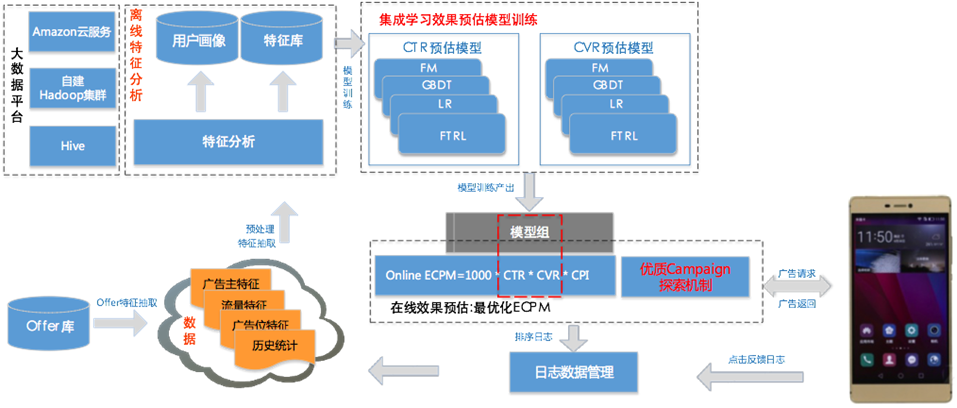
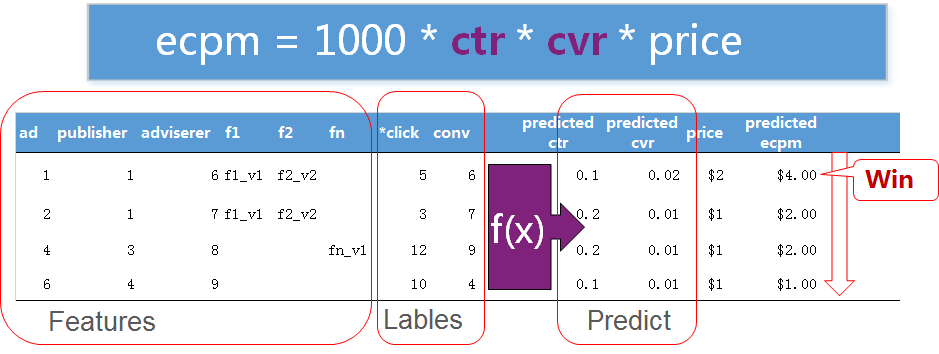
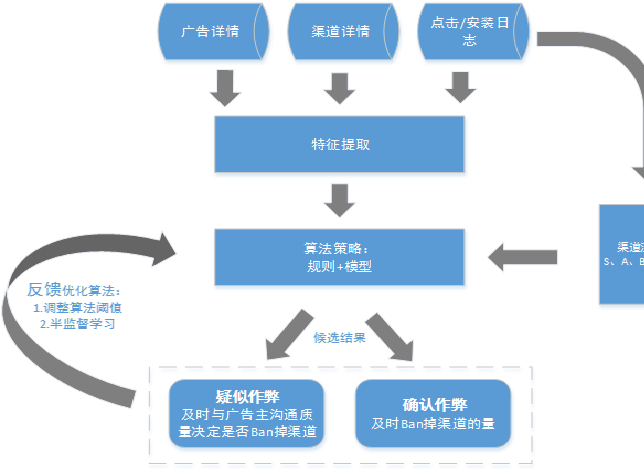
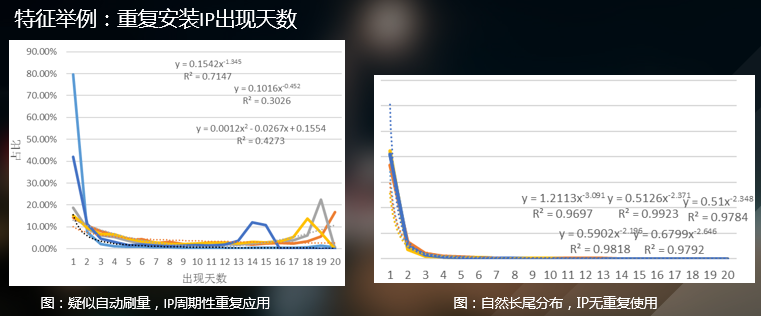
下文就百度商业变现的指标体系进行概要描述,并针对一个类似于百度LBS系统的变现思路,阐述一个商业系统变现策略指标体系的建立过程。
为什么需要商业变现策略指标体系
一般情况下,一个互联网产品,或是一个移动端产品在发展前期,主要会关注流量及用户量的增长。当流量,用户量做到一定程度时,就会考虑商业变现。例如今日头条,美丽说,高德地图这样的产品现在都开始商业化变现。而要从变现效果,效率衡量整个系统,以及监控技术策略对系统变现的贡献时,就需要建立一套完善的策略指标体系监控系统当前的状况, 发现系统策略效果瓶颈并有的放矢地去提升。
之前在百度,在和一位高级技术经理聊天时,他就说过, 之所以百度内部一位从Google过来的VP很受老板的重视,一个非常大的贡献,就是他推动百度凤巢指标体系建立,保证公司收入灵活可控,保证每次百度都能在华尔街交出漂亮的财报
指标体系包含的内容
广告主关心的指标
在广告界的人士都知道广告主的这样一句名言:“我知道我投入的广告费用的一半是白费钱财,但问题是,我不知道是哪一半”。而搜索引擎的搜索一大优点,就是能够监控每一次搜索点击的效果。
对百度广告主来说,他们最关心的,和所有的商业投资一样,是:投资回报率 (ROI)。广告主们(商家)想知道在百度体系的广告的投入是否真的有回报,而这个回报是否能够超过投入的资金,超过的比例有多大,这一点上,搜索引擎商业变现系统是做了精心的设计的:
从商家的角度理解ROI,就要了解三个指标:
1.广告展现次数(简称show):当网民提供关键字,使用百度的搜索业务时候,相关的广告也会根据算法出现在页面相应的位置,用户投放的广告的展现次数,每天,每周,每月都会有统计。 当然,相对于传统的广告投放模式,只要展现了就要收费,百度对展现的广告是不收费的,哪怕用户看到了广告主企业的名字和推广口号,广告主已经获得了一定的广告收益,是要用户不点击广告链接,广告主不需要支付任何费用(针对竞价排名高,和右端广告而言)。这在传统的广告界是不可想象的,因为传统媒体,例如电视,包括门户网站上的banner广告,都是按照展现收费的:看到一次收一次的费用。
