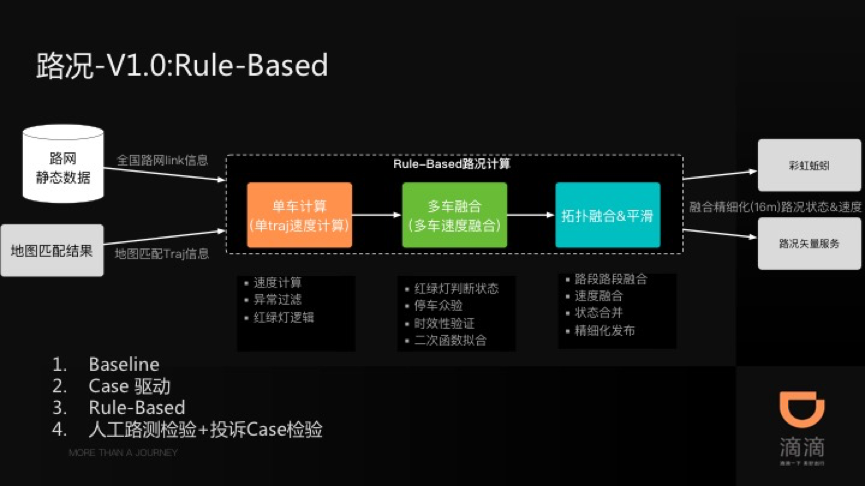
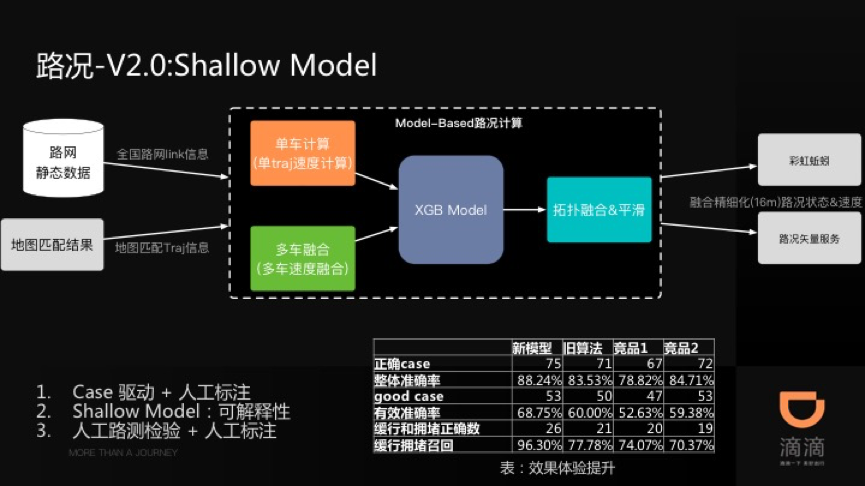
14年之前一直都在做推荐和变现相关的工作,甚至14年入职高德负责高德变现系统时候也是推荐&变现的延伸,但那时已经开始涉及LBS相关的领域,所以可以认为从工作到现在,自己在做的事就是两个方向: 推荐&变现(推荐和变现很多技术比较类似,所以暂且放到一起),以及LBS。今年初入职滴滴负责滴滴地图的部分AI业务后,主要的精力反倒是转到了地图行业,也算是重新回归LBS这个领域,这个过程中也在寻找地图和传统互联网技术(e.g. 推荐&变现)的结合点和爆发点。虽然目前还没找到,但总感觉是可以有明显的创新和爆发点的,原因如下:
- 推荐&变现,变现的主要技术还是纯线上,但现在纯线上流量似乎已经趋于垄断,想玩出花的机会正在变少(当然还还是有很多优秀的公司不断有新的突破,例如今日头条)
- 出行领域市场非常巨大,但涉及面比较广,而且这个行业现在似乎还处于传统行业向互联网转的过程中;相当于人们的刚需,现在并没有得到很好的满足
- 地图更偏传统行业,数据采集,清洗加工流程都比较重工艺和经验流程,中间很多环节还需要人工参与,成本较高,可改造潜力较大
所以想要找到创新的结合点和爆发点,就需要深入了解地图行业的细节。而如上提到:地图行业更偏传统行业,有很多自有的业务和技术需要学习,内容实在很多[4]。正好近期在整理地图行业的一个基本topic:Map-Matching(中文应该翻译为路网匹配,或者简称‘绑路’),所以就在此记录下这个方向的技术供自己备忘,也有利于同行参考。
Map-Matching背景介绍
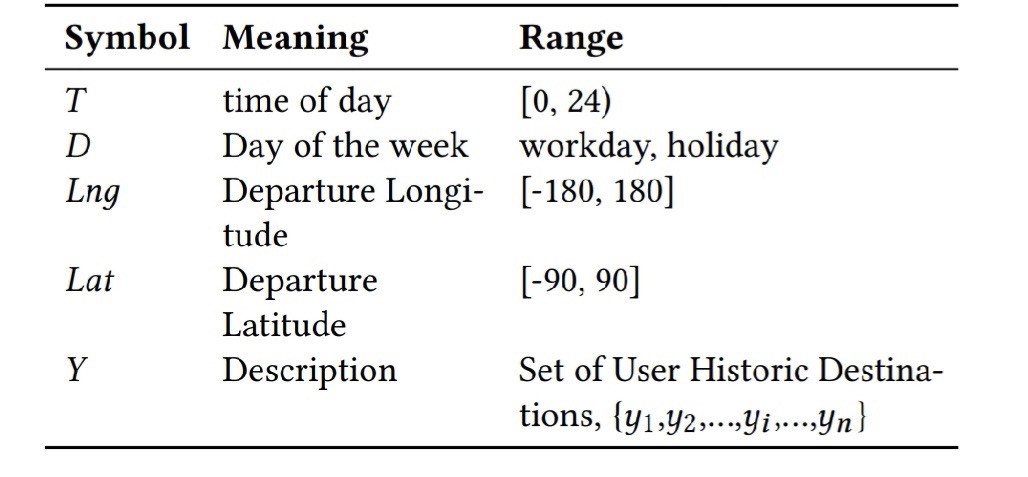
一般LBS场景,最基础的数据有三种类型:路网数据, 用户(司机 or乘客)GSP数据,以及用户在产品中的交互数据。其中路网数据包括道路,POI点以及挖掘出来的描述静态物理世界的数据,用户在产品中的交互数据此处比较笼统,可以包含用户的静态Demographic和用户在产品中的使用习惯数据,而本文的重点相关的是第三类数据,即用户的GPS数据。
目前智能手机都集成有GPS芯片,能够间隔一定时间(例如1s)采集一次GPS定位信息, 该信息包括GPS横纵坐标,精度,速度,在各方向加速度等信息,因为采集周期较短,持续时间较长,故在用户量较大的应用中,该数据的规模会非常大,但也是最丰富的采集数据之一。而且该数据是对用户在物理世界时间空间最直接的描述,所以能够挖掘的信息非常丰富。
