亚马逊semantic product search
网上一直有一种说法,就是在Google的工程师非常鄙视亚马逊的工程师,觉得他们技术不行,Google的技术比较牛叉,但是很多业务场景Google就是做不过亚马逊,最典型的就是云计算市场,Google的市场份额还不如阿里,更别说亚马逊的老本行电商。而亚马逊也一直奉行简单有效为客户服务的原则推进业务。 例如这篇论文中描述的亚马逊电商product search,技术比较简单,没有很高端复杂的模型,但大家在工业界的实践中是可以作为参考的,是一种简单有效的语义搜索方法。该论文发表于2019年KDD大会,下边的内容更多是一个论文的笔记,作为一个备忘,大家最好参考原论文一起阅读。
基于字面匹配的缺点
- 第一上下位同意反义处理不好,例如语义的泛化(hypermyms),同义词(synonyms),反义词(antonyms)
- 第二形态学变换处理不好,比如说woman and women
- 第三拼写错误处理不好。
本文提出的语义方法解决问题的思路:
- 第一是loss function处理正负样本
- 第二是针对average pooling和ngram捕捉语法的pattern
- 第三是使用哈希处理字典中不存在的单词的问题OOV,应对0次学习问题
- 第四是进行了并行优化。
本文面临的场景是用户的行为数据量非常多,但是有噪音,同时用户在搜索的时候,是针对某一个比较窄的领域进行搜索,在这个过程当中还需要兼顾发现性。
模型
本文使用的模型的主要特点
- 第一是使用embedding方式将query,product映射到相同的空间
- 第二是生成embedding之后,使用average pooling的方式将embedding压缩到相同的维度。之所以能够用average pooling主要的考虑有两点(没有使用RNN的原因)
第一是query和product都比较短,没有太强的持续依赖的关系
第二是query一般都包含在product之中。同时因为quarry比较短,所以将query和product映射到同一空间中,无需额外参数
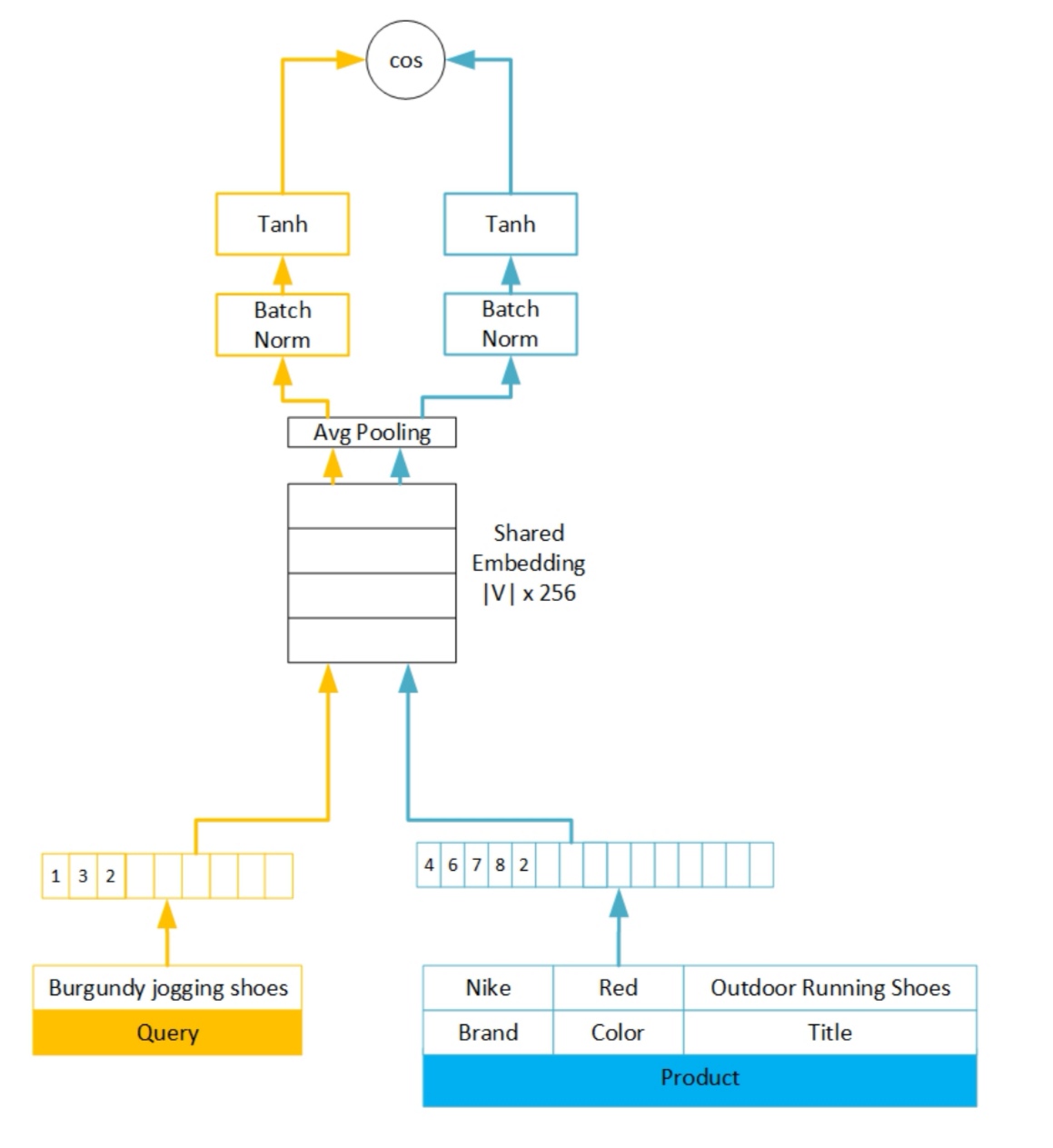
图:模型示意图
Loss function
使用pointwise 3阶段hingle loss作为lose function

