先打个广告: 团队长期招p6~p9数据,工程,算法; 业务发展快。 感兴趣的同学可直接关注以下公众号获取岗位信息:

前言
通过阅读本文, 可以有两方面的收获:
- 我们针对LBS 场景的DMP建设, 定义了新的基于底层人地关系原子能力的范式,避免了传统DMP用户数据生产过程中, 标签建设代价过大,无法迅速扩展的缺陷
- 展示了分层DMP建设的框架
个人隐私相关的行业背景
最近国家密集出台史无前例的互联网个人隐私管控的法律,以及算法管控备案的条纹, 例如:《互联网个人信息保护法》中明确对互联网APP个人信息收集,利用做了非常严格的限制。
对于各种设备级ID的使用, 例如原来imei, idfa, androidid等都有较为严格的限定,对于类似于轨迹,定位数据也做了较为严格限定。
从系统分发的角度, 《互联网信息服务推荐算法管理规定》也对算法的分发提出了较多要求, 对于个性化, 大数据杀熟等国家也在加强备案和管控。
在这样的行业背景下, 互联网的大数据使用会逐渐趋于规范和精细化。 这里需要明确的是, 国家不是限定大数据的发展,而是限定原有不规范,粗放式的数据使用。
例如早些年我的确听说有些公司对外提供DMP服务,按照请求次数收费,各种个人隐私数据不管应用方的类似随便使用, 这样的确是很恐怖的情况。 因为现在每个人在手机上产生的数据太丰富: 包括家庭住址,信息获取偏好, 购物, 所在位置等。
挑战
在这样的大背景下, 在构建工业级的LBS DMP体系的时候, 就会面临两大类挑战:
- 传统的技术挑战, 更多是技术问题, 包括如何更高效,实时地处理海量数据; 如何从数据中,对业务的LBS 能力进行原子能力的抽象; 基于原子能力如何对数据资产沉淀, 以及如何更通用化, 更高效地对外提供数据能力的支持。 每一个点均能衍生出较多非常多的技术挑战点需要攻克。
- 新的隐私数据安全, 包括哪些隐私数据我们能够收集, 哪些能够使用, 应该如何使用, 提升个性化效果以及触及个人隐私的边界在什么地方,这些都需要在数据使用,系统设计实现的时候充分考虑。 毕竟我们在社会主义的红旗下,需要做遵纪守法的产品研发,打造合法的系统。
同时,在大数据时代,我们也不可能就因为个人隐私风险而放弃对数据的建设, 毕竟互联网快速发展了20多年,基于数据算法的个性化被证明是提升系统效果的利器, 过去工业界,学术界的算法得核心也是数据驱动的个性化精准分发, 同时以后随着数字化的发展, 更多IOT设备的加入导致更多的信息需要处理都需要我们有更加强大的数据处理能力。
所以各个公司, 特别是阿里,腾讯,字节等大厂, 更是会在这一块工作上持续投入。 都会构建自己工业级的LBS DMP,以便在各种搜广推的分发应用中,提升分发的效率。
下边就为大家介绍我们LBS DMP建设的思路。
设计
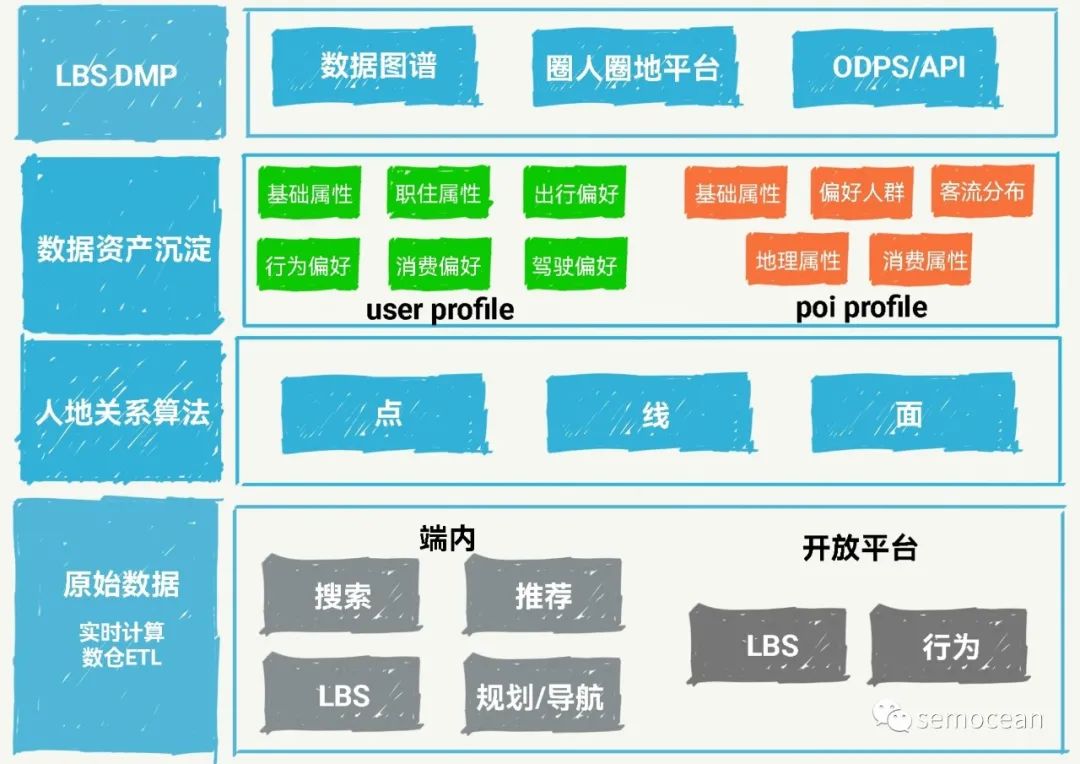
图:LBS DMP架构分层图
工程实现
从具体设计实现的角度,高德的LBS DMP从工程的角度和业界是比较类似的,从底层数据到上层应用,主要分成以下四层:
- 底层原始数据数仓,该层主要包括原始的数据收集,数仓ETL建设,以及对应的实时计算。具体的数据包括超级APP端内的搜点规划导航等LBS数据和用户行为数据的处理,以及高德开放平台数据。这两类数据一个最大的区别就是APP端内数据可以对应到具体的用户,但开放平台的一部分数据,我们是对应不到具体的用户的,拿不到体用户ID的数据,这些数据可以用来做热力相关的应用。具体实现层面,该层我们会基于ODPS和Blink来进行数据处理。
- 第二层是我们的人地关系算法层,该层更多的是基于我们的原始数据做进一步的深加工,包括对应的数据挖掘以及实时的算法处理。该层的算法挖掘质量会决定最终DMP效果。在实现层面,我们会用到非常多的深度学习,以及推荐类似的算法,所以也需要算法架构的支持,这次我们就基于AI OS去打造我们的数据挖掘和匹配逻辑算法。但是我们会给我们的应用场景去抽象,我们极少的原子能力,不求多,但求精。
