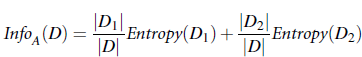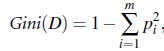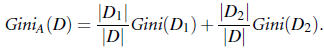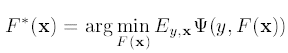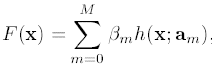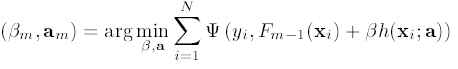本文以百度关键词搜索推荐工具字面相关性模型为基础,介绍一个机器学习任务的具体设计实现。包括目标的设定,训练数据准备,特征选择及筛选, 以及模型的训练及优化。该模型可扩展到语意相关性模型,搜索引擎相关性及LTR学习任务的设计实现。该模型的设计调研实现,也可以很容易移植解决其他包括语义相关性的问题
目标设定:提升关键词搜索相关性
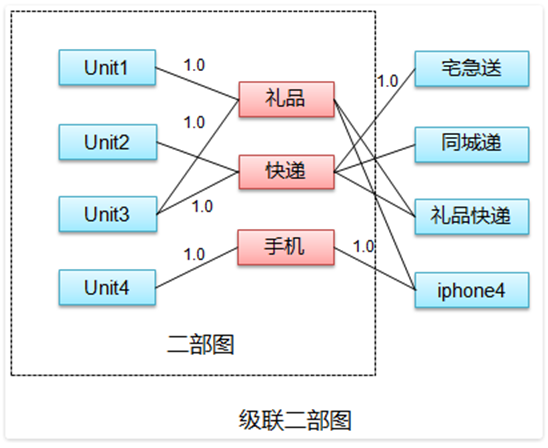
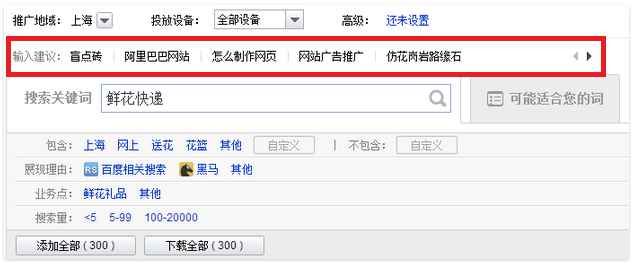
作为一个搜索+推荐产品,百度关键词搜索推荐系统的产品形态是向凤巢用户推荐适合他业务的关键词。例如一个卖鲜花的广告主,他想在百度上做关键词搜索推广时,需要提交和他业务相关的关键词,而且提交的关键词需要业务相关,例如他需要提交和卖鲜花业务相关的关键词。例如鲜花快递,鲜花速递等。此时他可以在百度关键词搜索推荐系统中进行搜索查询,选择适合他的关键词。
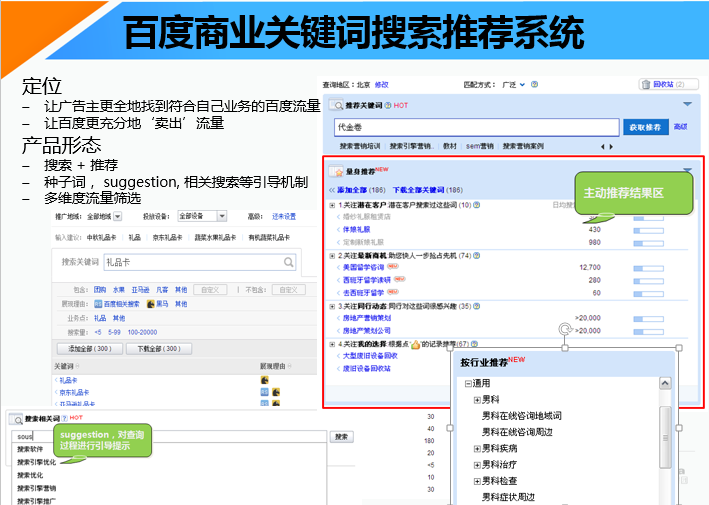

百度关键词搜索推荐系统query搜索
这是一个典型的搜索问题,具体的从输入query,到触发,到排序等会涉及到很多因素,例如如何查倒排,如果处理地域因素等;要提升搜索的质量,我们首先需要保证输入的query和推荐出来的推荐词的相关性,此处我们要解决的主要问题, 就是如何快速,准确地判断两个关键词(输入query和推荐词)的相关性,需要特别注明的是,我们主要的目标是让用户觉得该产品结果很靠谱, 所以该处我们仅考虑字面相关性,更多的语意扩展该模型并未考虑。
注:该模型的调研实验实现方式, 可以很容易平移到语义相关性。例如加入更多语意特征,例如plsa的bm25特征和word2vec的相似度特征(或者和扩展的相关性校验,例如将待推荐词扩展为baidu搜索结果的摘要扩展)提高语义特征的贡献。
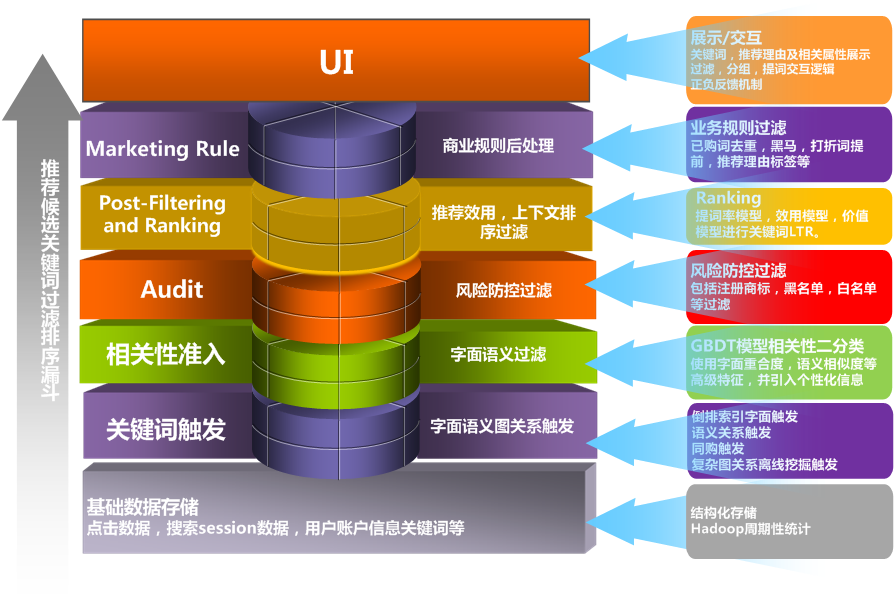
