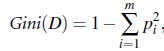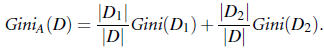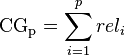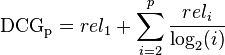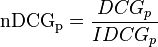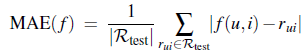前段时间,各大互联网公司间举行了一次‘互联网公司足球大赛’,其中一场比赛是百度对战360, 百度有最帅气年轻的VP李明远参与的球队, 最终于。。。。先不说最终比分如何,微博上一条神回复让我觉得挺搞笑但又挺有感触: ‘足球比赛,百度VS 360 是百度新员工和百度老员工的比赛’
事实其实也是这样,和我一起08年入职还在公司的员工真心不多。每次我刚入职所在的小组的10多个同事聚会,提到我还在公司,他们都会露出惊讶的表情: 怎么还在百度!
的确, 我一直都惊讶百度的离职率是如此之高, 但后来了解到其他互联网公司也差不多, 甚至更高,频繁地跳槽似乎已经成为一种常态。 但无论如何,对于一个公司来说,过高的离职率本身就是不正常的,作为管理者,就应该通过各种手段降低离职率,而不是因为行业如此,就任其为之。
以下就通过我个人在百度的经历,经验以及教训, 以及公司中的培训,说下我碰到的员工离职的原因, 以及在管理者能够操作的范围内,如何挽留员工,保持团队的稳定性及士气。
总结下来,主要有两个因素影响员工去留: 职业发展和薪水,即前途和钱途,员工的离职,基本上都是因为这两方面的原因。
职业发展有可以细分为团队的发展和个人的发展。不恰当但形象的例子,我们可以将团队的发展看成是股市的大盘而个人发展看成是具体的股票, 大盘疯涨的时候,个股一般都会水涨船高,大盘低迷的时候,很少有股票能够表现惊人。 例如在一个公司作为战略重点的部分会是组,得到的资源更多,更容易出成绩,而一些边缘部门或组,事实上就不太受重视,也没有太多资源投入,发展很慢,缺少核心技术,员工看不到未来。薪水则是马斯洛论述的底层需求,高薪水是高物质生活的象征,而且帝都生活压力也挺大的, 所以这个因素也会对员工的去留取决定性作用。
让员工对团队的认可和信心
员工都是在具体团队中工作, 团队做的事,方向就是这个员工的舞台,同样舞蹈功底的人,在人流涌动的中关村地铁站口与在满座的国家大剧院 跳同样的舞, 获得的关注及成就感肯定不一样;或者用另一句通俗的话讲: 台风来的时候,猪都能上天。 当然搞IT的都不是猪,大家都很聪明,团队的核心价值及接下来要做的事是否能得到员工认可就至关重要, 如果得到认可,员工就会认为自己是在国家大剧院跳舞,自豪感,满足感油然而生;而如果员工悲观地觉得自己只是个中关村街边的流浪艺人, 那么他会对未来悲观,迷茫,也许之后他会好好想想是不是要找另一个个像国家大剧院的舞台。
另外很重要的一点,就是就是leader是否能给员工信心,一直都听说马云初创的时候,很多人都一直跟着马云,就是信任马云,这个leader就像是古代战场上的将军一样,如果有一个自己佩服的老大,那就算团队,业务有较大的调整变动,但下边的人仍然有信心跟着老大,充满信心;而如果团队中这样的人离开, 那么员工也可能会因为看不清未来而选择离职。所以有时留住团队留住领军人物,就显得至关重要了。
非常现实的事实: 前些天老大说我们优化团队为支持无线的后续发展会进行调整以更高效地支持无线变现,正当团队热火朝天地组织各种讨论, 各种规划的时候,突然得到消息,后续计划有变, 团队会被整体划到另外一个部门,当时团队里知道这个消息的人真是惊呆了,与老大沟通了半天我也没感觉到团队划出去的好处,怎么看都是效率变低,当时真的立马就有一丝想离职的冲动。。。
另外对一些级别比较高的员工,有时也会因为对公司,团队一些做事的方向,理念,思路及做事方式不认可,而去寻找新的环境。
解决之道:明确团队方向规划,认可团队价值
需要让员工了解团队的价值, 让员工觉得自己是在为一项事业而工作,而不是简单的搬砖头,螺丝钉。
管理者需要明确团队的定位及核心价值,在此基础上制定明确的roadmap,并将这些信息充分向下传达并保证大家都能认同这些信息。 如果员工有内容不认同, 则需要详细了解是因为什么原因导致不认同,并及时使用有针对性的措施或是及时调整。同时要时时为员工打气,让其认识到团队的使命感, 自己的重要性。员工认可团队的核心价值及roadmap后,即使碰到风浪,他也会像乘坐在大船中一样,知道远航的目标。
