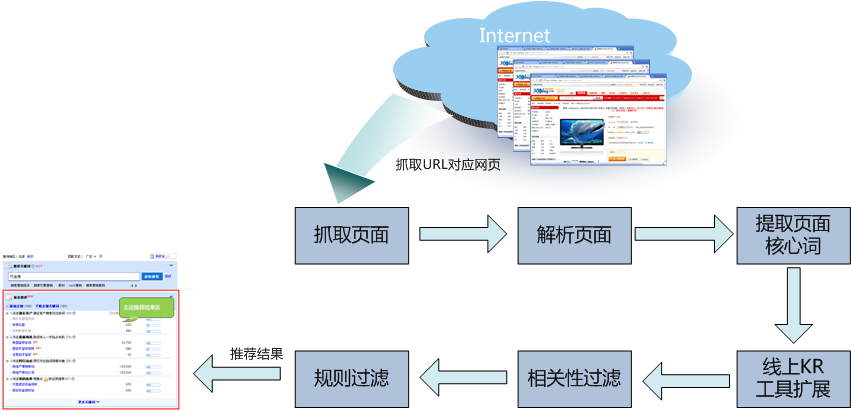
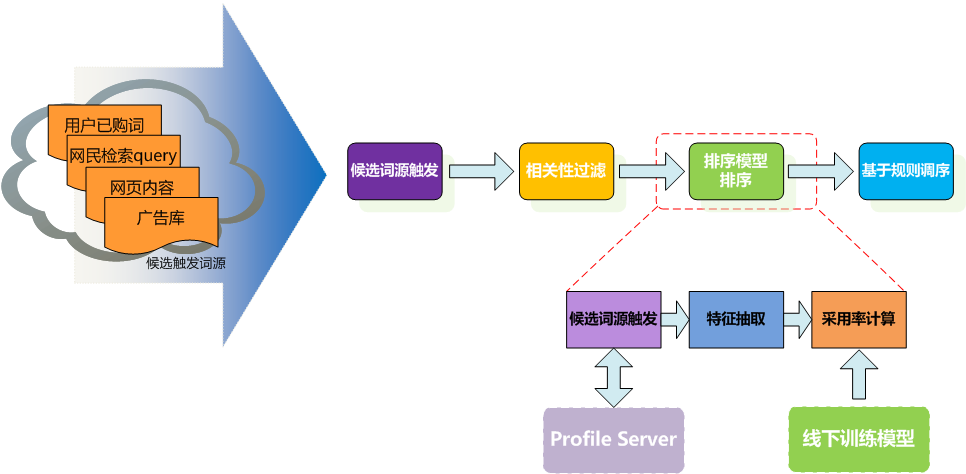
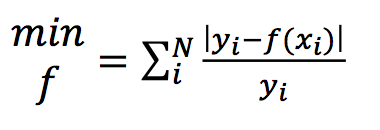介绍
参加了NeuraIPS回来后,公司让参会的几个同学都找个topic给公司其他人做一个分享,因为自己对AutoML比较感兴趣,所以就选在在公司分享这个话题。
其实我个人对AutoML这个方向没啥研究,也不是专家,只是对这个方向比较感兴趣。原因有二,一是觉得这个方向比较有意义,如果真的做成了,生产力提升不说,很多初中级的调参侠就要失业了,影响还是比较大的;二是一直在追推荐相关的技术,发现很多Paper都是在讲如何创新性地提出一个网络结构应对特殊场景,思路很像Neural Architecture Search做的工作,感觉这些事就应该AutoML来做。
下面就进入正文介绍分享的内容。
What&Why
大家在用机器学习解决具体问题的时候,流程一般比较长。一般包括以下几个步骤:
- 定义任务
- 收集数据
- 特征工程
- 模型选择
- 选择优化算法&参数
- 评估效果(效果不好则迭代)
- 发布&上线
这里边会存在以下几个挑战:
- 用machine learning解决问题的任务的pipeline比较长,包含定义问题,收集数据,数据预处理,模型选择,优化算法,以及这个过程的反复迭代,效果OK后再上线部署。里边混合着工程,算法,策略,很多时候一个人还搞不定
- 这方面的专家很贵,而且。之前爆出过机器学习的博士应届生薪水到60~80W,不是一般公司能够承受的
- 一般的专家就精通某个业务领域。而CV,NLP,语音等不同领域又有很大差异
所以这个时候的理想手段,就是使用AutoML,快速建立一套不错的机器学习流程来解决任务,不一定是最好的(也可能是最好的),但性价比比较高。这时留给人的主要工作,主要就是定义任务,收集数据以及线上部署及线上效果评估分析以及一些更有创造力,更有深度的工作
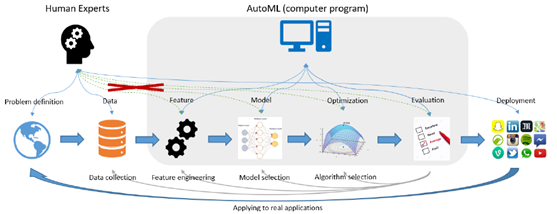
图:AutoML整体流程示意图
如果我们形式化地定义AutoML,则可以有以下定义:

图:AutoML形式化定义
简单来说就是:最优化整个学习工具(过程)的效果,优化的参数变量就是一组配置,限定条件有两个,1是没有人工参与,2是计算资源可控。该处的配置是个广义概念,包括使用哪些特征工程方法,使用什么模型,模型的超参数以及优化算法的种类和设置等

图:机器学习过程,人工调参并迭代

图:AutoML过程,机器自动完成特征工程,模型选择及调参
总结下来说,可以认为AutoML的特点是:效果好,性能优,无人工参与
How
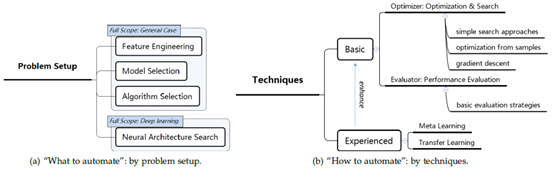