相关性也是所有搜索问题的基石,只不过在不同的系统中使用方式不一样, 在一般的搜索中,相关性占有较大权重, 排序基本就以相关性为依据; 在商业系统中,相关性则经常作为搜索展现的门槛用于控制商业推广结果的质量(如果仅考虑CTR, 用户搜索鲜花快递时,给用户展现艳照门的结果,CTR会更高,但相关性较差)。 当然,判断相关性我们可以简单使用某一种方法进行直接判定,例如直接进行两个关键词的TF-IDF计算,或是进行两个关键词的BM25。但这样的方式效果都不太理想,想要达到更好的效果,就需要使用更多特征,而更多特征很自然地,需要使用模型组合这些特征,达到最终的预期效果。
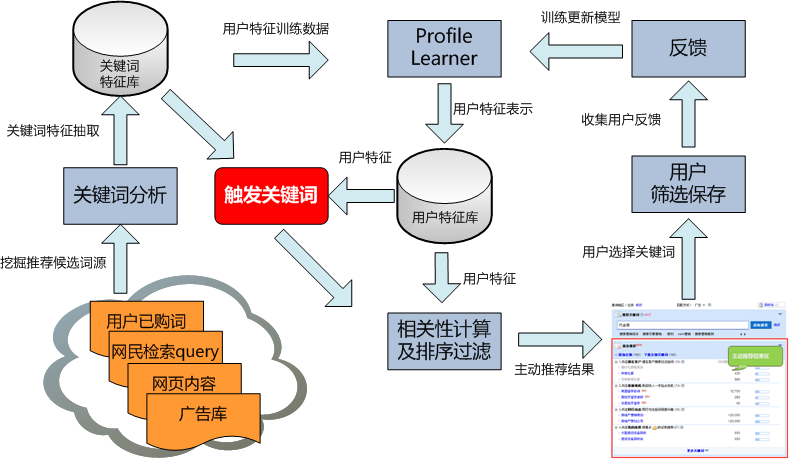
图:相关性在关键词系统中的位置
此处将会使用机器学习的方法解决该问题。本文以下内容会从数据准备, 特征选择, 模型选择, 模
型调优等步骤介绍百度关键词搜索推荐系统如何解决该问题
数据,特征,模型
说到使用机器学习解决问题,我们经常提到的优化思路就是3方面的优化: 数据,特征,模型。首先找到充足的,准确的label数据(该出仅考虑有监督学习任务,例如相关性,或是LTR),之后提取贡献较大的特征作为input space,以label作为output /ground true label,之后优化模型(Hypothesis) )。下面会分别从这3方面对整个优化过程进行阐述
准备训练数据
训练数据的获取一般有几种方式:
- 人工标注: 优点是质量较高,噪音较少;缺点是标注结果和标注者本身的认识相关,例如在搜索引擎中,判定苹果和手机的相关性,对于年轻人,一般都认为相关;但对于比较多的老人,可能认为不相关;另外一个缺点就是人工获取标注的成本较高
- 从日志中进行挖掘:优点是数据量相对更大,获取成本较低(编写几个hadoop脚本对日志进行统计);缺点是噪音较多,例如搜索引擎中的恶意抓取访问导致的噪音数据
在相关性模型中,一开始我们使用百度关键词搜索推荐系统的人工反馈数据作为label对模型进行训练,分别提取1.5W query-推荐词pair作为正负例进行特征提取,模型训练。
如图所示,在交互上,当用户喜欢该关键词时,就会点击‘大拇指’表示该结果符合用户需求(正反馈,该query-推荐词 pair可作为正例);如用户认为该关键词不符合需求,就会点击‘垃圾桶’,将该关键词扔入回收站(负反馈,该query-推荐词 pair 可作为负例)
在实验中,我们发现正例没有问题, 不过负例中会存在较多这样的情形: query-推荐词是相关的, 但该用户不做该业务,所以被定义为负例,所以负例个性化较强。所以后来我们让产品经理同学又对负例子进行筛选,重新标注1.5W负例,进行后续特征提取, 模型训练。
之后我们将正负例打散后(直接使用python random.shuffle)分成10份,进行cross-validation