2.广告点击次数(简称clk) :用户看到广告后,点击了广告主提供的链接。 可以用每千次广告展现的点击率来计算。网民点了推广信息的链接。推广信息被点的次数被称为点击量,即Clicks,产生的费用叫做点击费用,平均到每次点击的费用被称为单次点击价格,即CPC,是Cost Per Click的缩写。推广信息点击量与展现次数之间的比值被称为点击率,即CTR,是Click-Through Rate的缩写,计算公式为:点击率=(点击量/展现量)×100%
3.点击率到商业收益的转换:用户点击了客户的广告,就会看到客户自己的网站页面,如果被客户提供的商业服务或者产品所吸引,而付费的话,那么客户就实现了一次成功的商业收益
因为商业系统必须要保证客户(广告主)的利益,这样才能长久合作,所以商业变现策略指标体系必须包含这些指标。
在类似于百度,360,或是Google这样的搜索引擎, 其能精准监控的,就是1,2, 对于最终的商业转化,因为是在商家的网站上完成的,所以除非网站上内嵌了搜索引擎单独提供的独立工具(例如百度的福尔摩斯),否则搜索引擎无法了解这些信息。
投资人关心的变现策略指标
以上是百度广告主需要关心的指标。对于百度这样的上市公司,每个季度的财报中都需要有公司详细的赚钱相关财报内容及各种指标分解,以便了解当前变现系统的健康程度及瓶颈及后续的突破点。
例如百度的投资人不仅关心这个季度百度多挣了多少钱,还会关心多挣的这些钱是来自于哪个环节的提升,是否可持续, 是否后续还有增长空间。 就和分析公司财务报表,或是分析股权收益率一致。
为了让大家对搜索引擎变现策略指标体系有一个对比了解,以下先用股权收益率说明问题。大家可以不用有较强的金融,财务知识也能看懂这个公式,而搜索引擎变现策略的指标体系,与此公式有异曲同工之处,都是将最终的收益(率),分解为各个相对独立的因素,以便发现系统挣钱效率的优势与瓶颈。
该公式主要的目的是让大家了解如何对最终目标指标进行拆解,如果大家不感兴趣可以跳过该节。
股权收益率
即在股市中,投资人购买的股票收益率, 设想一下,一个精明的投资人, 在购买了某个公司大宗股票后,一方面会关注每年的股票收益,另一方面也会分析股权收益是来自于哪些因素的上涨,这样才能分析公司增长是否健康,例如,股权收益率可以简单地使用以下公式计算ROE=净利润/权益。但如果要对这个公式进行细分,将其中对股权收益率相关的影响因素均拆分出来,那可以得到以下公式:
