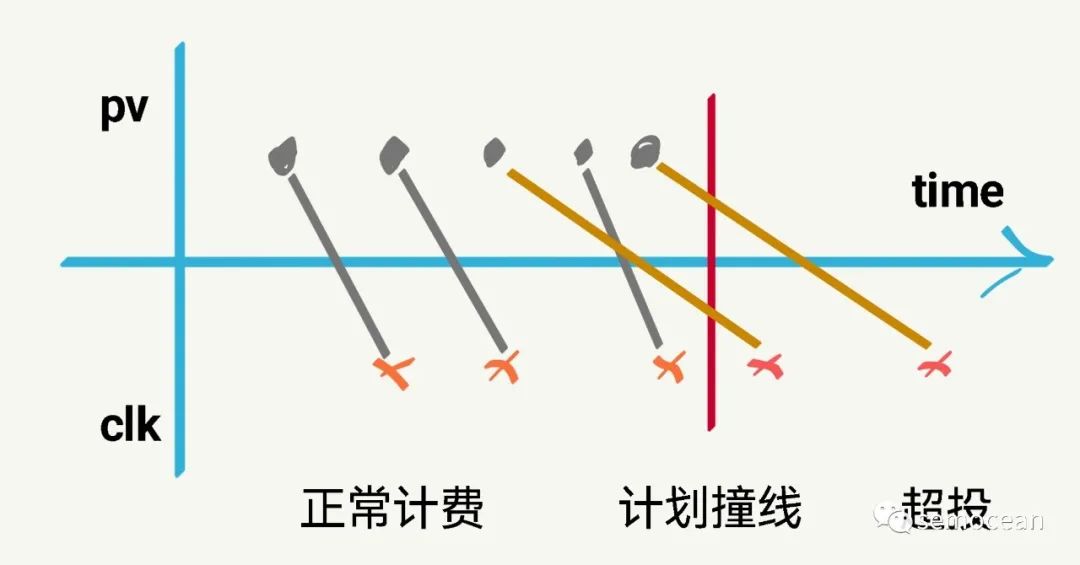
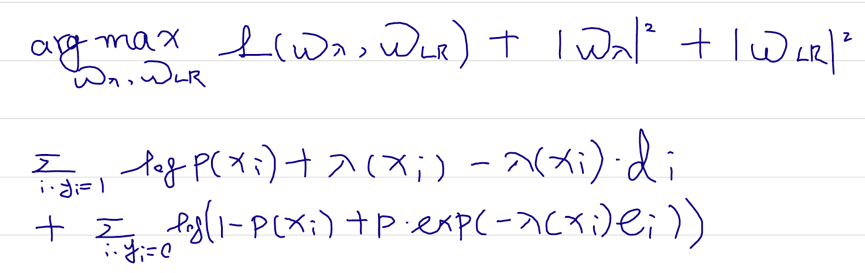先打个广告: 团队长期招p6~p9数据,工程,算法; 业务发展快。 感兴趣的同学可直接关注以下公众号获取岗位信息:

引言
各位研发同学,大家有没有这样一种感觉:就是在工作中, 你经常会有如下感叹:
- 为什么我们的产品需求如此多? 就不能想清楚再做吗?
- 为什么我们的产品居然给算法提了个效果翻5倍这样愚蠢而不可能完成的增长要求
- 产品抱个脑袋想出一个需求,研发就要吭哧吭哧搞半天,那产品平常都在搞啥?