模型训练前,先定标准和样本
注: 训练样本的挑选完全决定了我们的问题目标,所以在一开始就需要准确选择,如果可能,所有的case都最好人工来搞,或者至少需要人工review。 确定没有问题后,再开展后续工作。特别是相关性类似的问题,比较主观,例如PM和RD在该问题的判断上就可能存在一定差异。
确定完训练样本, 评估标准,之后再小布快跑, 优化模型。
特征提取
一般特征的选择及处理会极大地影响学习任务的效果,而进行特征选择的时候,一般是先增加特征,并实验效果。 对于相关性模型, 我们可以先将传统的信息检索的特征加上,这些特征一般分为以下几类:
- query/候选词的一般结构特征: 例如query/候选词长度,term数等
- query-候选词的相关性度量:例如TF-IDF, bm25, LMIR及多重变种, plsa相似度度量,word2vec语意向量相似度等; 很多时候,关键词自身信息较少,还可以使用关键词在搜索引擎上的摘要扩展进行相似度度量
- 关键词自身在信息检索维度的重要性度量,例如关键词idf, 从语言模型方面的重要度等
在一开始的时候,我们可以先将能够想到,构造出来的特征均加入特征向量进行实验,而且每加一类特征,都可以看下该类特征对整体目标的提升程度。以便对该特征的贡献度有一个直观的感受。
以下数据可以简单看出随着特征的增加,效果的提升,其中的特征仅加不减(模型使用random forest 进行二分类):

等到特征加得差不多,模型准确性已经提升不多的时候, 可以考虑砍特征,有一种比较简单粗暴有效的砍特征的方法,就是使用树模型,就是直接砍掉特征贡献程度及特征重要性较低的特征,例如直砍掉特征贡献度为0的特征,对相关性模型的准确性几乎没有影响
特征贡献度
当增加特征已经很难提升效果, 考虑到为了防止过拟合,同时考虑到模型online预测,需要对特征进行挑选。在使用树模型时,可以直接使用数节点特征贡献度和节点使用次数,判断是否需要去除该特征,以下为使用树模型进行选择特征的例子:
对于特征贡献度和分裂特征使用次数为0的特征,在调研时,直接去除对模型效果几乎没有影响,而且能提升预测的效率。
在选择特征的时候, 有一些经验值得分享:
- bm25特征及term weight特征对分类任务有极大贡献
- 一些单独的比值类特征并没有太大贡献,例如query,推荐词共同term与query term数,推荐词term数的比值,这些特征并没有太大贡献,但是这些特征与query,推荐词的term数结合到一起,贡献就非常多;所以有些特征需要联合在一起,才有较大作用。
- 特征选择需要和目标一致:例如word2vec是非常高大上,且非常靠谱的技术,但用在字面相关性,对目标并没有太大贡献(如果目标是语意相关,那么类似于PLSA,word2vec将会有很大贡献)