其中
- 税收负担比例:反映公司的税收负担情况,例如有一个季度百度的税率为腾讯的一半,因为百度和国家有什么高新技术的合作所以税收减免(记得百度可能是7%左右,腾讯13%左右,不是精确比例),类似的情况就可以在(1)中反映
- 为公司向债权人负担的利息比例, 借的钱越多,这个值越小
- 利润率:为每一块钱的销售额所带来的利润。
- 资产周转率:为公司资产的使用效率,例如家乐福,沃尔玛虽然利润率很低,但因为出货量大,所以照样赚钱
- 杠杆比例:公司资产与公司权益的比例,用于表示用于赚钱的钱中,有多少是自己的,有多少是别人的(例如银行)。例如:北京以前买房的人都发了,因为买的早,一方面房价便宜,一方面使用银行贷款,假设30%首付,那相当于剩下70%银行贷款在房产上的收益,也是自己的。
类似地,如果对百度商业变现体系的收入进行一个拆解,也能将其分解为类似的独立因子,对系统效率进行细化分析。
搜索引擎投资人关心的变现策略指标
从宏观上,我们假设投资人都是唯利是图的,收入是他们最关心的事。当然,很多投资人也会兼顾长远的收益,所以他们会关系收入是如何组成的。我们这里抛开运营,股权收益,利息支付,税收等各种公司的开销,我们仅考虑变现系统的名义收入,即搜索引擎中计费系统的计费和。此时可以将搜索引擎收入分解为以下独立因子:
Revenue =PV * PVR * ASN * CTR2 * ACP
以上公式就是百度,360,Google搜索广告变现收入的拆解。
要弄清楚以上公式的具体含义,需要了解下列指标的定义:
- CPM1:cost per thousand1 按每千次检索收费, 百度用户每使用百度一千次做搜索为百度带来的收益。 也就是用户使用了百度服务一千次所带来的百度的收入。这个是衡量百度赚钱能力的重要指标。是百度变现能力的基本衡量标准。是根据每个季度的总收入除以PV(Page View)算出来的。
- CPM2:cost per thousand2 按每千次展示收费,广告所在的网页被浏览了一千次,即认为该广告展示了一千次。 这个指标是衡量广告客户的广告展现了一千次的时候,客户交付的费用(注意客户是在用户点击广告后才付费的). 这个指标可以衡量用户对于广告的感兴趣程度。从广告客户的角度讲,也可以衡量在百度投放广告的费用多少,以及投放的有效性。
