介绍
很久没买美股了。昨天打开雪球扫了一眼结果惊呆了, 猎豹移动(CMCM)一天居然跌了40%, 其市值几乎和其现金等价物一致。于是搜了下新闻看到底发生了什么。后来了解到原来是Kochava(第三方监控公司)曝光猎豹旗下数款工具APP存在恶意欺诈行为,主要是大点击和安装劫持。做过移动广告的人应该都知道这两种模式,且这两种模式在行业内已经是不公开的秘密。之所以这两种恶意欺诈能够成功,主要还是因为现在移动应用市场归因机制的天然缺陷导致的。
目前国外应用市场相对比国内规范:国内各种应用市场,包括手机厂商自己的应用市场,以及BAT等巨头。而国外几乎只有两家,苹果的App Store和GooglePlay。但两种方式均存在安装归因缺陷。目前的方式是第三方监控公司(类似于Appsflyer, Adjust, Kochava等)监控来自某个应用或publisher的Impression或者click,之后在手机客户端产生app安装激活后,根据之前记录的来自该手机的impression和click,判定该安装应该归因给哪个publisher。该机制貌似合理,但存在很多问题:
- 归因时间过长,很多时候归因时间窗口能达到7天
- 第三方无法监控impression,click是否真实发生(可能是欺诈服务器自己构造的)
- 恶意抢归因:例如在用户没有看到,点击广告的情况下模拟impression和click, 让后来用户自然安装的应用被归因为广告的效果,或者直接监控手机用户的app下载,在检测到用户正在下载的时候发送该app的impression或者click强占该归因。可以认为和拦路抢劫比较类似
这些机制的存在都会导致整个移动互联网广告市场的混乱,大家不再专心做效果,而是将更多的心思和研发资源投入到如何构造更高明能绕过反作弊的机制。而辛苦做效果的广告公司却因为收益被抢而难于存活,形成劣币逐良币的恶性循环。
相关的欺诈反欺诈技术,不是一两篇文章能够描述透彻,也不是今天要讨论的内容。本文主要关注的点,主要还是讨论如何使用技术的问题,来对延迟归因进行建模。
图:CPI广告示例,流量测以cpm和publisher进行结算,广告主侧以cpi进行结算
之所以存在这个问题,是因为刚才提到,移动CPI(按安装付费)广告的归因窗口可以长达7天,甚至到30天:即广告在被展示后,点击后,最终的归因,例如移动CPI广告的安装激活可能在用户展示点击后的7天才会发生,这和传统的CTR预估问题不一样, 传统的CTR预估,可以认为在向用户展现广告后我们马上就能知道用户有没有点击,而手机移动端则可能需要7天甚至更长时间。这样在训练模型时,就会带来以下几个挑战:
- 数据量:对于CPI广告,安装毕竟是少数,如果仅使用有点击的训练样本进行训练,会导致训练样本较少,学习出来的模型能力较差
- 训练样本的选取有偏:即使是CPI广告,在线上进行预估的时候,也是有impression(甚至是有request)的时候就需要去预估CPI,而如果我们仅挑选有点击的展示作为样本进行训练,会导致和线上真实面对的分布不一致
- 如何选择训练样本? 传统方式下有以下几种方案:
- 因为新的广告不断出现,故需要模型及时更新避免效果损失,但如果在模型训练的时候,将暂时还没有转化的样本视为负样本,则可能将后续潜在的正样本也当做负样本进行训练,效果不会理想
- 收集满7天数据后进行训练。此时是否为真实正样本已经确定,但该方式的缺点是模型会滞后7天才能训练出来
- unlabeled的样本(还暂时没有conversion的样本随机作为负样本),相当于半监督学习,该方式的缺点是:线上click后产生conversion的分布并不是随机的,而是离点击时间越长,转化的概率越小
所以以上传统的3中方法都不太可取。而既然click后产生conversion的分布不是随机,而是离点击时间越长,转化概率越小,那能否将该信息建模到模型中。本文参考医学中的survival time analysis方法,根据click到conversion之间的时间差,对样本是否为真实正样本的概率进行建模。

图:impression->click->conversion的样本空间差异,如果仅用有click的样本训练pcvr,则会导致和线上impression的空间不一致

图:click->conversion用户安装,中间的时间间隔可以达到7天,导致7天内很多样本都是unlabel状态,因为并不能确定没有conversion的样本后续就不会有转化
问题定义
线上的目标是准确预估ecpm,即千次展现的花费。而ecpm可以进行如下拆解:

