还是先插个招聘信息: 急招推荐,搜索,语音算法,数据挖掘,工程人才,阿里P5~P9,欢迎推荐和自荐,微信扫码关注以下二维码了解详细信息

以下才是正文。。。。
从毕业步入职场到现在10年多的时间,就一直在搞两个技术领域:搜推广信息分发以及LBS。
搜推广不用说,近十年一直都是热门的领域,另一个是LBS的技术,可以说也是深入到我们生活的方方面面。过去既做LBS的信息分发,也做底层的实时路况,ETA以及RP算路,甚至更底层的地图匹配(或者叫抓路,绑路,map matching),目前,更多在做人地关系大数据,以及基于LBS的搜推广。相当于将两个领域结合到了一起。
更详细的LBS相关内容可参见:
GITC演讲-滴滴路况感知AI及应用
[LBS]地图Map-Matching流行算法及应用
[LBS]工业界ETA应用及滴滴WDR技术

《在高德如何吃喝玩乐!LBS信息分发的AI技术应用》就是团队的工作在高德技术开放日进行的介绍,感兴趣的同学可以在抖音,B站等平台观看交流。 具体B站的链接视频,参见‘阅读原文’

对于地图平台,无论是高德地图还是百度地图,腾讯地图,现阶段心智最强的功能还是出行。而在整个出行的用户交互过程当中,用户首先需要进行定位,确定自己所在的位置,然后进行POI的搜索,确定要去的目的地,之后就是怎么去的问题?包括路线规划导航ETA等相关技术。
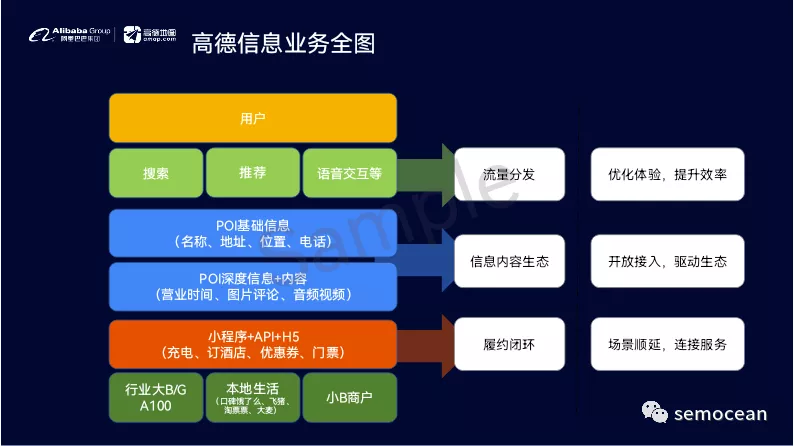
随着地图平台的定位由出行工具逐渐转成吃喝玩乐相关的LBS本地生活平台,信息分发的范畴也在扩展:从原有的POI搜索,展到了交易的分发以及广告的分发。
同时,这个过程当中需要有非常多的内容的理解,包括文本,语音以及视频内容的建设。具体参见:ID+图像特征联合训练CTR模型
同时,分发的手段也有更多的扩展,由原来的搜索,扩展到推荐以及语音的更多的交互方式。包括搜前,搜中,搜后,语音主动提示等多种交互方式,和用户进行信息的交互。(完整的工业级搜索+推荐 用户交互机制实现参见:关键词推荐工具中的用户引导机制)