- CPM3:cost per thousand3 表示平均每千次有广告展现的检索请求对应的广告收入,衡量单次有广告展现检索的平均收入贡献。这个指标是衡量当搜索结果的页面有广告展现的时候,每展现一千次,百度能够拿到的收入。有的搜索结果是没有广告展示的(CPM1把这些PV也计算进去了)。
- CPC:cost per click 按每次点击收费,是目前最流行的搜索引擎营销的付费方式,即只有当用户点击观看了你的推广链接后,才发生费用。
- CPA:cost per action 按每次用户消费行动收费,被认为将是互联网广告未来必然的发展方向,但由于不同产品的广告对action的定义和回报率有太大差异,实现过于复杂,目前在全球范围尚无搜索引擎使用CPA收费的成功先例。
CTR——点击率,在这里特指广告或推广链接出现后被用户点击的机率。CTR还将可以进一步的细分。
- CTR1:表示平均每次检索请求对应的广告点击数,衡量单次广告检索的平均点击贡献。理论上 CTR1 可能大于 1。因为每次检索客户可以点击一个广告,看了后,在回去原来的检索页,点击下一个广告。
- CTR2:表示平均每次广告展现对应的广告点击数,衡量单次广告展现的平均点击贡献。
- CTR3:表示平均每次有广告展现的检索请求对应的广告点击数,衡量单次有广告展现检索的平均点击贡献。理论上 CTR3 可能大于 1。
- ARPU:户均消费,影响它的因素包括:点击流量大小、关键词的相关性、同一关键词的竞争度,以及客户在搜索引擎广告上的预算上限等。
- PV:检索量,百度搜索框的搜索次数
- ADPV:出广告的检索量,即PV中,有广告展现的搜索数量
- CLK:click number,广告的总点击次数
- CSM: 百度广告主的总广告费支出
- ASN:平均展现条数。即:如果展现了搜索推广广告,每次平均展现多少条
- ACP:Average Click Price 平均点击价格 总消费/总点击
- PVR:Page View Rates, PV比率,出广告的检索量 / 检索量
有了以上这些定义后,我们再来回顾变现系统的计算公式:
Revenue =PV * PVR * ASN * CTR2 * ACP
可以看出以上各因子表明了变现系统不同组成的效率
- PV:是百度能够用于变现的流量上限,由用户体验决定,百度越好用,口碑越好, PV越高。该指标在百度类似的搜索引擎公司,主要由搜索部门负责。