- 有些特征就就是用来解决特殊case的,虽然贡献不大,但需要保留(当然也可以直接设置为强规则与模型配合),例如query与推荐词拼音一致
模型选择
经典模型
最开始我们尝试了最大熵,SVM和adaboost模型, 考虑到online使用的效率,最终我们选择了adaboost模型作为线上使用的模型,虽然效果不是最好的,但使用简单的weak learner构建的模型的确比较快(参见博文:《adaboost》),并且使用adaboost进行上线并取得较好效果:上线后不仅召回增加,准确性上90%的case相关性高于等于原有结果(采用非模型的版本)


评估结果分布图(2到-2分别代表扩召回结果相关性高于、略高于、等于、略低于、低于线上策略)
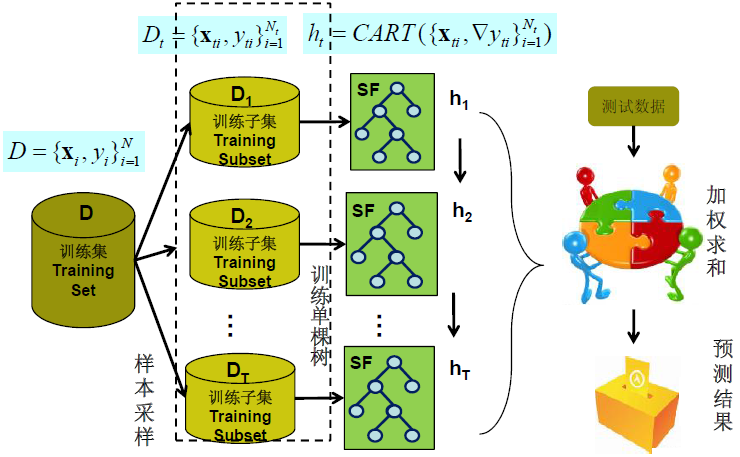
集成树模型
现在特别喜欢使用树模型,因为使用的时候,连特征归一化都省了: 如果使用SVM类似的模型,还需要对特征进行归一化等处理, 但使用树模型,直接将特征向量及label扔给模型, 模型自己会根据信息增益,或是基尼系数等标准选择最合适的拆分点进行树节点的拆分(具体的拆分标准可参见博文:《使用impurity选择树模型拆分节点》),开源的树模型,例如大名鼎鼎的Quinlan的C4.5或是C5.0都在调研时都可以拿来试试作为特征选择的依据。
特别是集成树模型的出现,更是极大地提升了树模型效果。所以现在的项目中,我比较喜欢在增加特征的时候就使用集成树模型进行效果实验。 具体树模型使用参见《集成树类模型及其在搜索推荐系统中的应用》
集成树模型配置选择
此处的配置选择和传统的模型参数稍有区别,该出的树模型配置主要指集成树模型中树的数量,每棵树的特征选择因子和样本使用因子等。在项目中,考虑到准确率和速度,最终确定的参数是树的数量是20, 特征选择因子和样本选择因子均为0.65(每棵树随机选择0.65的样本和特征进行训练)
具体产品效果可参见www2.baidu.com中百度关键词搜索推荐系统的排序结果:
如何个性化
首要需要考虑的是我们的数据样本,是否本身就是包含个性化的case(此处的答案是否定的); 假设我们的标注case是个性化的,也就是case中本身就包含了个性化结果时,在模型训练流程上其实并没有太大区别, 主要的区别就在于我们选取哪些能够区分这些个性化的特征, 例如百度凤巢中账户(单元)的plsa模型产出的pzd向量与query的相似度等
登录www2.baidu.com->关键词工具->搜索query->查看结果 即可。
更多内容也可参见: http://semocean.com