但问题来了,GPS点采集的时候因为卫星信号的强弱,或是设备周围信号受到干扰(例如有高楼),特别是民用GPS本来就会有误差,导致最后这些数据的漂移在几米到几十米不等,这样就会导致我们采集到的点都是有随机漂移的点,并不能完全反应用户真实的位置。而对于类似于高德,百度,滴滴的地图场景,我们需要知道车辆到底是以怎样的轨迹行驶,在什么时候行驶在什么路上。此时Map-Matching就是LBS服务较为基础的技术,因为它将不精确的用户轨迹点序列映射到确定的路网上。如下图示例:
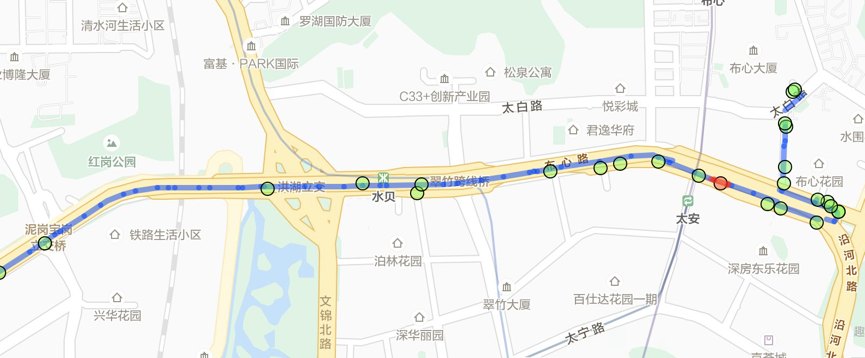
图:MM示意,其中绿色点为GPS点,蓝色线为map-matching结果,可见GPS点存在飘逸,特别是道路比较密集的场景
虽然理论上GSP点的漂移为10米以内,但在实际应用场景中因为天气,周围环境(高楼,树木,卫星数量等)可能导致的GPS点偏移最高可达数十米,而对于城市中密集的路网来说, 数十米的漂移将会导致map-matching的错误概率大大增加。
而同时map-matching又是很多GPS/Trajectorys挖掘的基础(例如如何挖掘用户出行模型,如何对人流,交通进行建模等),所以map-matching是一个即基础,又重要,且具有较大挑战的基础研究应用方向[1][4]
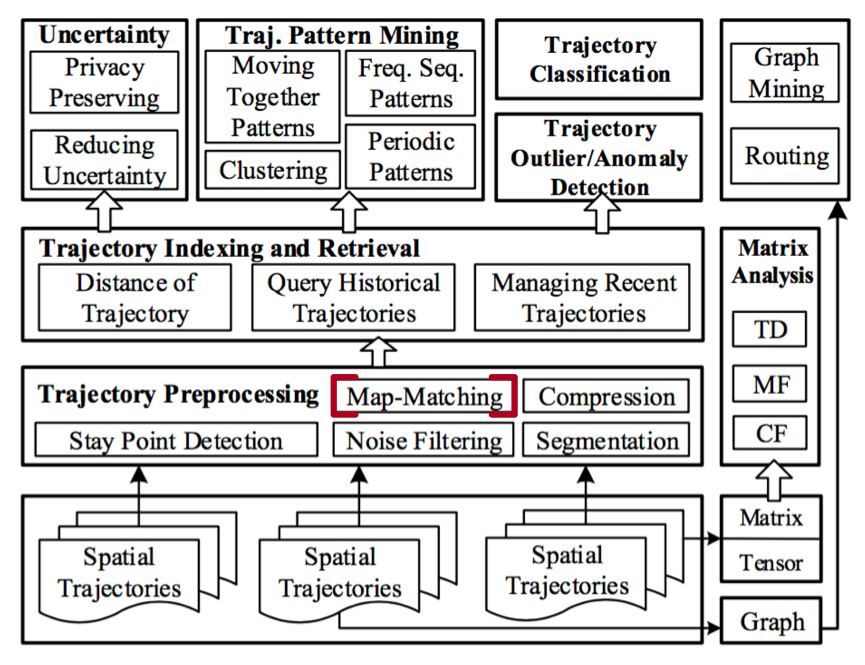
图:Map-Matching在用户GSP/Trajectory Mining体系中的位置[1]
下文就对当前常用的map-matching算进行介绍,并对后续可能的研究方向进行分析阐述。
Map-Matching算法及挑战
那Map-Matching具体是什么,通俗来讲就是绑路(或者路网匹路),就是将收集到的同一用户(例如高德,百度地图或者滴滴地图司机)在时间空间维度的一系列存在精度损失的GPS点,匹配到最有可能的地图路网具体道路上。
但这个过程存在以下难点及挑战:
- GPS点存在精度损失(或漂移),精度损失在十米~数十米不等
- 城市道路密集,在小范围内可能存在较多道路
- 很多道路间距较小且平行(例如主辅路),或者主路出辅路的交叉口, 这些路上的GPS点甚至从统计的角度都看不出明显规律;或者存在垂直空间重合的路(例如路面和地下隧道平行)
以上都是map-matching在实际计算过程中的挑战,而且很多到现在都没有解决好,也没有很好的思路。