同时,分发的形态,也由原来的单纯的POI list,扩展到视频,聚合榜单的更加丰富的模式。

对应的工作也包括最底层的数据建设,上层的引擎平台的建设,通用算法策略的建设,以及业务的定制。都是非常复杂的过程。

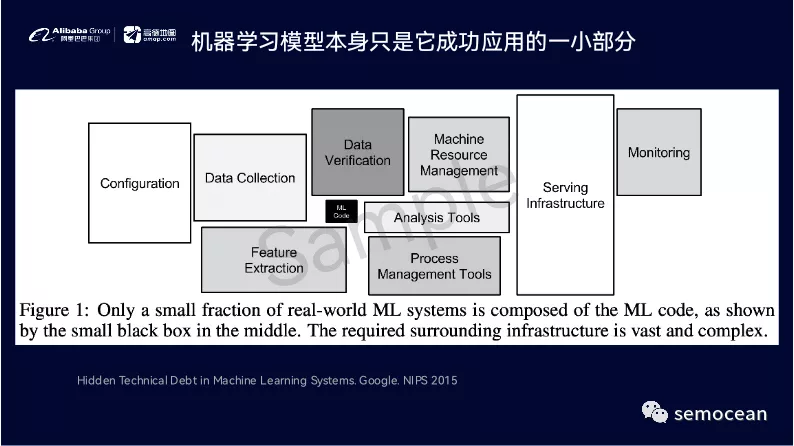
在这个过程当中,也会用到非常多机器学习相关的算法模型,当然,我们要时刻意识到,机器学习模型只是整个业务逻辑很小的一部分,虽然它起着无可替代的重要作用。
LBS的搜推广和传统的信息分发最大的区别,就是他会有很强的空间,时间的划分属性。
在LBS场景,每一个区域,或者每一个POI,都可以看成他是一个个的局域网,这些局域网之间其实是没有非常强的关系的,例如一个云南的用户,可能从来也不会去一个天津的饭馆吃饭,因为地域天然将这两个要素隔离开。 这和淘宝的信息分发是有本质的区别的,在淘宝上,一个云南的用户和一个天津的用户可能都会买同样一个商家的,同样一个商品,而且几乎代价是没有区别的。
因为地域,或者距离的差别,就会导致LBS的信息分发和传统的信息分发有本质的区别,这样就衍生出非常多的LBS信息分发独特的技术。
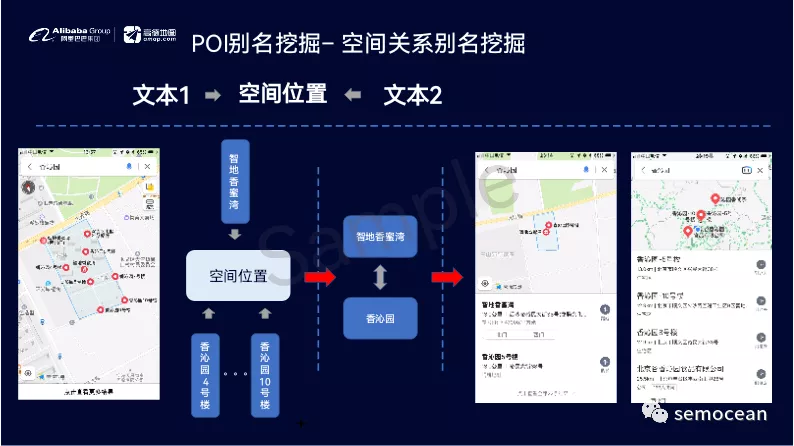
例如POI的别名挖掘,如何挖掘同一个地点的不同的别名。 以及反过来如何挖掘不同地点,有相同名称的POI,都是特有的结合LBS空间挖掘的技术。
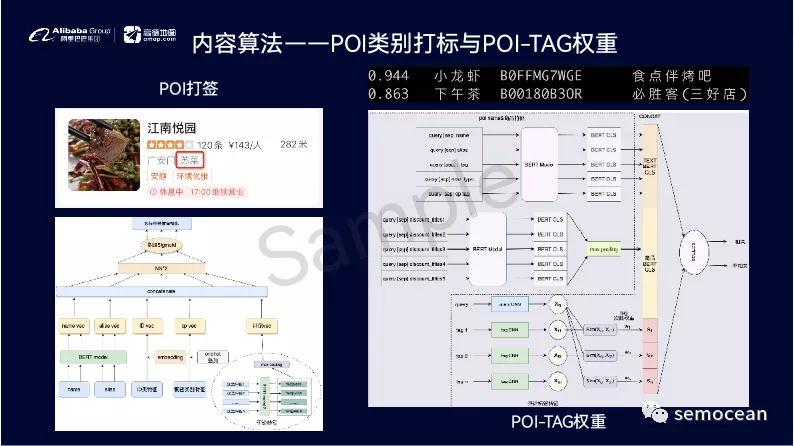
同时,我们会依赖于用户的搜索,点击导航路线规划以及位置信息,去使用定制的序列模型挖掘用户的行为序列信息,去做更准确的用户个性化定向。
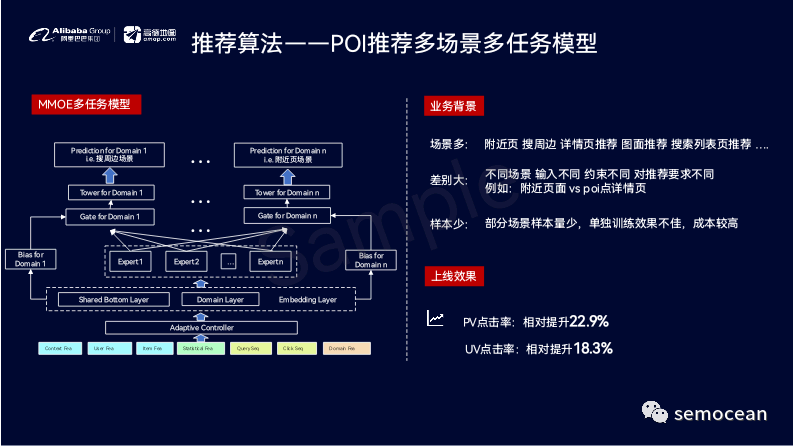
在地图场景,需要主动给用户展示信息的入口/场景非常多,而且不同的入口有不同的产品形态和定位,如果对每一个入口都定制一个推荐模型,那维护的成本是非常高的;同时,不同入口的信息无法共享,所以我们也是用了多任务的模型,对不同入口的推荐算法进行统一的建模。(具体ctr预估参见:推荐系统,变现系统CTR&CVR预估算法演进-模型)
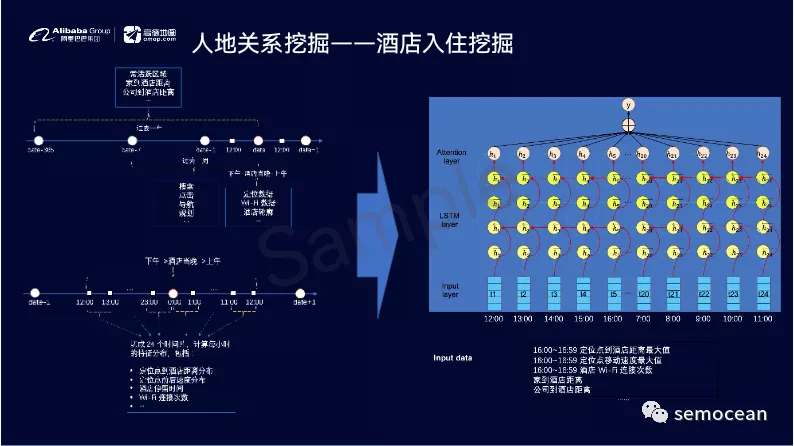
而且在地图场景,我们使用了丰富的LBS数据,却对用户的时间,空间,行为进行预测,例如,用户接下来会去的地点,区域和城市,并且取得了显著的效果。
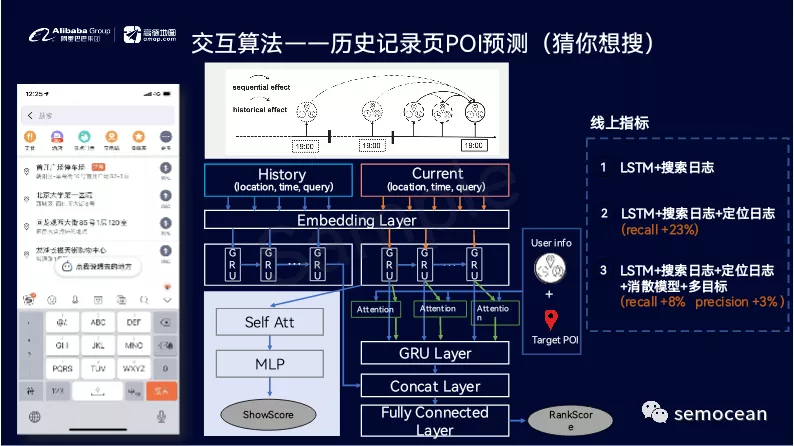
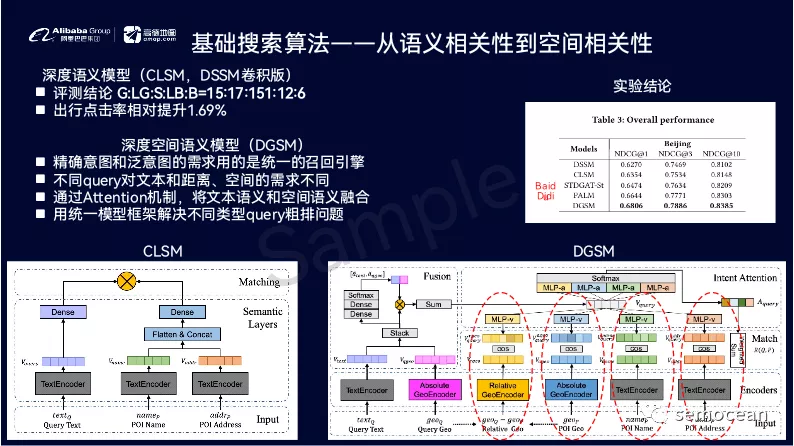

