本文将介绍epoll的概念,原理, 优点,及使用接口,同时结合作者在搜索引擎spider开发中epoll使用方式的代码向大家具体介绍epoll的使用方式。
P.S. 笔者08年曾有使用epoll编写未考虑压力控制的crawler,将国内著名票务网站(艺龙)压垮并在boss的带领下登门道歉的经历:) 足见epoll的强悍!
epoll是什么
按照man帮助中的说明,epoll是为了高性能处理处理文件句柄而改进的poll机制, 和其类似的功能是select调用。epoll提供相对简单的接口, 即能实现高效的数量巨大的文件句柄的操作和控制。 是select和poll的升级替代品。
select也可以管理调度数量众多的文件句柄,但一般select能够管理的文件句柄数为2048(受FD_SETSIZE定义大小的限制), 虽然可以通过修改linux内核代码调整,但因为其实现为轮询机制,所以在当文件句柄较多,而有事件的句柄较少的情况下select的性能会较低(当然,我个人觉得最大的问题,还是文件句柄数的限制), 当然,很多早期的搜索引擎spider,很多都是直接使用select,调度网络句柄,性能也还不错,比如
larbin而在操作系统实现中,epoll是通过callback回调函数来操作active的文件句柄,所以该调用不用像select或是poll一样需要线性扫描,所以epoll效率较高(当然,如果操作的文件句柄都是活跃的,那select/poll的性能类似),而且epoll能够管理的文件句柄数非常多,一般是系统能够管理的文件句柄的上限,况且epoll通过epoll_create,epoll_ctl,epoll_wait即能完成文件句柄的管理, 所以很多时候epoll系列的接口会成为管理大量文件句柄的机制的首选。
epoll的优点
其实上文已经提到了很多,综合起来,主要是以下两方面有点:
- 高效: 在大量文件句柄管理中,如果active的文件句柄较少,则效率较select/poll高
- 量大: 理论上能够管理操作系统最大文件句柄数的句柄
当然,在实际中,在一些benchmark中,如果绝大部分文件句柄/socket都active,则epoll的效率相较select/poll并没有什么优势,相反, 如果过多使用epoll_ctl,效率相比还有稍微的下降。但是一旦使用idle connections模拟WAN环境,epoll的效率就远在select/poll之上
另外,能够管理的文件句柄数也不可能达到最大句柄上限,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
epoll的使用
首先要介绍epoll相关的数据结构。
epoll用到的有函数都是在头文件sys/epoll.h中声明:
typedef union epoll_data { void *ptr; int fd; __uint32_t u32; __uint64_t u64; } epoll_data_t; struct epoll_event { __uint32_t events; /* Epoll events */ epoll_data_t data; /* User data variable */ };
结构体epoll_event 被用于注册所感兴趣的事件和回传所发生待处理的事件,其中epoll_data 联合体用来保存触发事件的某个文件描述符相关的数据,例如一个client连接到服务器,服务器通过调用accept函数可以得到于这个client对应的socket文件描述符,可以把这文件描述符赋给epoll_data的fd字段以便后面的读写操作在这个文件描述符上进行。epoll_event 结构体的events字段是表示感兴趣的事件和被触发的事件可能的取值为:
EPOLLIN :表示对应的文件描述符可以读; EPOLLOUT:表示对应的文件描述符可以写; EPOLLPRI:表示对应的文件描述符有紧急的数据可读; EPOLLERR:表示对应的文件描述符发生错误; EPOLLHUP:表示对应的文件描述符被挂断; EPOLLET:表示对应的文件描述符有事件发生;
函数接口如下:
函数声明:int epoll_create(int size)
该函数生成一个epoll专用的文件描述符,其中的参数是指定生成描述符的最大范围 2、epoll_ctl函数
函数声明:int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)
该函数用于控制某个文件描述符上的事件,可以注册事件,修改事件,删除事件。
参数: epfd:由 epoll_create 生成的epoll专用的文件描述符;