那AutoML中会涉及到哪些技术呢?从问题的setup来划分,我们可以根据将机器学习过程进行拆解来解决该问题。例如将整个机器学习问题拆解为:选择哪些特征工程方法,什么模型,什么优化算法,以及对应的参数。这是偏传统Shallow模型的流程;近些年DNN逐渐成为解决机器学习问题的主流手段后,AutoML也出现了另外一类端到端的方法,就是基于DNN的方法,默认问题都是用DNN来解决,而这其中需要机器做的就是找到一种适合该机器学习任务的网络,这类方法也叫NAS(Neural Architecture Searching)
从另外一个技术维度,又可以将AutoML方法划分为Basic方法和Experienced方法。这种划分方式的依据是AutoML是着眼于拿到手要解决的任务自动快速找到一个最优配置,还是根据历史上其他机器学习任务作为经验的学习来源,找到一种最优配置。
当然,AutoML在具体实施的过程中也面临很多挑战,主要是以下几点:
- 目标函数与参数配置无法直接关联,难于优化。从AutoML的形式化定义我们可以认为AutoML是一个优化问题:AutoML拿到一个任务后,最后产出是一组最优的配置。但是我们很难像传统机器学习一样,写出目标函数后求一阶导数或者二阶导数进行求解,我们可以认为AutoML是零阶导数问题,所以求解需要用另外一些优化方法
- 超参数空间较大。选择什么样的特征工程方法,算法,正则,学习率等都是超参数,超参数空间非常大,难于优化
- 函数的评估代价较为昂贵。每选定一组超参数后都去train一个模型然后验证效果,时间和计算成本都非常高
要求解AutoML问题的配置,一般会将整个AutoML在框架上分为两个组件。Optimizer和Evaluator,有些系统中也叫Tuner和Assessor,名字不一样,定义大同小异
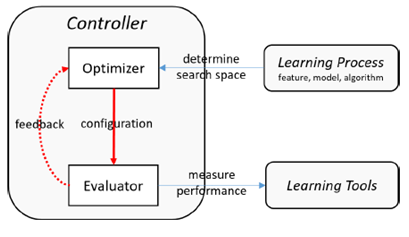
图:AutoML的一般框架
Optimizer主要负责寻找合适的配置,Evaluator负责评估Optimizer找到的配置,并将评估反馈回传到Optimizer以便Optimizer后续的决策
Optimizer
Optimizer可以认为是AutoML中研究最多最重要的组件,它直接决定了AutoML是否能够(快速)发现最优的配置,拿到最优的效果,经常使用的Optimizer算法有以下几种:
Simple Search Approachs:该方式就是暴力搜索,例如Grid Search,这个是我们经常使用的搜索算法,其做法是将各个维度的参数使用笛卡尔积的方式进行组合,优点是比较简单,缺点是组合方式呈指数爆炸,并且会将搜索试验的机会浪费在不重要的参数上;稍微改进的方式是Random Search,其优势是在各个维度上的试验次数都变多了,这样更容易在important的dimension上找到最优点,因为假设各个维度的参数相对独立。但总体Simple Search方法的缺点都是每次试验都是相对独立的,这就导致后续的搜索不能用到前边搜索的经验。
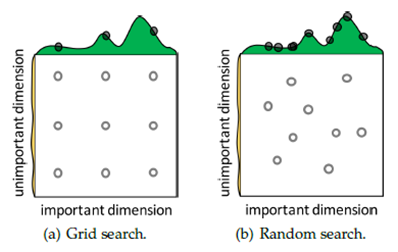
图:Simple Search Approach