同时学术界和企业的研究关注点是不一样的,学术界主要基于公布的开源数据进行研究,这些数据有以下几个特点:
- 数据量较小
- 数据单一,一般除了GPS点外,没有其他数据可用
- 路线相对单一
- 对结果的精度要求相对不高(部分场景)
Map-Matching在滴滴的挑战
但企业就不一样,例如滴滴,和学术界研究的Map-Matching比起来,以下是主要的区别:
- 数据量非常大,每天几千万订单,汽车行驶过程中每秒或者每3秒一个GPS点,同时还有合作伙伴的数据;数据量大就会对实时处理性能,以及离线挖掘的数据处理能力提出挑战
- 大城市中路线比较复杂,道路比较密集
- 对精度要求非常高,甚至需要根据map-matching结果按照里程决定司机的收入,如果map-matching错误,不仅仅会影响到用户体验,还会导致司机或者滴滴平台的损失。例如绑路错误会直接导致平台判定司机行驶路线错误,导致计费错误。涉及到钱的,大家都异常关注和敏感
Map-Matching常用算法
Nearest Neighbor
该方法只是理论般的存在,在现实中根本无法使用, 因为精度太低。思路比较直观:直接计算对应GPS点和候选道路的投影距离,将GPS点匹配到最近的候选道路上。理论上可行,但具体应用的时候,因为城市道路比较密集,且GPS点存在较多漂移,故该方法不可用。一般甚至不会将该方法作为baseline。
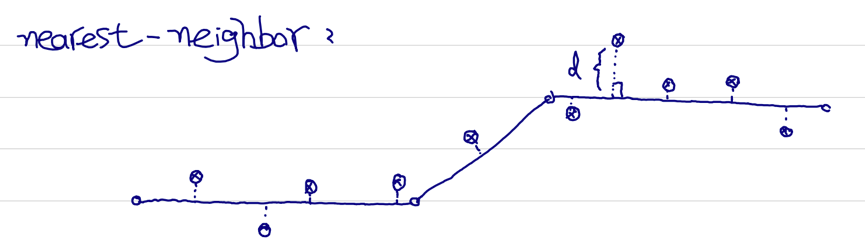
图:nearest-neighbor方法,GPS点直接绑到投影距离最近的道路上
HMM
地图匹配中比较经典的方法是使用隐马尔科夫模型(HMM)来实现,该方法的使用方式主要来自于论文[2]。该论文2009年公开发表。目前国内几个互联网地图公司的map-matching算法实现的基本思路基本上都来源于该论文。该论文使用HMM对地图匹配过程进行建模,将匹配的概率分解为观察概率及转移概率的综合结果。
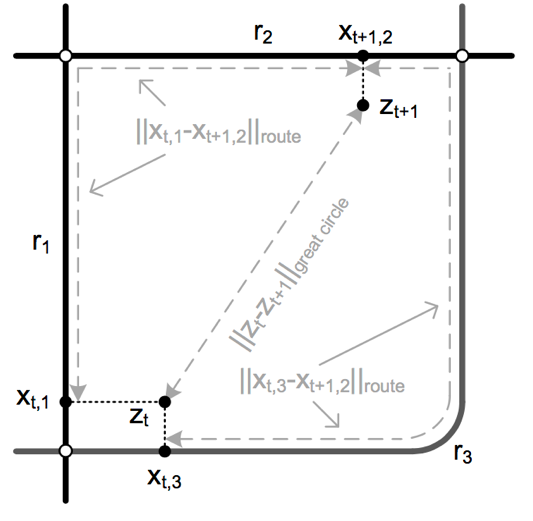
图:有r1,r2,r3三条候选link,两个gps点zt,zt+1,假设zt在r1,r3上的投影分别为xt,1,xt,3,zt+1在r2上的投影为xt+1,2,则该方法的核心思想为:route距离和greate circle距离越小,则可能性越大。此处greate circle为zt到zt+1的球面距离,route距离为假设汽车在某条route上行驶所产生的距离,例如途中的|xt,1-xt+1,2|_route和|xt,3-xt+1,2|_route