总体来说研发同学有这样的想法是很常见的, 也是很正常的。 而且以我的经验,无论是大厂,初创公司,或者中型公司,都会存在这样的情况,无论是以工程师文化著称的百度,还是以强势业务导向的阿里, 或者其他一些小公司都不会例外。
下边我就来分析下研发为啥会有这样的想法, 以及站在产品的角度, 又会看到那些不一样的东西。
公司里最大的理,就是对业务的发展有利
在这里先抛一个基本原则, 无论你的角色是产品还是研发, 无论你看你对应的产品, 或者技术再怎么不顺眼, 这些都是有主观立场有屁股的看法, 而且是信息不完全的看法;每个人都会以自己的角度,自己的经验去看问题。
这样就会出现我经常和下属讲的:二元世界理论:同样一个事,从不同的角度看,会得到不同的结论,并且都是对的。
公司里边最大的理,就是要对业务的发展有利。其他的诸如研发觉得产品是不是需求提太多, 是不是需求不合理, 是不是在压研发的排期, 甚至是不是在找事儿, 这些都是有屁股, 有偏见的主观的看法,不是理
产品与技术的相爱相杀
前两年听淘宝一个研发负责人分享,末了一个听众问了个问题,大抵是问研发在业务需求非常多的时候,如何平衡技术长期建设和短期业务需求的关系。 当时那个研发负责人提到,‘产品和技术的关系,是相爱相杀的关系’,产品和技术都会有自己想做的, 自己认为重要的的事, 那如何去决定什么事重要, 优先级如何, 其实就会涉及到优先级的PK, 或者是较多的平衡。
产品与技术的目标一致吗?
可能这里有研发的小伙伴会问: 不是一直说产品和研发的目标是一致的吗? 那还需要平衡什么?
但你认真想想,产品和技术, 目标真的一致吗?
我个人的观点是: 产品和技术的目标, 是不一致的, 或者说是不完全一致的。否则从公司组织机制上,就不用专门分出来产品和技术两个工种了 。
那为什么说是不完全一致的?简单想想:产品会考虑稳定性吗? 会考虑实现如何具有可扩展性吗? 似乎不太会吧。
但技术需要考虑这些。 虽然有些技术小伙伴接需求接麻木了, 需求挡又挡不回去, 就干脆需求来了后就糙快猛把需求怼上去,产品说啥就是啥吧, 但最后系统越来越复杂,越来越慢,直到某天迭代不动了, 影响到了业务发展, 这是谁的问题? 其实还是技术的问题!
所以,大家的业务目标是一致的,但当业务需求提过来的时候,技术同学有必要,也有义务从技术的角度,审视需求的合理性,并需要结合长短期的技术发展,确定合理的方案
而且很多时候,以我的经验,技术的长短期方案的权衡,以及必要的技术投入, 其实都是可以和产品同学一起聊, 一起沟通的。 至少我打过交道的产品同学, 虽然他们更多从产品的视角来看问题,但你讲你的技术长期考虑,长短期如何权衡和他们沟通后, 都还是可以得到理解或者支持的。 如果确实有些需求是有很大的业务压力,必须要糙快猛地搞,大家至少在信息上是可以拉平的。 当然, 如果资源上实在无法拉齐,至少信息拉齐了,可以上升到老板来决策。 前提是研发需要有自己的判断。
产品业务同学的压力
很多时候技术同学觉得自己比较辛苦, 压力比较大,还被产品同学PUSH得不行,甚至心里委屈有气, 其实在和产品充分沟通后,换位思考一下, 其实产品,业务的压力更大。
为什么更大? 业务,包括产品都是需要背业务指标的,收入一年翻5倍, 核心指标翻3倍。。。 可能都是老板直接就拍下来了。
技术同学可能还会根据各种数据,指标估一个合理的可能的增长,但业务一般不是这样,都是先拍KPI,再想达成的手段,这样在KPI拆解的过程中, 就会导致很多理智的逻辑性很强的研发同学觉得产品对技术的要求高的可笑,觉得产品同学不靠谱,但其实这正是产品同学的压力所在。
很多问题其实就是个屁股问题, 换个角度看, 就能理解了。
开头的3个问题
对于开始的3个问题,读了上文后,应该就有答案了:
- 为什么我们的产品需求如此多? 就不能想清楚再做吗?
答:很难,没有人能预知未来,换你,也只能快速地去试,只能做到Fail Fast。 因为从‘肯尼芬框架’的角度来看,产品所处的象限是‘复杂’的象限, 技术所处的角度为‘繁杂’ 甚至是‘简单’的象限。 - 为什么我们的产品居然给算法提了个效果翻5倍这样愚蠢而不可能完成的增长要求
答:因为老板拍目标的时候,就是按照更高的要求拍下来的,产品也没地方说理(且不说很多时候高目标也能够实现) - 产品抱个脑袋想出一个需求,研发就要吭哧吭哧搞半天,那产品平常都在搞啥?