当然,有时候明确团队方向这个问题, 受到管理者所在大环境的限制,相当于管理者所在的大环境决定了员工所能上升到的天花板。例如有些部门喜欢不断提出(或是从其他部门抢夺)一些新的项目,并且将其规划得很大重点去推,在项目推进的过程中,员工会感觉到自己做的事前途无量,上升空间很大。当然这种方式也有一个风险,就是更新更受关注的项目出现的时候, 资源很容易就被投到新项目。做原有项目的人会觉得被冷落而有一种失落感。 还有些部门是守着自己的疆土,将某一领域做深, 在自己土地上还能深挖的时候,员工会觉得自己能学到很多东西,能有成长, 但当整个领域已经达到一定高度,技术带来的提升不明显,而管理者提前没有去开发新领域时, 就可能出现问题。
相对于所处大环境决定的员工发展的天花板,员工管理者帮助员工制定的个人规划,则相当于在既定的天花板的事实上,如何让员工更接近这个天花板。管理者可以在这块有更多的发挥, 或者说也只能在这块上多做一些事。
让员工对自己发展有信心
以前一个同事的跟我说过‘自己只是公司微不足道的一小部分,对对于自己却是全部’,很多时候我们会谈公司的使命,价值观, 这个的确很重要,因为没有使命,没有明确价值观的公司很容易走偏,这些东西在将员工凝聚在一起时起了不可估量的作用,但很多时候员工更关注自己的发展,如果员工觉得自己的发展出现了瓶颈,看不清未来,且这种状态持续一段时间,那么他离职的可能性也非常高。
我们可以将员工对个人发展的认知过程分为: 向前看和向两边看两种方式。
向前看, 是指员工分析自己的个人发展,是否认可自己在团队,公司的发展及前景。 包括员工想在这个公司,这个团队做怎样的事,获得什么提升,有怎样的提升。
例如员工对照自己在团队中所负责的工作,感觉到这个工作规划比较清晰, 且在接下来的较长时间, 这个方向可以长时间投入且有较大的提升, 那么这个员工肯定干劲十足全情投入;反过来,如果这个员工觉得以同样的状态方式, 在接下来一两年都不会有太大长进, 那除非他就是想在公司养老,否则他肯定会考虑动一动,找一个自己认可的方向,团队或是公司。
另外员工如果感觉到自己的老大不重视自己,或是不重视自己所做的工作,员工也会比较沮丧,这也会滋生员工离职的想法。 这些是员工对自己发展的向前看的方式。
相对地,向两边看,是指员工与公司其他员工,或是公司,部门内外同行,同事的比较,也许员工在公司里的晋升并不慢,但如果员工看到觉得和自己水平差不多的员工发展得更好更快, 那么他也会产生一种不公平的感觉。比如我之前的一次经历: 经理告诉我没有晋升,我很沮丧, 他花了很多时间和我沟通,总算让我心情平静了一些,但当晋升结果公布时,平常由我带着做项目的员工居然晋升,界别比我高时,我出离愤怒了, 当时立马产生离职的念头。 后来经理又各种安抚。 这也或多或少有点不患寡而患不均的味道。
解决之道: 给空间,重认可,多指导
给空间: 我们经常会说一个贬义词(至少很多时候我觉得是个贬义词): 画大饼。 但画大饼真的比较重要, 而且很多时候, 没有画的大饼, 就不会有真正的大饼。 画大饼, 其实就是为员工描绘了关于他自己的一个美好的远景。 当然, 只画大饼远远不够,也许画大饼的时候员工的确能够对未来有美好的憧憬,不过一旦员工发现大饼是不能做成的,那后果会比较严重,不仅之后的画大饼不起作用,同时员工也会对管理者失去信任。 所以管理者不仅要画大饼,还要给足员工做大饼的料,帮助员工做成大饼。例如一开始给员工一个明确的目标规划,那就需要在资源上支持员工完成这个目标,时候也要和员工一起回顾目标完成的情况,是员工没做好,还是料没给够。如果料没给足,那很多时候管理者就需要反省了
重认可: 这里主要是指员工的工作是不是得到管理者,团队及公司的认可,这里包含两个层面: 第一是否得到精神上的认可。如果员工觉得自己的工作及成果连自己的管理者都没有认可,那员工很少能有后续动力继续推进,这种认可很多时候可以是语言上的和行动上的,管理者对员工的任何成长进行语言或物质上的奖励,都会带来正向的效果。例如一句及时的口头表扬,一封邮件,或是季度,年度的一个奖项,都能带来较好的效果。但同样的,管理者的行为细节会让员工感觉到管理者是否受到重视,所以管理者要非常注意在员工面前的表现, 相由心生,员工会根据管理者的这些行为细节(正确或错误)地感受到自己是否真的受重视。