在此思路框架下,对观察概率(或叫Measurement probabilities,或emission probabilities),以及转移概率(transition probabilities)进行建模,建模方式如下:
观察概率:可以将观察概率建建模成mean为0的高斯分布

图:观察概率建模
其中gc表示为great circle的缩写,表示两点球面上的最短‘直线’距离。其内在含义就是, 如果点zt离ri的球面‘直线’距离越近, 则从观察的角度我们认为zt更有可能在ri上
转移概率:我们假设两个gps点zt,zt+1的距离和对应在道路上的投影点间的路径规划距离(route plan distance)的偏差越小,则说明汽车更有可能在沿ri,到rj的route上行驶(试验也证明这个假设是正确的)
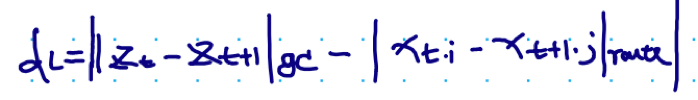
图:转移概率:great cicle距离和route距离差值较小的绑路结果更有可能为真实的绑路结果
有了观察概率和转移概率后,使用维特比算法进行求解
具体涉及到观察概率中高斯分布中的方差,可以使用真值ri和zt的投影距离的Mean Absolute Deviation(MAD)进行参数估计
另外在线上系统使用中,为了保证算法的效果,一般会对数据进行预处理,包括但不限于:
- 寻找候选道路时,会仅将观察gps点zt一定半径范围内的link作为潜在的可能link,该半径以外的link将直接将观察概率设置为0。论文[2]中建议的半径范围为200M,但在实际使用中(例如滴滴的使用场景),该半径值会小很多, 因为滴滴的场景更偏城市,路网更加密集,且每秒需要并行处理的量比学术界高很多量级,故候选link搜索半径更小
- Route Plan距离和Greater Circle距离差超过阈值的后续link也会被直接置为概率为0, 其中的思想是我们认为这两个值比较相关, 偏差不可能太大
- 使用Route Plan距离,以及两个观察点zt+1, zt的时时间差计算出来的行驶速度大于阈值的route,也认为不可能成为候选link,例如计算出的行车速度超过150km/h
在该HMM算法框架下,能够衍生出很多的变种,它们中大部分都是围绕着如何引入更多的信息来对转移概率进行更精准的建模展开了,例如可以在转移概率中不仅考虑greate circle 和route plan distance的差值,还引入转弯次数作为影响因子[3]提升整体算法的效果
