real-time personalization using embeddings for search ranking at airbnb
内容简介
搜索排序和推荐系统在类似于网页搜索内容发布等场景都是比较重要的技术,但是很难有统一的技术能够适用于所有的场景。
在爱彼迎的场景中,需要同时满足商家和用户的偏好需求。而且在特定的时间,一个民宿只能接待一位客人。
文中使用embedding技术对list和用户进行建模,以便用在搜索和推荐中。这两个频道带来的转化占了99%以上。并且能做到实时的个性化。从离线和在线的ab test效果都验证比较好。
intoduction
随着数据的增长继续学习,在搜索和推荐中的个性化应用都比较成熟,有很多的发展。有些集中在engagement的优化,有些集中在购买的优化,有些则集中在双边的优化。例如像租房行业中的airbnb打车行业中的uber,都会涉及到供需双方的满足。
airbnb需要满足双边的供应和需求双方包括说客人的预计定酒店地点,日期以及说酒店的一些要求,比如容忍的客户数,是否有宠物,要把不匹配的酒店放在比较低的排序位置。
最后使用的方法是将问题建模成pairwise排的问题,并使用lambda rank方式实现。
在爱彼迎的场景中,一般用户有需求的时候都会在同session中搜索多次,所以我们可以个性化的向用户推荐同一session中用户可能喜欢的item,以及将排序比较高的推荐出来,但没有被点击的item作为负例。
方法:
在具体实现的时候,使用用户有过交互的item作为trigger,使用搜索session的数据训练word representation,并计算与trigger item的相似度,以便在搜索和推荐中作为排序similarity的度量。
兴趣建模方式
- 使用用户近期点击行为作为用户短期的兴趣偏好
- 使用用户预定的行为作为用户长期的偏好
- 因为用户预定的行为会比较稀疏,所以将用户映射到群体使用规则的方式
- User和item都映射到同样一个向量空间,以便计算其相似度
文章的贡献
- 实时个性化:传统的方法是离线计算好user 2 item或者说item 2 item的内容,之后在线去拉倒排,本文使用的方法是将用户即时的交互item embedding化,然后再去查相似的item。做到实时个性化
- 适应具有聚集性的数据的训练模式:在短租市场中,用户一般是在特定的时间,只针对特定的区域有需求,故在训练的时数据的负样本选择需要具有区域性聚集