- PVR:就是PV中被用于变现的比例,PVR越高,说明在百度搜索中,出广告的概率越高,有可能导致用户体验的下降
- ASN:单次有广告展现的PV,展现的广告数量,表明单次有广告展现时的变现利用程度。ASN越高表明单次搜索出的广告越多,可能导致用户体验的下降
- CTR2:单条广告展现时, 广告北点击的概率。表明广告推的是否精准,是否满足用户需求(至少是感官上是否吸引用户)
- ACP:单次点击价格,相当于单价的高低
这样的指标分解非常有利于指导策略的优化,以下是几个case:
- PV:搜索部门的重要指标,增加下降,都能立刻看出搜索部门的业绩,或是竞争对手带来的影响,例如,就百度而言,Google退出中国PV上升,360上了搜索, PV下降,都能直接看出来
- 点击率预估:假设PV,PVR,ASN,ACP都固定,则要增加收入,需要提升用户对广告的点击率,此时可以用模型来对点击率预估,提升CTR2。各大搜索引擎公司,对CTR2的预估,基本上都是商业部门的重要机密,也是最重视的技术之一
- 增加广告展现:在各上市公司(包括传统行业公司),都会有‘冲业绩’这么一说,就是极度末时,为了达到之前的营收计划,需要使用各种手段增加收入,例如我们经常听说的银行给高利息临时拉存款等,在百度则可以通过调参提升收入,比如增加ASN或是PVR,达到收入符合华尔街预期的效果
- ASN的变化:如果收入的增长是来自于ASN的增长,则说明百度的点击卖得更贵了,广告主会不乐意。相反,ASN下降,说明点击卖便宜了,百度的收入有可能降低,所以类似于CTR2上升,ASN不变这样的策略,是最好的
有了以上定义即收入的拆解,则收入可以用其他集中形式表示:
Revenue = PV * CPM1
Revenue =PV * PVR * CPM3
Revenue =PV * PVR * ASN * CPM2
Revenue =PV * CTR1 * ACP
Revenue =PV * PVR * CTR3 * ACP
百度商业部门的工作,几乎每天都是在围绕着这些指标来进行的。每一次策略的调整,工作方式的改变,都希望在这些指标上做出正向的贡献,因为这些指标对百度的收入是直接造成影响的。从百度的收入(Revenue)的计算公式上就可以看出(每一种计算方法得到的结果都殊途同归)
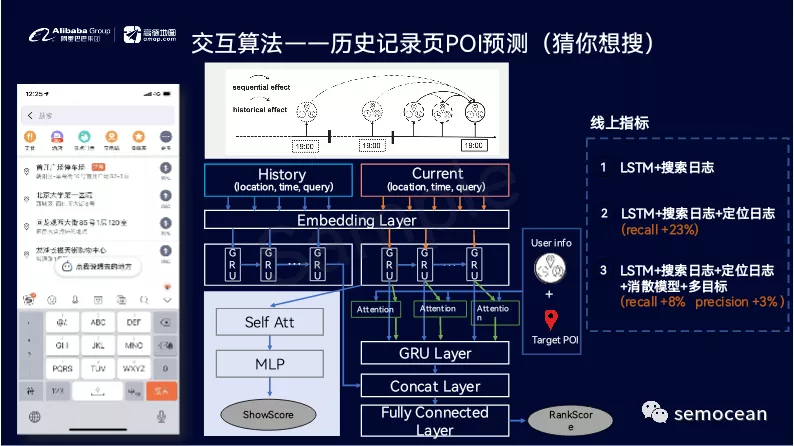
