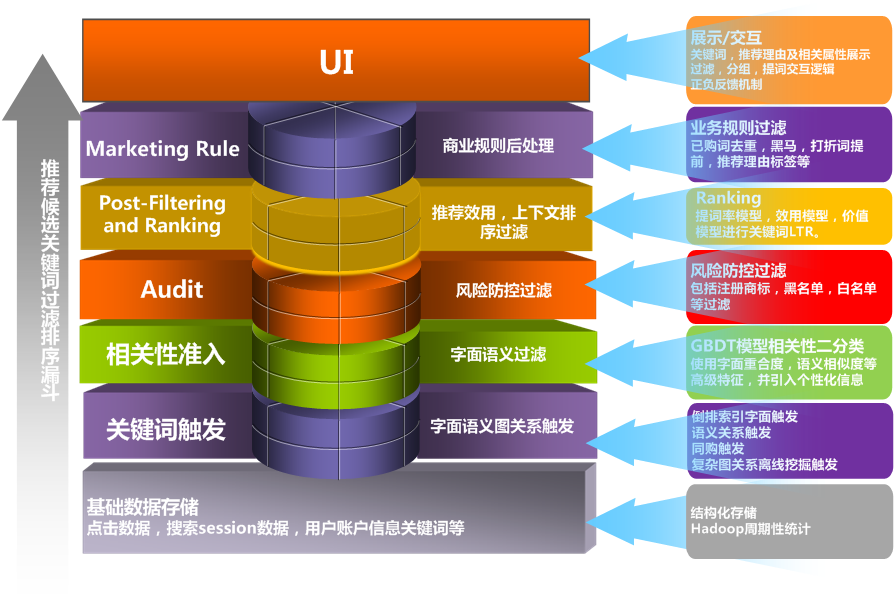
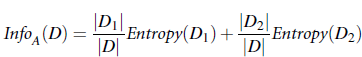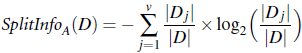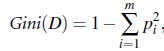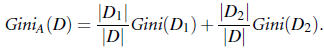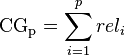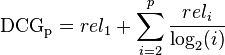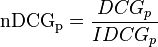使用机器学习方法解决问题时,有较多模型可供选择。 一般的思路是先根据数据的特点,快速尝试某种模型,选定某种模型后, 再进行模型参数的选择(当然时间允许的话,可以对模型和参数进行双向选择)
因为不同的模型具有不同的特点, 所以有时也会将多个模型进行组合,以发挥‘三个臭皮匠顶一个诸葛亮的作用’, 这样的思路, 反应在模型中,主要有两种思路: Bagging和Boosting
Bagging
Bagging 可以看成是一种圆桌会议, 或是投票选举的形式,其中的思想是:‘群众的眼光是雪亮的’,可以训练多个模型,之后将这些模型进行加权组合,一般这类方法的效果,都会好于单个模型的效果。 在实践中, 在特征一定的情况下,大家总是使用Bagging的思想去提升效果。 例如kaggle上的问题解决,因为大家获得的数据都是一样的,特别是有些数据已经过预处理。
以下为Data Mining Concepts and Techniques 2nd 中的伪代码

基本的思路比较简单,就是:训练时,使用replacement的sampling方法, sampling一部分训练数据k次并训练k个模型;预测时,使用k个模型,如果为分类,则让k个模型均进行分类并选择出现次数最多的类(每个类出现的次数占比可以视为置信度);如为回归,则为各类器返回的结果的平均值。
在该处,Bagging算法可以认为每个分类器的权重都一样。
Boosting
在Bagging方法中,我们假设每个训练样本的权重都是一致的; 而Boosting算法则更加关注错分的样本,越是容易错分的样本,约要花更多精力去关注。对应到数据中,就是该数据对模型的权重越大,后续的模型就越要拼命将这些经常分错的样本分正确。 最后训练出来的模型也有不同权重,所以boosting更像是会整,级别高,权威的医师的话语权就重些。
以下为Data Mining Concepts and Techniques 2nd 中adaboost伪代码:

训练时:先初始化每个训练样本的权重相等为1/d d为样本数量; 之后每次使用一部分训练样本去训练弱分类器,且只保留错误率小于0.5的弱分类器,对于分对的训练样本,将其权重 调整为 error(Mi)/(1-error(Mi)) ,其中error(Mi)为第i个弱分类器的错误率(降低正确分类的样本的权重,相当于增加分错样本的权重);
与测试:每个弱分类器均给出自己的预测结果,且弱分类器的权重为log(1-error(Mi))/error(Mi) ) 权重最高的类别,即为最终预测结果。
在adaboost中, 弱分类器的个数的设计可以有多种方式,例如最简单的就是使用一维特征的树作为弱分类器。
adaboost在一定弱分类器数量控制下,速度较快,且效果还不错。
我们在实际应用中使用adaboost对输入关键词和推荐候选关键词进行相关性判断。随着新的模型方法的出现, adaboost效果已经稍显逊色,我们在同一数据集下,实验了GBDT和adaboost,在保证召回基本不变的情况下,简单调参后的Random Forest准确率居然比adaboost高5个点以上,效果令人吃惊。。。。
Bagging和Boosting都可以视为比较传统的集成学习思路。 现在常用的Random Forest,GBDT,GBRank其实都是更加精细化,效果更好的方法。 后续会有更加详细的内容专门介绍。
参考内容:
Data Mining Concepts and Techniques 2nd
Soft Margin for Adaboost
也可关注我的微博: weibo.com/dustinsea
或是直接访问: http://semocean.com