- 将转化作为全局的内容
- 用户类别embedding:很多文章对每一个用户进行一个embedding,但是在短租市场,用户行为非常稀疏,故将用户的类别进行embedding
- 将用户拒绝作为负例
方法
文中将embedding分成两种,一种是用户实时短期item的embedding,另一种是user type和item的embedding,表征长期实时兴趣。
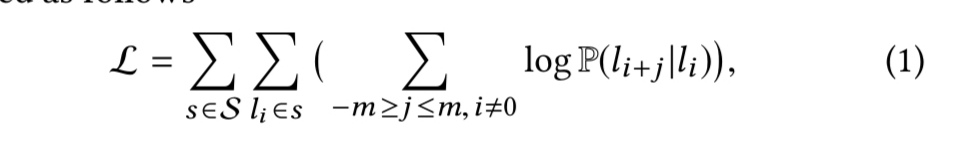
相当于优化每个session中每一个item对应的上下文的概率最大化。
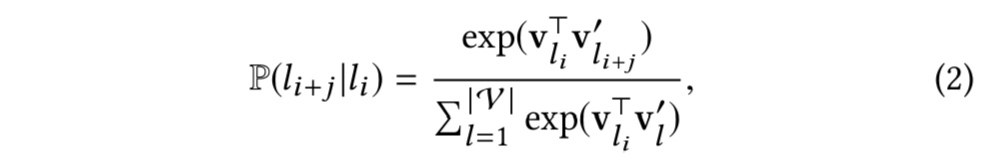
此处的概率是用softmax来表示。
note:以上公式中,m为前后上下文的窗口长度,V为字典大小。使用以上方式,得到的li的representation,在session中越相似,则距离约近。
此处V表示id数量较大,所以使用随机负采样方式来降低数量提升计算的速度。
负采样:
负采样的方法为,使用click和对应session中的上下文作为positive pairs(c,l),以及click和随机采样的上下文作为negative pairs(c,l)进行模型训练。以下为对应的优化目标,其中Dp为positive pairs集合,Dn为negative pairs集合。
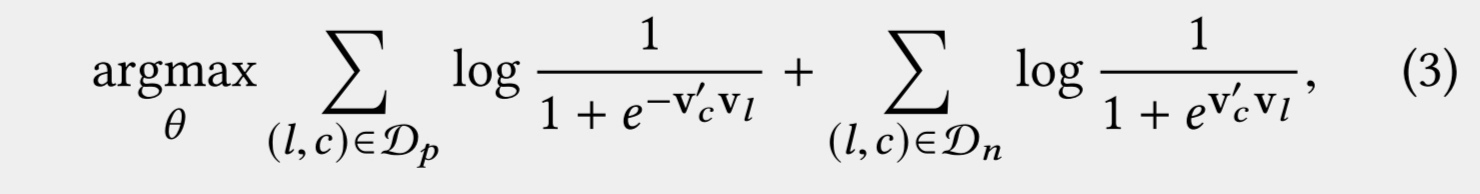
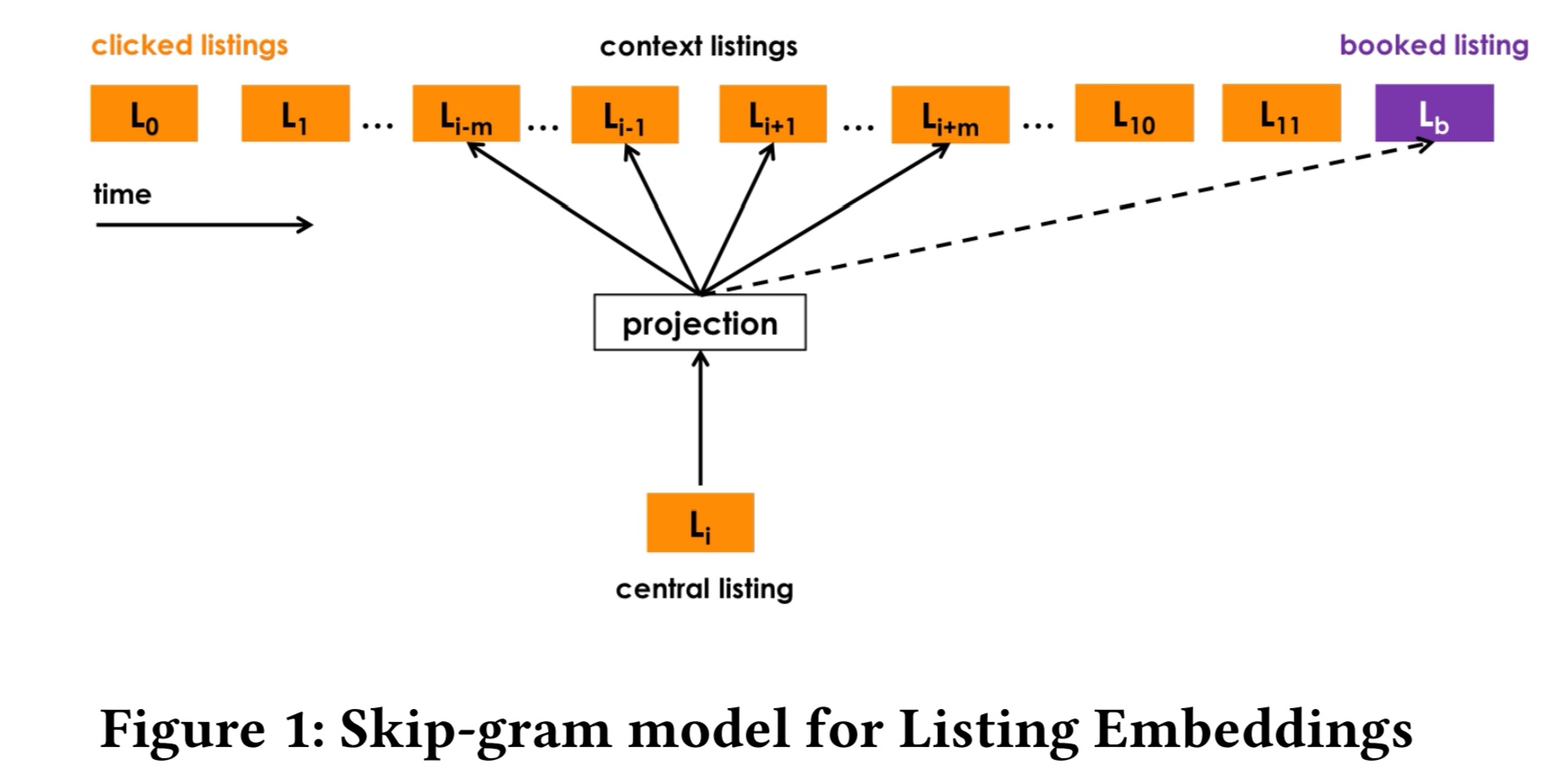
将session分为两种
- 第1种是以完成订单预定的session, booked session
- 第2种是有点击,但没有预定的session,exploratory session
为了让预定作为一个全局的上下文,在每一个booked session中的样本,都强制将预定的item作为结束的item。
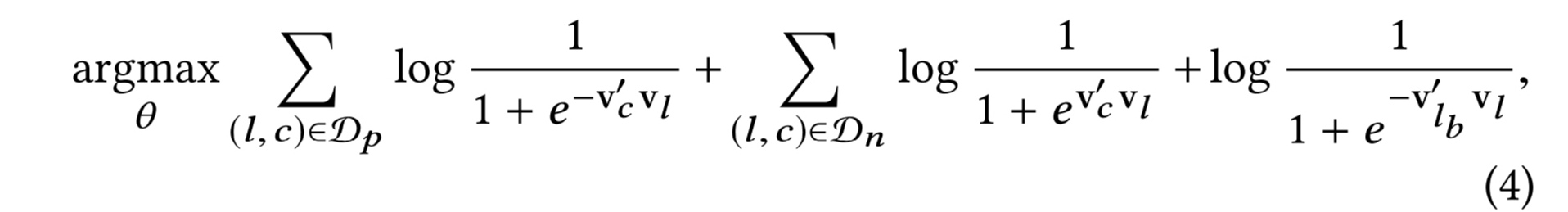
对于exploratory session,则优化目标仍然为公式(3)
Adapting training for congregated search:
以上公式的random sampling会导致random sampling出来的负样本都是和本次搜索地域不一致的结果,最终导致模型学习出来的是区域之间的相关性,为了解决该问题,增加对同区域结果的sampling