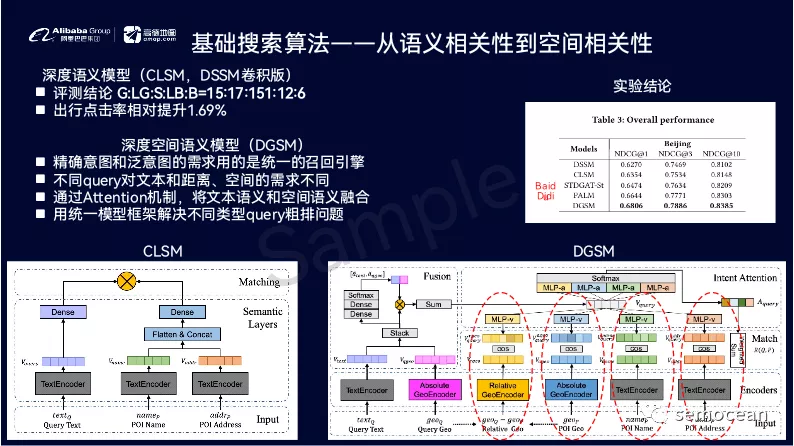
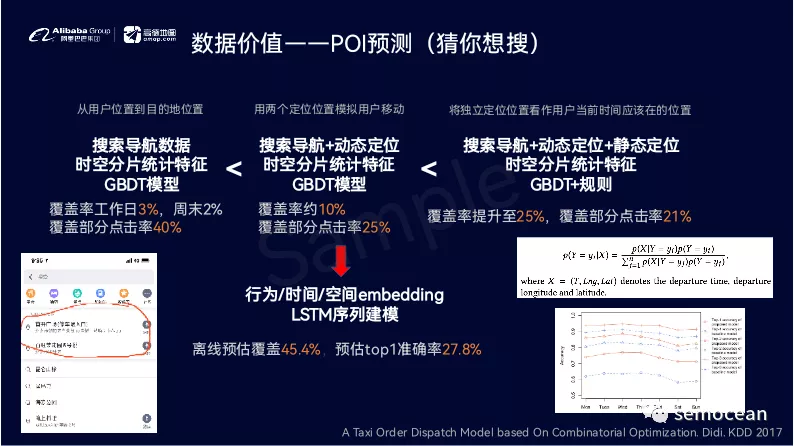
如何建设LBS变现策略指标体系
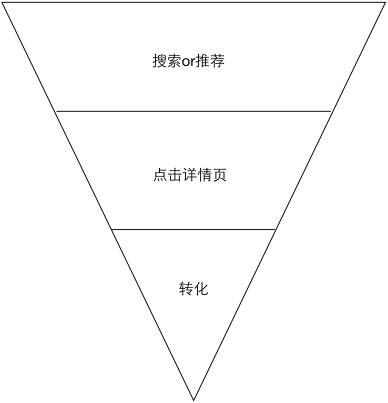
拿百度地图类似的LBS产品为例,假设我们的转化漏斗路径是:推荐&搜索之后展示结果列表也,然后用户点击结果进入店家的表述页面(POI),之后如果用户感兴趣,则点击具体的团购,优惠券进行购买,搜索漏斗如下:
图:搜索漏斗
对应到线上系统,在评估衡量线上系统效果时,我们也需要分为这3阶段进行衡量,以及时发现线上策略效果的瓶颈所在, 快速找到提升重点。在以上3阶段中:
- 搜索or推荐:主要表明流量大小
- 点击详情页: 表现为用户带来的流量到详情页的浏览情况
- 转化:最终转化action
对于商业系统,我们最重要的目标就是保证在既定流量上,转化最高。
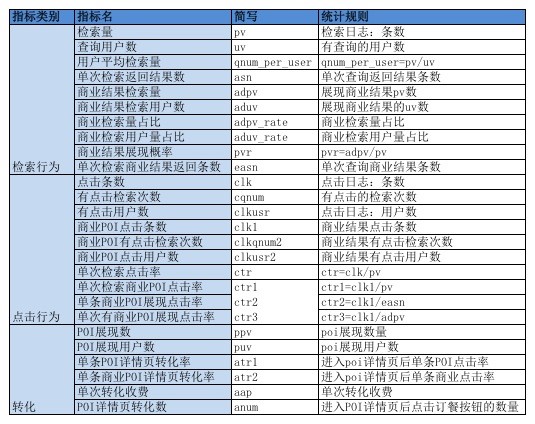
以下为我们需要关注的所有指标:
表:策略效果指标
如后续变现系统按转化收费,则整个LBS变现系统收入可定义为:
收入= pv * pvr * easn * ctr2 * atr2 * aap
在产品的不同阶段,我们需要关注的重点不一样:
- 在产品上线的阶段,我们需要关注用户体验,所以ctr2和atr2需要重点关注
- 用户体验提升到一定程度,商户已经认可我们产品效果时,再考虑提升成单的单价(例如佣金等),同事可以考虑对商业POI进行放量,提升pvr和easn
物料召回及检索类指标
该类指标主要用于监控系统的检索量, 以及系统的召回能力。 检索量等指标是系统变现可以使用的所有资源,更多受用户产品影响;而召回能力相关指标则体现出CPR系统对商业物料的召回能力。
以下为重要指标说明:
- 检索量: 发送到系统的所有请求量;通过统计检索日志条数得到;为能够变现的流量全集。
- 查询用户数:所有发起请求的用户数;统计检索日志中去重后uid得到,体现参与检索的用户量。
- 用户平均检索量:平均每个用户发起的请求数量;体现用户检索角度的活跃度。
- 单次检索返回结果数:平均单次检索返回结果条数; 体现系统的召回能力(准确性参见相关性评估)
- 商业结果检索量:出现商业结果的检索次数;
- 商业结果检索用户数:出现商业结果的检索用户数;体现商业结果能够覆盖的客户群体