op:要进行的操作例如注册事件,可能的取值:
EPOLL_CTL_ADD 注册、EPOLL_CTL_MOD 修改、EPOLL_CTL_DEL 删除
fd:关联的文件描述符;
event:指向epoll_event的指针;
如果调用成功返回0,不成功返回-1
函数声明:epoll_wait
epoll的工作模式
epoll有两种工作模式,ET模式与LT模式。
LT是缺省的工作方式,并且同时支持block和no-block socket;在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的fd进行IO操作。如果你不作任何操作,内核还是会继续通知你的,所以,这种模式编程出错误可能性要小一点。传统的select/poll都是这种模型的代表。 ET是高速工作方式,只支持no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过epoll告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,直到你做了某些操作导致那个文件描述符不再为就绪状态了。但是请注意,如果一直不对这个fd作IO操作(从而导致它再次变成未就绪),内核不会发送更多的通知。 ET(Edge Triggered)与LT(Level Triggered)的主要区别可以从下面的例子看出:
例子:1. 标示管道读者的文件句柄注册到epoll中;2. 管道写者向管道中写入2KB的数据;3. 调用epoll_wait可以获得管道读者为已就绪的文件句柄;4. 管道读者读取1KB的数据5. 一次epoll_wait调用完成
如果是ET模式,管道中剩余的1KB被挂起,再次调用epoll_wait,得不到管道读者的文件句柄,除非有新的数据写入管道。如果是LT模式,只要管道中有数据可读,每次调用epoll_wait都会触发。 另一点区别就是设为ET模式的文件句柄必须是非阻塞的。
搜索引擎spider中的使用示例
功能描述
此处的spider,是一个具体而微的应用,或者更应该定义为crawler,即定向快速抓取指定网站,例如我们已经获取到1KW个URL,需要再1天内江1KW的URL对应的网站,使用单机抓取下来。
更具体地,笔者当时的应用场景,是快速地检查指定URL list对应的网站是否能连通, 所以具体操作的时候,仅抓取网页的头部信息, 并返回其中的return status即可, 因为一开始没有spider设计的经验, 所以该crawler一开始没有考虑同一网站的压力控制, 而epoll过去强悍,导致QA线下测试该crawler时,就将国内著名票务网站压垮(据票务网站的同事说, 他们的服务器CPU过热自动重启,而刚完成重启,就。。。又挂了: ),也算是工作后的一个奇遇了。 当然, 这样的CASE在如今,能够很容易被检查出来是一场攻击而被直接封IP。
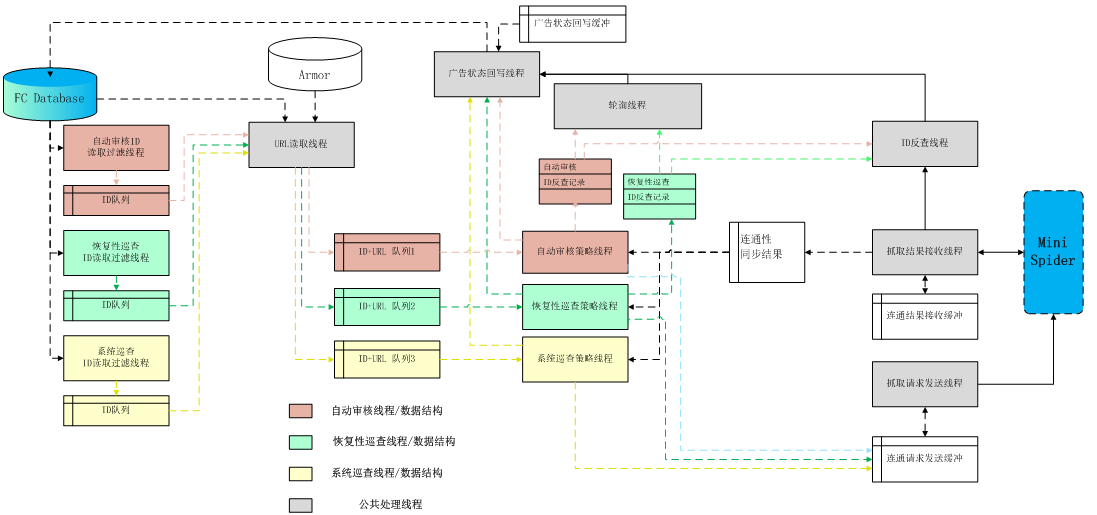
架构
因为是一个简化的spider,所以架构图和下图类似(精确的架构图涉及泄密不再贴出来):
性能考虑
假设20个线程,每个线程最多管理50个socket, 假设抓取超时时间为10秒(一般会比这个时间长),假设不考虑压力控制,则该crawler每天能够抓取 20 * 50 * 86400 / 10 = 8640,000个网页,单机。如需要更强悍的抓取能力, 考虑使用多机。
代码示例
因为代码较多,此处仅贴出涉及到epoll工作原理的代码部分。
图: epoll_create,创建epoll的fd,其中_max_sock_num指定最大管理的socket数量
图: 将socket加入epoll机制: 创建非阻塞fd,并将非阻塞fd加入epoll管理(初始的fd不响应读消息)
图: 使用epoll_ctl设置fd的状态,请参见上图设置读消息机制理解
图: epoll_wait调用方式: 如果active的socket数量不为0,则分出错,断开,读,写状态进行对应处理。
更多实现参见该文附件代码: contm_connector.cpp, 该代码在实际项目中应用,因用到了自行开发的日志库等外部lib,故不能直接编译,但逻辑经过测试,所以参考性较强。
具体代码参见: http://pan.baidu.com/share/link?shareid=2373459832&uk=1493671608
更多内容参见:
epoll 使用说明: http://www.xmailserver.org/linux-patches/nio-improve.html
或是直接访问: http://semocean.com