相当于综合考虑了样本的三种情况:
- 第一正样本为用户购买的product
- 第二就是用户看到了(impressed),但是没有购买的结果
- 第3种是随机采样出来的结果作为副样本
相当于将label分成三种,三种有不同的域值,使用hingle loss方式进行建模
tokenization methods
本文使用不同维度的力度的embedding对query, product进行表达.主要分为以下几种:
- word unigram:基于单词的unigram
- word n-gram:用来捕捉PHRASE信息,以及对应的附属信息,例如用户如果买的是iPhone手机壳跟iPhone手机其实是不一样的,使用n-gram可以捕捉该类信息
- character trigram:用来捕捉拼写错误信息或者像size型号之类似的信息
同时文中使用harsh trick来解决embedding没有表达到生僻词的情况。
最后在应用的时候,作者将所有的tokens组成一个bag of tokens,之所以能够那么做而没有考虑持续的原因,是因为query和product的title一般都相对较短,用这样的方式其实也能表达序列的关系,而不用用到rnn这样的模型。实验证明不用rn效果的影响也不大。
note:对于OOV的部分(word, n-gram, char-trigram)则使用hash trick的方式进行处理,将query, product中相同的部分映射到相同的bin中(参见图5)
该方法的好处,一方面能够保证高频的元素都能够找到,另一方面,query和product中OOV的元素都能够映射到相同的部分。

data
使用11months的search logs作为训练数据, 使用1month作为evaluation。
文中使用用户数据来进行模型的训练使用和query和products的counts作为权重。
在构造样本的时候,一个query之下有6个impression的product和7个random的products和一个有购买的products。
实验指标
matching:抽取20k个query,看从100万的语料库里边能召回多少购买的products。
ranking:主要看NDCG,mrr。
Result
设置:文中固定dimension为256,batch size=8192,adam作为优化算法。。。
结论:
- L2比L1正则更好,原因可能是L2对于cosine计算相似度的情况下,对于outlier更加泛化
- 效果 3 part > 2 part loss
- average pooling效果优于gru/lstm,猜测可能是因为该场景中序列长度较短,RNN的效果没有发挥出来
- tokenization算法中,unigrams+bigrams+char trigrams算法效果最好; 增加OOV在保证参数不变的情况下效果更好


后续:借鉴意义
在后续推荐业务中存在的借鉴意义如下:
poi2poi embedding表示:计算可以使用该方法对搜索业务中 query-点击poi数据进行embedding,获取poi embedding,计算i2i
tag2tag embedding表示:将tag作为token,使用搜索数据进行训练,得到tag和poi在同一空间中的embedding表示
poi属性2poi的embedding表示
reference
原论文参见:
复制这段内容后打开百度网盘手机App,操作更方便哦 链接:https://pan.baidu.com/s/1VITC73pw9fURLJ-K_7Kb3g 提取码:4h43
更多内容参见: www.semocean.com
P.S. 急招推荐,搜索,语音算法人才,阿里P6~P8,欢迎推荐和自荐,简历请发至 haibo.lihaibo@alibaba-inc.com