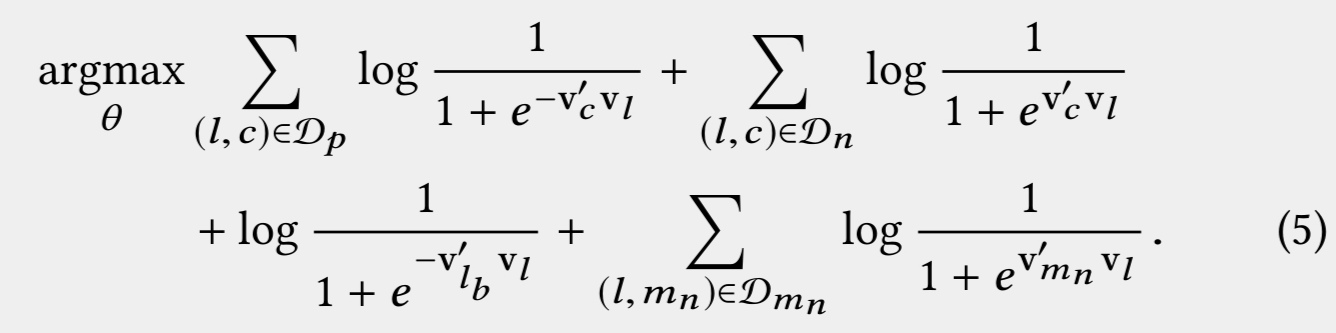
上式中Dmn为在l的同区域中sampling出来的结果
冷启动
新加入的店面没有embedding,此时我们会用距离内的相似民宿的中心点来进行表示,比如说找到半径10英里内,相同price以及相同房型等其他属性相同的三个embedding,然后做一个平均,来表示新的民宿的embedding作为冷启动。用该方法能够覆盖98%的new item。
embedding效果的检验
使用围围度为32的embedding进行表征,发现地理位置的聚类关系的确编码进去了,同时房型价格的信息也编码进去了。
user-type & listing-type embeddings
目的是捕捉用户的长期兴趣。但是存在以下几方面的挑战:
- 数据较为稀疏。
- 很多预定的session长度为1,没法学习。一般出现5~10次才能学习出来。
- 用户预定的间隔很长,可能偏好已经改变了。
具体的实现方式为将用户按照meta信息进行聚类分为人群,将listing/item按照meta信息进行聚类,按照聚类后的群体构建预定session进行训练。相当于学习的对象由原来的list_id,变为list_type
用户的长期兴趣可能会改变,故在具体学习操作的时候,将user和listing映射到同一vector space中进行学习。

构造(u_type1,l_type1)的用户群体,listing群体的点击session,之后进行训练,即可将user和listing映射到相同vector space中
模型训练
以30分钟作为一个session进行模型训练
去除无效的点击,例如点击后在页面时间较短的点击
将session处理为同时包含booking&EXPLORATION的session形式
评估方式
给定用户最近的点击,以及待排序的candidate, 看最终被预定的item是否能够被排上来
线上使用的方式,为使用GBDT模型进行特征组合, 使用user, listing embedding构建各种特征进行模型训练
reference
原论文参见:
https://pan.baidu.com/s/1R8xeb0iRq089myl3oXJlZA 提取码:1j9n
更多内容参见: www.semocean.com
P.S. 急招推荐,搜索,语音算法人才,阿里P6~P8,欢迎推荐和自荐,简历请发至 haibo.lihaibo@alibaba-inc.com