Heuristic Method:该方式使用类似于自然界中种群行为和进化的思路。例如PSO(Particle Swarm Optimizer)会对新的参数进行探索,探索的方向是表现比较好的配置周边的配置(也可以认为是正向反馈较多的方向),就类似于飞行中鸟群会向虫子比较多的方向移动;另一种方法是Evoluationary Method,该类算法的思路是每次选出两个效果最好的配置(ancestor)进行杂交变异(crossover&mutation),类似于人的基因进化过程。Heuristic Method方法的优点是有效,思路容易理解,缺点是没有强的理论依据。
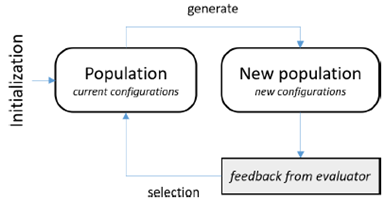
图:Heuristic Method
Model-based Method:该类方法是使用Samples(配置)产生模型,之后使用该模型产生一个比较好的配置,然后让Evaluator验证该配置,之后再使用该sample(配置)来更新该模型。经常使用的model-based方法为Baysian Method和Classification Method.其中Classification Method对samples进行二分类,每次从positive中找出一个sample去进行验证,验证结果再反馈更新模型
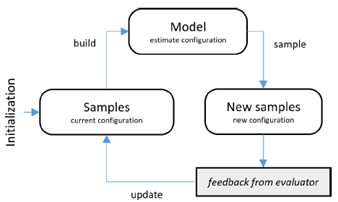
图:Model based Method
Reinforcement Learning Method:使用强化学习来找配置,当然有很多人也会有不同的声音,认为RL是比Optimizer复杂很多的问题,使用极度复杂的技术来解决相对简单的问题本身就是个问题,不合理。
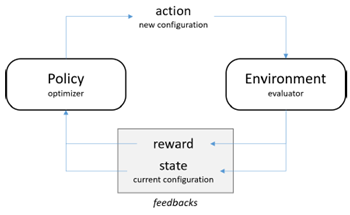
图:Reinforcement Learning based Method
Evaluator
Evaluator主要关注三方面的指标:评估准确性,评估效率以及优化反馈。其中评估准确性和效率很多时候需要进行权衡
Evaluator的具体方法相对会简单一些,主要有以下几类:
- Direct Evaluation:这是最粗暴的方式,相当于选定配置后直接train model,然后进行验证,是最慢的方式,当然也是验证结果最置信的方式
- Sub-Sampling:选定配置后,仅使用一部分采样后的样本来验证参数,优点是速度比较快,缺点是验证结果不一定置信,因为sub-sample set不一定能够完全代表总体数据集合
- Early Stop:验证过程中进行提前停止,减少迭代次数或者迭代时间,其中的假设是一个配置如果比较好,那么训练到一半的时候效果应该也比较好。该假设可能会产生噪音。一种Early Stopd的策略是并行跑多个配置,迭代特定次数后,保留效果最好的一半配置继续跑,这样不停减半淘汰
- Parameter Reusing:每次模型训练使用上次的权重进行初始化。该方式的优点是快,缺点是可能引入bias,因为不同的start point的结果可能不一致