其中1)项我们可以认为是传统的pctr模型,2)为pctcvr模型,即在有impression,click的情况下产生conversion的概率
故可以对问题进行一下定义:

此处我们根据线上数据,能观察到的数据如下:
- xi:即特征
- yi:截止到现在,是否已经发生conversion
- ei:从点击到当前时间的时间差
- di:如果yi=1,则从click发生到conversion发生的时间差
以上定义存在以下约束关系:
- Y=0-->C=0 or E<D 还未观察到转化,则可能该样本为负样本永远不会转化;或者E<D,即后续会产生conversion只是现在暂时还未发生
- Y=1-->C=1
- P(C,D|X,E) = P(C,D|X) 即样本的固有属性,不会应为观察时间而改变
有了以上定义和约束关系后, 即可对问题进行重新建模,将问题建模为以下两个子模型:
- P(C|X):即传统的pcvr模型
- P(D|C=1,X):即给定样本特征后,且假设该样本为正样本的情况下,conversion发生的时间
再具体到具体模型的实现,P(C|X)为经典的pcvr预估模型,故可以使用传统的LR模型,或者更为复杂的模型。此处假设使用LR模型,即:
P(C|X) = 1/(1+exp(-w_lr*x))
而P(D|C=1,X)则使用指数分布进行建模,即:
P(D|C=1,X) = lambda(x)*exp(-lambda(x)*d),其中lambda(x)=exp(w_lambda*x)为hazard函数,此处借鉴了survial time analysis的思路。故最终建模中,需要学习的参数有两组:w_lr和w_lambda。
损失函数
对观察到的数据,分为两类:
- P(Y=1,D=di|X=xi,E=ei),即已经观察到存在转化,为C=1的情况推理公式如下:
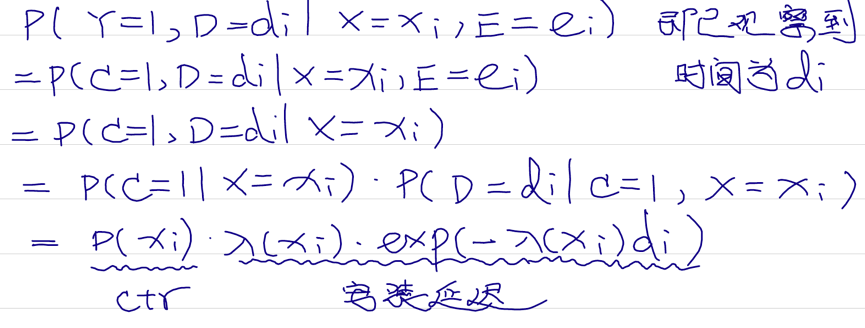
- P(Y=0|X=xi,E=ei),即距点击已经过去了时间ei,但还未观察到conversion,推理公式如下:

在Y=0 and Y=1的情况都公式化后,根据我们能够拿到的数据<xi, yi, ei, di>,根据最大似然估计构建损失函数:
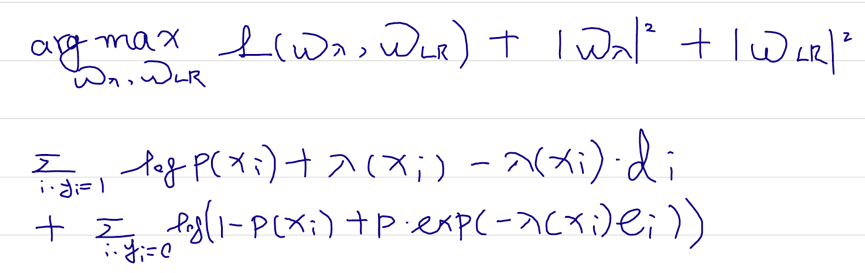
之后使用梯度下降法求解w_lr和w_lambda即可完成建模。
总结
- 该方法适用于用户行为存在较长流量漏斗, g. 移动端request -> impression->click->conversion,且click->conversion存在较大延迟的场景
- 该方法能够使用impression对应的数据进行建模,且建模的过程中引入了对click后产生conversion的时间观察,更符合样本的内在天然属性
- 该方法不仅适用于移动端cpi广告,同时对电商类似的具有较长流量,交易漏斗的场景同样适用。
参考文献:
- <Mobvista海外移动变现系统核心技术>
- <变革:从运营驱动到数据驱动>
- Chapelle O. Modeling delayed feedback in display advertising[C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014: 1097-1105