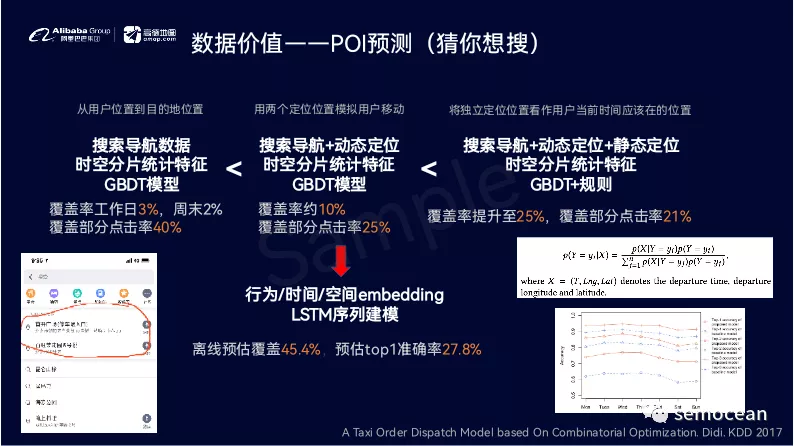
这个领域的工作非常多,也非常有意思,而且LBS本地生活是非常重要,非常有前途的一个领域,也是目前各个大公司重兵投入的兵家必争之地。如果大家感兴趣,请联系我进行高德岗位的内推。