- 商业检索占比:出现商业结果检索量占总体检索量占比;可根据改指标分析潜在变现流量。
- 商业检索用户占比:看到商业结果的用户占所有检索用户占比;可根据该指标分析潜在变现用户。
- 单次检索商业结果返回条数:一次出现商业结果的检索,返回的结果条数;
点击行为类指标
该类指标主要用于衡量用户浏览搜索/推荐结果后的点击行为。该过程为转化漏斗第二阶段。
以下为具体指标及含义:
- 点击条数:被点击的POI数量(包括自然POI和商业POI)
- 有点击检索次数:产生点击行为的检索次数(包括自然POI和商业POI)。
- 有点击用户数:产生点击的用户数量。
- 商业POI点击条数:商业POI被点击的数量。
- 商业POI有点击检索次数:出现商业POI,且产生商业POI点击的次数。
- 商业POI点击用户数:点击商业POI的去重用户数。
- 单次检索点击率:平均每次检索点击POI的概率;该值理论上可能大于1
- 单次检索商业POI点击率:平均每次检索,点击商业POI的概率;该值理论上可以大于1
- 单条商业POI展现点击率:平均每条商业POI展现的点击概率;用于衡量每条商业POI曝光产生点击的效率。
- 单次有商业结果展现点击率:平均每次有商业POI展现的检索的点击概率;用于衡量出商业POI的流量产生点击的效率。
效用类指标
该类指标主要用于衡量用户点击进入POI详情页后,根据详情页信息,做出最终决策的阶段(包括点击‘预订’,‘成单’,‘下载’等行为)。该过程处于转化漏斗的第三阶段,也是最终阶段。
以下为具体指标定义:
- POI展现数:包括自然POI和商业POI的展现次数。
- POI展现用户数:浏览POI的去重用户数。
- POI详情页转化数:此处的转化根据每个入口可能有所不同。
- POI详情页转化率:POI详情页转化数/POI详情页展现数。
- 单次转化收费: 完成单次转化后,向商户收取的平均费用。
以上密密麻麻的指标,在不同的商业变现系统中会有所差别,但基本上都是按照用户产品形态及转换漏斗进行设定,而每个策略的上线,都会使用类似的指标体系来衡量策略对不同漏斗部分的效率影响。
更多内容也可参见: http://semocean.com







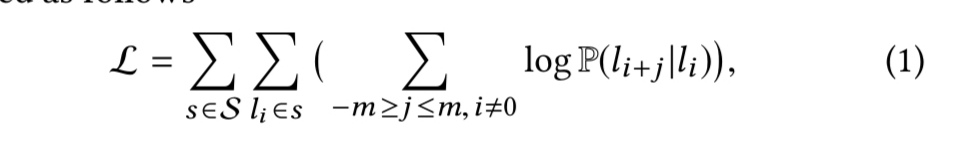
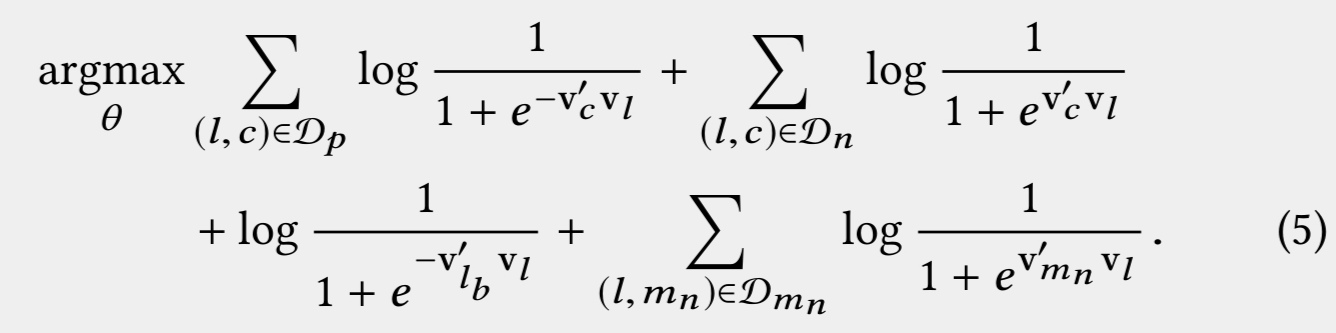

路况.png)
-.png)