HMM+Shallow Model
从数据特征
HMM虽然是经典的map-matching算法,并且和其他算法相比效果上也有优势,但该算法框架下很难引入更多维度的丰富特征提高地图匹配的准确性。例如GPS点其实有很丰富的数据,例如点速度,点方向, gps点的精度;点和候选道路也有较多可以提取的信息, 例如投影距离,是否超速,是否逆行; 另外还可以加入路网特征,包括道路等级, 限速, 车道数等;最后也可以引入HMM中使用的转移概率等信息。以上信息均可以作为模型的输入。
Lable
地图匹配和路况发布一样,有一个最有挑战的问题就是真值的获取。
现在一般有三种方法来获取真值
- 人工标注:如果要使用模型, 那至少需要标注几百万的点(我们真的人工标注了几百万的点, 是不是觉得比较汗。。), 耗时耗人
- 规则选取:可以通过对已经发生完整轨迹,使用规则判定轨迹中间的部分的绑路结果,例如轨迹中间某段不能确定是在主路, 还是辅路, 但根据后来的轨迹方向可以确定(比如辅路有右拐但主路执行,且轨迹右拐,则说明之前的行驶点是在辅路上而非主路)
- 图像+ gps: 使用行车记录仪的图像,确定该图像对应的GPS点所属的道路
模型
使用一般的分类模型即可进行学习, 例如FM或者FFM
因为引入了更丰富的特征,故HMM+Shallow Model的方式效果一般都比HMM要好。我们的试验中,绑路准确性能够提升3.5%
近些年深度学习是模型算法的趋势,但该处我们并没有使用深度学习来解决该问题,主要的原因还是因为真值label获取相对困难,量级没上去,后续随着规则选取及图像的自动化label获取流程打通,成本降低后,会使用LSTM等时间序列模型来提升效果
IRL Map-Matching
学术界还有一类算法来提升Map-Matching ,就是使用强化学习[3]。其思路还是将Map-Matching问题建模为HMM,仍然是将最终的概率分解为观察概率(Measurement Probability)及转移概率(Transition Probability),只是具体操作的时候有以下两个变化:
- 计算转移概率的时候,不仅仅使用greate circle 距离和route plan距离的差值计算转移概率,同时引入转弯的信息计算转移概率
- 计算转弯概率权重的时候, 使用max entropy IRL进行参数估计。
作者号称该方法能够将error rate降低40%(impressive,但是我没尝试过)