Meta Learning
Meta Learning相当于使用完全不一样的另外一个思路来产生配置。它从过往的多个机器学习任务中进行经验学习,相当于对于Meta Learning来说,学习的样本是过往的多个机器学习任务,将过往的机器学习任务进行特征表示,例如过往机器学习任务的数据量大小,正负样本比例等统计信息,以及使用的机器学习算法,配置等作为特征去train一个Meta Learner。之后对于新来的机器学习任务,使用Meta Learner推荐一组配置去进行验证.此处Meta Learner可以是比较简单的模型。该方式的优点是能够减少搜索空间,提升效果,不过如何提取特征,如何进行表示会比较有挑战(就像其他传统机器学习任务一样),而且以机器学习任务作为训练样本,这个事也不是每个公司都能够做到的,这也可能是现在AutoML公司的先发优势,假设这些公司占了先机接了很多AutoML需求,则就能获取大量供Meta Learner进行学习的训练样本,而其它公司很难有这样的条件和实力获取这些训练样本
应用
早年在百度负责商业搜索推荐系统的时候,当时就想百度可以做一套通用推荐系统,该系统可以供中小网站主进行站内推荐:中小网站主提供数据,该系统自动为中小网站主定制推荐服务。该系统对中小网站主的价值是中小网站主获得了推荐系统的能力,对百度的价值是百度获得了这些网站的用户行为数据。但当时在百度组织结构划分的情况下该工作不太容易推进,同时项目系统的目标也没那么明确。但该系统可以认为从技术的角度就是需要AutoML的能力。
技术发展到现在,后续AutoML的发展还是很有希望能够有所突破的,原因有以下几点:
- 深度学习已经成为解决机器学习任务的标配
- 算力的持续增长
- 作为解决各种特定应用场景的tricky网络持续出现(算是AutoML的需求场景和价值)
- NAS(Neural Architecture Search)技术成为热点并逐渐有所突破
那后续会不会出现这样的场景:公司定义好一个机器学习任务后,就使用AutoML技术来解决,现在公司中的各种调参侠,除了对业务比较精通的那些同学外,其他都失业?这个是大家需要考虑的问题

图:使用RNN进行NAS网络生成
目前很多主流的公司都有自己AutoML的解决方案,例如Google,Microsoft,国内的第四范式。其中部分项目是开源的,大家可以上github了解
图:微软Neural Network Intelligence
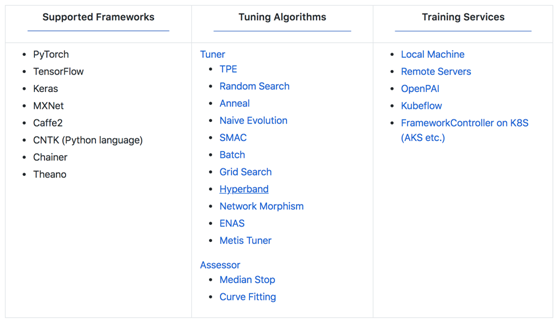
图:微软NNI提供提供的主要算法
Refference
- Quanming Y, Mengshuo W, Hugo J E, et al. Taking Human out of Learning Applications: A Survey on Automated Machine Learning[J]. 2018.
