在近期的项目中经常会使用到连续值模型以提升模型效果。 例如在项目初期, 训练数据准备OK后,就会使用原有的LR模型初步训练model看实际的效果, 同时因为连续值模型, 特别是树类模型已经在其他项目中应用并取得较好的效果, 所以我们也会将离散特征进行变换处理后, 使用GBDT, RF看下实际效果。
虽然GBDT, RF都有现成的model训练环境,直接用就可以,在项目过程中还是顺便复习了一下与树类模型相关的impurity度量标准;就像侯捷在《STL源码剖析》中说的,开飞机的人不一定需要了解飞机的原理,但参观飞机制造厂也是一种乐趣。
常用的使用impurity选择树模型拆分节点的度量有以下几类,他们都来自于信息论:
- Information Gain
- Gain Ratio
- Gini Index
以上三种根据impurity进行拆分的度量方式各有优缺点, 一下具体介绍
Information Gain
首先要定义概念熵(entropy)可以理解为定义一个分布的信息量, 具体定义如下:
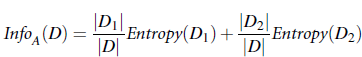
其中D为数据集合, pi为第i类在数据中出现的概率。之所以使用以2为底的对数, 是因为我们默认使用bit进行编码。而该处的info/entropy即描述分布不纯的程度。 而我们可以将树模型看成是对接点进行分裂, 之后根据拆分条件节点的建立使整棵树的叶子节点尽快达到较纯的状态。
假设现在有A,B,C作为拆分feature的候选,且假设我们选择使用featureA进行拆分, 则拆分后的信息为:
其中A为选择的feature,Dj为feature A的值为j的集合,而Information Gain,即表示在原分布上,确定待拆分的feature A 后, 所带来的信息增益(减少的信息量), 拆分时使用贪心算法, 信息减少量越多越好。故:
每次拆分时,贪心地选择Gain最大的feature A进行拆分即可。
最经典的Decision Tree算法ID3中即使用Information Gain作为节点拆分的标准。ID3算法具体描述参见:http://link.springer.com/article/10.1023/A:1022643204877
Gain Ratio
Information Gain在节点拆分时是有倾向的, 倾向于拆分属性值较多的feature,一个极端的例子,假设feature是具体的ID值,即每条instance的ID值都唯一,则对该feature进行一次拆分后,则每个节点都达到纯的状态,Information Gain值最大。为了解决该问题,在ID3的升级版Decision Tree中引入另外的拆分标准,Gain Ratio。
定义: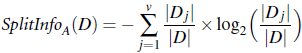
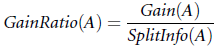
因为某feature的属性值越多, SplitInfo就会越大,故可以使用SplitInfo在一定程度上消除Information Gain倾向于多属性feature的偏好。 具体Gain Ratio如下:
在此:属性值越多Gain越大,但SplitInfo也会越大,这样就中合了Information Gain带来的偏向。
P.S. 做策略算法中,类似的操作都是互通的,例如在推荐引擎中,用户打分可能偏好不一样,有些习惯打高分,有些习惯打低分,则我们可以使用打分的均值去中和这种偏差;而有些人打分分值比较集中,有些人则分布比较广泛,则我们可以使用z-score,即处于标准差去一定程度上消除这种分布。
Gini Index
Gini Index在CART(Classify and Regression Tree)中使用,定义:
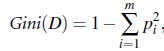
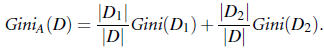
其中D为数据集, pi为类Ci在D中出现的概率, 可以直接使用|Dci|/|D|预估。
假设我们在feature A上进行拆分, 并且是进行二分类拆分,拆分得到D1,D2数据集
则拆分后的Gini Index如上。
同样, 我们使用Gini稀疏的减少量选择拆分的feature。
这里需要注意,CART中仅进行二分拆分,如果A为多属性, 则需要转化为二分类拆分。
细心的同学可能会发现,除了gini和entropy的定义不一样外,其余的计算Gain的方式都是相似的
reference:
induction to decision tree, J,R,Quinlan
Data Ming: Concepts and Techniques
也可关注微博: weibo.com/dustinsea
或是直接访问: http://semocean.com