同时管理者要非常重视one-one的过程,员工表现好的地方要多给表扬,激励其再接再厉,表现不好的地方,要以一种帮助其进步的姿态指出,并给其建议。
第二是实质上的认可, 最明显的就是员工有没有因为所做的工作而得到晋升,因为公司有自己的流程,所以有时的确会出现很多人做的很卖力,也得到了很多精神奖励,例如口头表扬,个人奖项, 但没有晋升的情况(况且不谈这样的流程是否是最合理的); 如果出现这种,员工也会认为的工作没有被认可,得到了不公的待遇,也会产生较为负面的影响。应该尽量减少这种精神和实质认可不一致的情况。
多指导
给了空间, 有了认可以后, 还需要持续指导员工。 这里的指导又包含多方面的,例如经理的指导和直接导师的指导, 而且很多时候导师的指导更加重要直接。 好的导师能够让员工学习到更多的东西, 无论是知识或是方法,同时能保证员工能够在自己的工作中不走偏(这个也需要经理的更多参与),导师在身边能在一定程度上增强员工的安全感。
薪水的重要性
事实上,现在人们生存的压力的确也比较大,所以一方面上级,团队,公司的认可,能够满足自己更高层次的追求,但作为马斯洛基本层次的需求, 薪水也是影响绝大部分员工去留的重要因素。也许他在团队中工作比较开心, 能学到较多东西,但换个场景:如果员工觉得他在另外一个环境中,也能够开心的工作且学到较多的东西,而且拿的钱更多,或者多很多, 那我会问:他为什么不跳槽? 另一种情况,他已经觉得这个环境拿的钱比较低了,而且未来也可以预期不会涨很多,那他肯定就会考虑换工作了。 特别现在互联网公司比较多,外部给出的待遇也还不错。
这个问题其实很难解决, 因为薪水这东西太实在, 我碰到过很多员工,在公司其实工作得也挺开心的,但还是选择了外部的机会,因为外部开出的薪酬条件更诱人; 也有很多员工本来就觉得公司给得低,主动选择的。
解决之道: 这个一方面依赖于公司能否给出较高的package;另一方面,也需要在员工的个人发展上狠下功夫, 让员工了解认可自己的发展,以及寻求外部发展的规律。例如对于新人,需要让他们了解他们现阶段主要精力应该花在如何提升自己的内容; 对于老一些的员工,和他们一起做好个人的规划,让他们充分认可,同时和他们沟通寻求外部发展的规律(我的看法是这个平台是否还能支撑自己的后续发展,能否达到自己追求的目标,以及外部的机会,是否是真的好机会,是否真的适合自己)
团队的氛围
团队的氛围不是决定性的因素,如果员工因为其他原因有了离职的想法,那好的团队氛围也是留不住员工的,不过较好的团队氛围,的确能减少员工离职的想法,或是在一定程度上抵消外部更高薪金的诱惑。 有那么一种说法, 比较好的团队氛围, 能够抵消外部最高30%~50%薪酬提升的诱惑。
总的来说,给员工发展空间,以及高薪金是公司能够提供的硬实力,他依赖于公司的发展阶段,盈利能力,以及公司对人才的投入,对每个人的投入;价值观,团队氛围等属于软实力,这是管理者更多需要发挥的地方。 很多时候,以为强调软实力会让员工更理性,而且一旦在发展,薪金上受了挫折或者不公,就可能产生比较负面的后果; 较强的软实力不能保证员工不离职, 但却能增强员工的凝聚力,增强员工的幸福感, 也能在一定程度上抵消外部的诱惑, 或者是因为这些软实力有些员工就不会有意识地和外部进行过多的接触,减少外部的诱惑。
从一开始招聘就关注离职风险
很多时候,从招聘的时候,就需要考虑这个人能长期留在公司的可能性, 说一个我碰到的例子: 我在公司负责流量推荐系统,之前来校招面试的一个小姑娘,技术面结果还可以,考虑到她有推荐系统的项目经验,就给了一个校招offer,不过后来HR联系我说这小姑娘比较浮躁,是HR见过的最浮躁的校招候选人,,她可能是想拿百度的offer去其他公司谈条件,建议不发offer。我给的建议是先发offer,看她是否签,结果不出HR所料她果然拒了offer。 但后来她没拿到其它公司更好的offer,又打电话联系我,希望给她offer。 最终我还是没有给她offer,因为觉得HR说得对,她不是那么踏实,而且也不是没给她机会。从这个事后,我面试候选人的时候,也会更加注意这个人是否浮躁,是否能长期待在公司。
工作1.5~2年或者工作5年也是离职高峰, 一般工作1两年的人,觉得在公司做的事已经比较熟练,想寻找更多挑战,或是外部薪水的诱惑,会有较高的概率离职,工作5年的人,会对自己的个人发展有更清楚的认识,也可能会做出判断后选择离职。所以这两个阶段也需要特别关注。 这些都需要在平常的one-one中细致观察多沟通,提前了解,做好功课。
或是直接访问: http://semocean.com