- Pham, Hieu, et al. "Efficient Neural Architecture Search via Parameter Sharing." arXiv preprint arXiv:1802.03268 (2018).
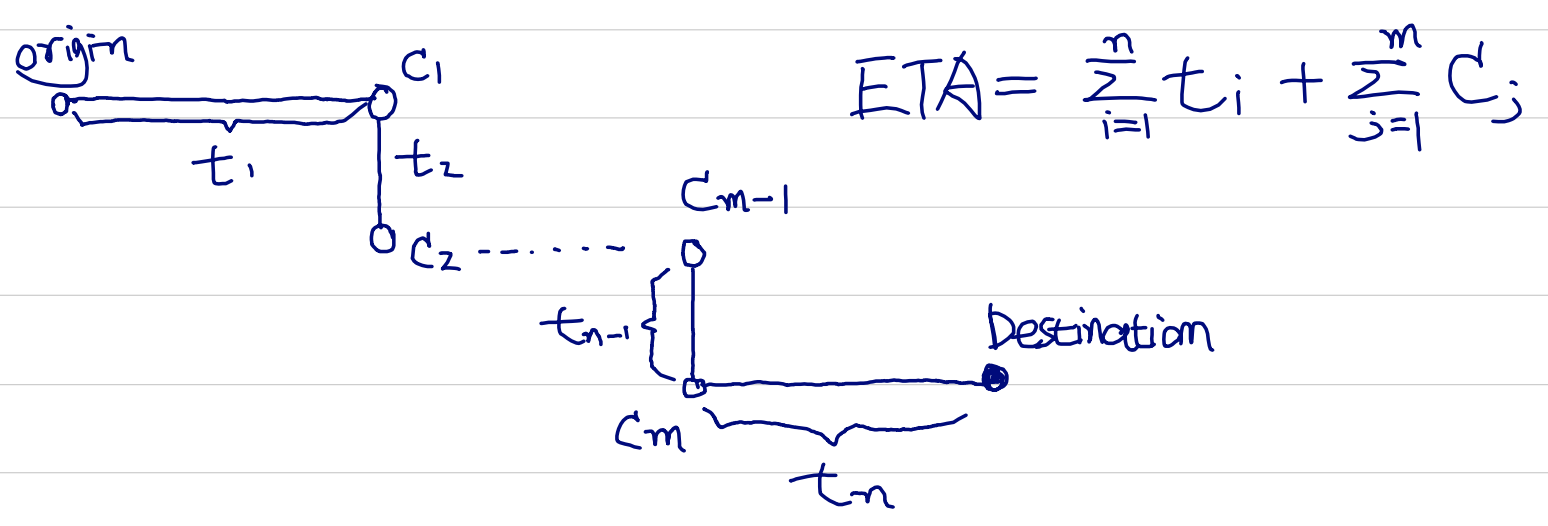
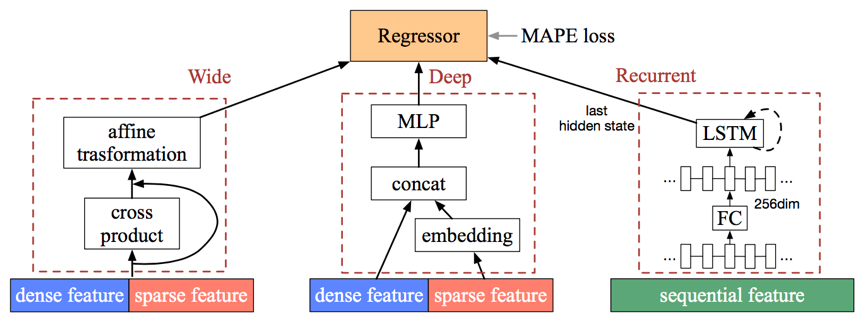
 图:滴滴ETA(接驾ETA以及送驾ETA)
图:滴滴ETA(接驾ETA以及送驾ETA)