答:产品涉及各种上下游拉通,好好想想就知道了, 其实真的很操心
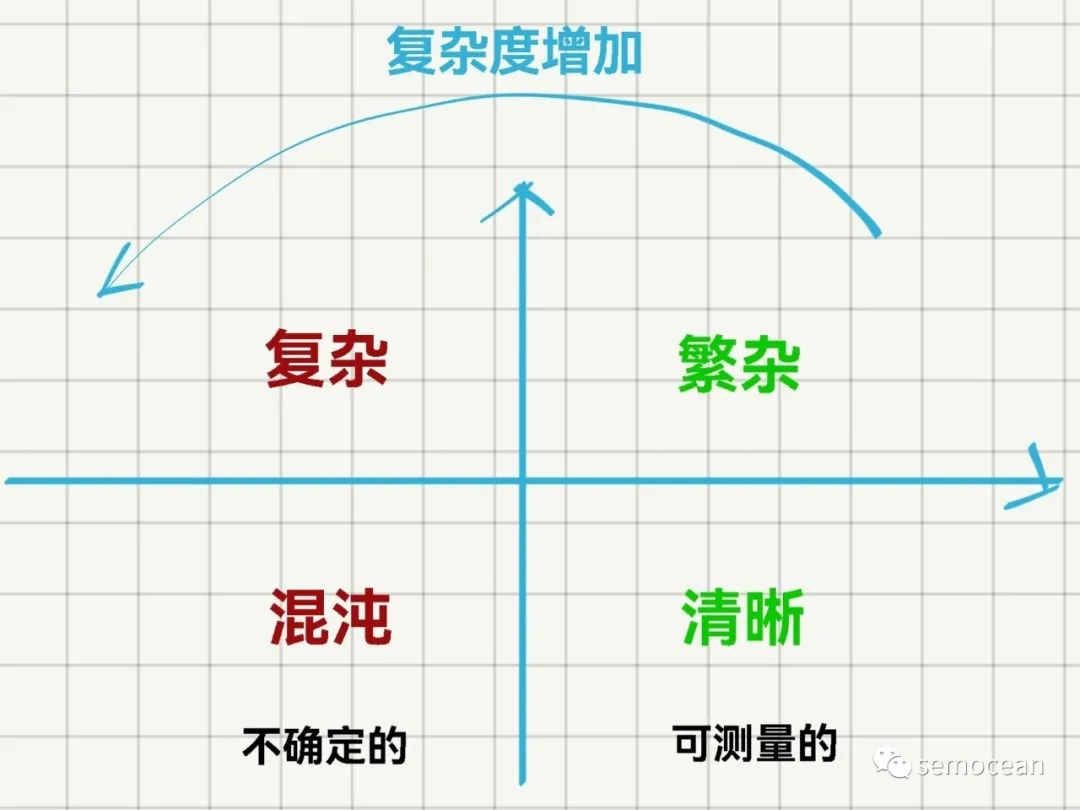
图:肯尼芬框架简图,产品业务一般处于‘复杂’区间,技术处于‘繁杂’或‘清晰’区间
但有一点是肯定的,产品在整个价值链路上处于中枢的角色,对全局的信息更加了解,而技术则处在底层,信息比较局部,仅是‘重要的环节’, 所以遇到问题,多和产品沟通,多了解下更加全局的信息,这样对整个业务的了解会更加全面和透彻。 在整个过程中不要有情绪,和产品同学的合作不要有偏见,这些都是主观的。 一定要记住:公司里边最大的理,就是要对业务的发展有利
P.S. 在公司里,一定不要因为不爽而和产品对抗,考虑问题多考虑上边提到的公司最大的理。另外产品同学更接近业务,是需要对公司发展,或者说挣钱负责的, 技术固然重要,但更多是公司运作的单一环节。 二者如果竞争,这就像一个6维空间的文明, 和3维空间的文明对抗一样, 维度不一样,结果可想而知。