Map-Matching后续研究方案
滴滴每天有接近3KW个订单,每个订单都能产生较多GPS数据,故在滴滴,Map-Matching的挑战主要有以下几个:
- 数据量巨大,需要在效果和性能间做tradeoff,甚至考虑到map-matching性能,我们会在客户端上使用简单算法进行地图匹配,只有等到客户端地图匹配置信度较低的时候,才请求后台服务
- 真值数据的缺失:人工标注始终成本比较高,而且准确性没有保障,故,如何使用多元数据获取map-matching的ground-truth也是一个挑战。 例如使用行车记录仪图像作为map-matching的真值标注
另外地图匹配处理的数据天然就是一序列的GPS点信息,故从处理算法的角度,比较适合使用时间序列模型来进行处理。目前我们也准备将底层的处理逻辑由原有HMM+Shallow模式向时间序列模型进行迁移。
Reference
- Zheng Y. Trajectory Data Mining: An Overview[M]. ACM, 2015.
- Newson P, Krumm J. Hidden Markov map matching through noise and sparseness[C]// ACM Sigspatial International Conference on Advances in Geographic Information Systems. ACM, 2009:336-343.
- Osogami T, Raymond R. Map matching with inverse reinforcement learning[C]// International Joint Conference on Artificial Intelligence. 2013:2547-2553.
- eta技术:http://www.semocean.com/lbs%E5%B7%A5%E4%B8%9A%E7%95%8Ceta%E5%BA%94%E7%94%A8%E5%8F%8A%E6%BB%B4%E6%BB%B4wdr%E6%8A%80%E6%9C%AF/
更多内容也可参见: http://www.semocean.com


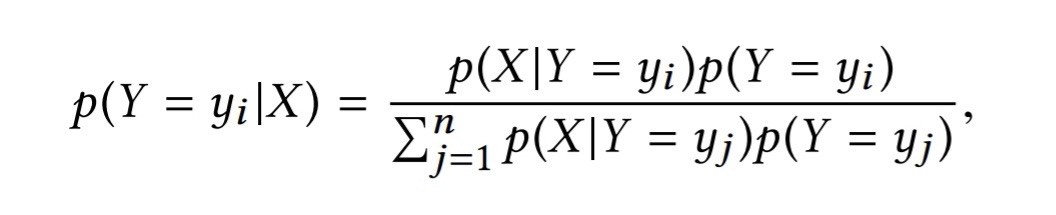
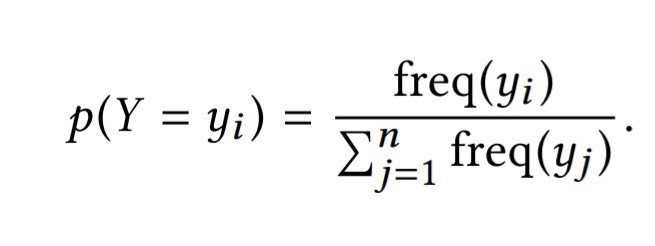



路况.png)
-.png)