- 第三层是我们的数据资产沉淀层,我们需要基于第二层打造出来的核心原子能力,进行灵活的拼装,组成上层应用,包括实时或离线的特征和标签,这些特征和标签既有表征用户长期兴趣特点的类型,又有实时用户的状态,行为的类型,例如,用户长期的类别偏好,兴趣偏好,这些都是用户长期的数据积累下来的,并且是在一定时间之内,不太会改变的用户的固有属性,这种就是长期的兴趣标签数据,另外,类型是跟永辉相关的事实,实的会很快改变的,需要快速补充的类型,例如,当前用户的需求是不是在饭店需要吃饭?是不是在外地需要订酒店?甚至细化到最近30分钟是不是有酒店需求这样的动态标签,这些都是实时类型。 从我的角度,我们对标签的定义进行了扩展:这些都是标签,只是长期兴趣标签总体来说没有时效性,相对稳定而短期实时标签具有动态性和时效性。
- 第四层就是服务层,例如,以什么样的方式对外提供数据服务,构建什么样的中台,什么样的通用的数据方式去提供通用的数据解决方案。这层我们会基于阿里的 AIOS,并且配合我们的数据管理平台,对外提供通用化的数据伏。
算法
从算法的角度,最重要的就是我们如何去抽象我们的LBS场景问题,将众多的数据以及对应的应用抽象为可数的几个核心原子能力。
原子能力
这里先解释一下什么是原子能力:原子能力就是基于最底层的抽象,不能再分割的能力,而上层的更复杂的业务能力,都是由底层的可数的原子能力拼装组合并演绎而出。
之前在听美团的干嘉伟的一个分享的时,他提到所有的问题都可以进行拆解,再打碎为原子能力后重构,而对LBS场景所有的问题都可以根据时间,空间去进行拆解,所以我们在这样的拆解框架之下,只要我们的原子能力从时间和空间的角度分成点线面(空间)*过去现在未来(时间)的模式:

图:LBS 时空原子能力拆解
我们在建设上层特征及标签的时候,不再遵循传统的方式对标签进行一对一的深加工定制,因为这样是有一个扩展性的限制的,扩展性标签的代价是线性的,当标签非常多的时候,代价是不可承受的。不可能无限的扩展。
例如,在之前的系统中,我们建设了400多个标签,但之后就无法再高效准确的维护对应标签的数据质量,所以后来我们转变思路:所有标签都是基于我们的原则能力,在上层,进行组合加工得到最终的标签,底层的原则能力会持续地不断深化,
对于原子能力,我们在单点上进行深化建设,底层的原子能力,我们使用了非常多的深度学习及图关系的算法,讲原子能力做的足够准确,相反上层的组合做的足够简单,并且可解释,当然,底层的原则能力都需要配合debug分析平台来提升数据质量。
这一部分其实是这个算法的核心,因为算法会涉及到比较多和业务相关的数据能力,数据算法能力,所以此处主要就说一下思路更多的时间此处就不展开了。
这里也有一个比较有意思的现象,就是无论线上的搜广推还是离线的LBS标签建设,在实现的时候都是使用相同的思路。
例如,我们在线上搜光腿检索轮实现的时候,经常会进行召回排序机制将各个环节分开进行;比较有意思的是,在离线进行数据处理标签建设的时候,也会使用类似的思路,都是先招呼一个大集合,然后再去做排序,最后再进行挑选。像我们在识别一个用户,他的家庭住址的时候,也会先挑出来这个用户候选的家庭住址,然后再去做打分排序,最后再选TOP N。
或者在进行路线规划的时候,也是先选择一部分的候选路线,再进行排序。整个过程从框架思路上没有本质区别。所以这应该也是搞互联网技术的人比较倾向于招搜广推经验丰富的候选人,因为搜广推比较有经验的话,这些技术迁移到其他的领域也会比较方便。
从本质上来说,这些操作都是信息处理过程,都是user和item的匹配,这可能是这些技术比较相近最本质的原因。
成果
和公司相关的业务此处就不再展开。此处人地关系的通用原子能力,我们也发表了对应的论文,会在后续的文章中介绍。具体参见《learning the continuous context-aware temporal knowledge graph representation for user and poi understanding》
Reference
- Learning the Continuous Context-aware Temporal Knowledge Graph Representation for User and POI Understanding
- 阿里巴巴 AIOS