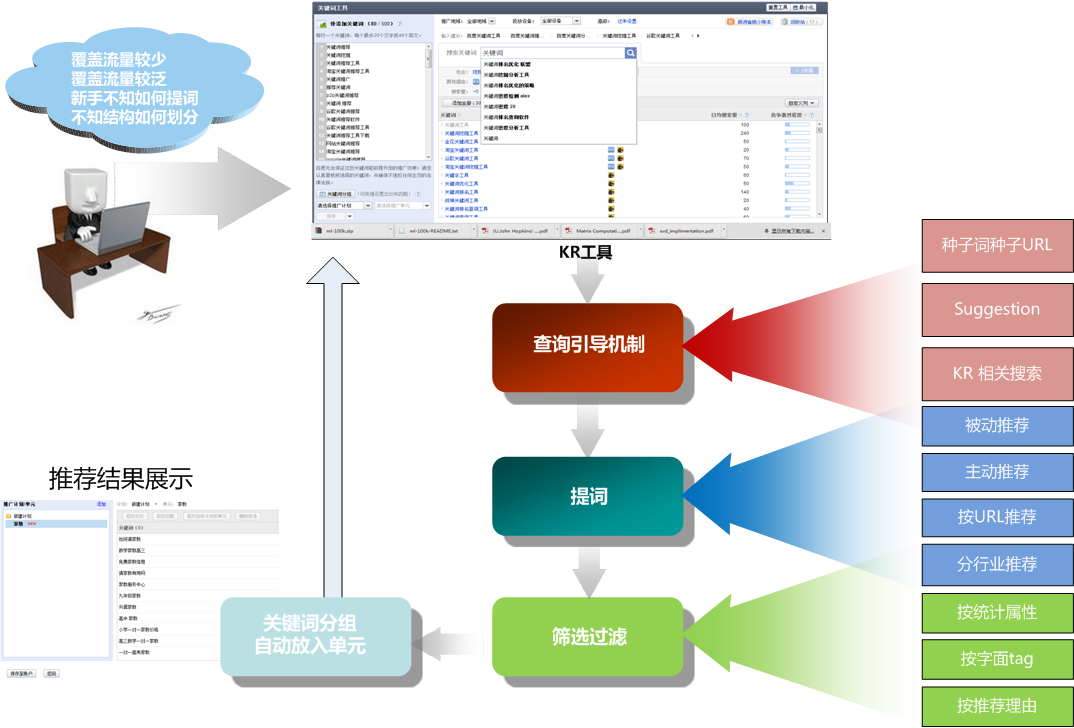
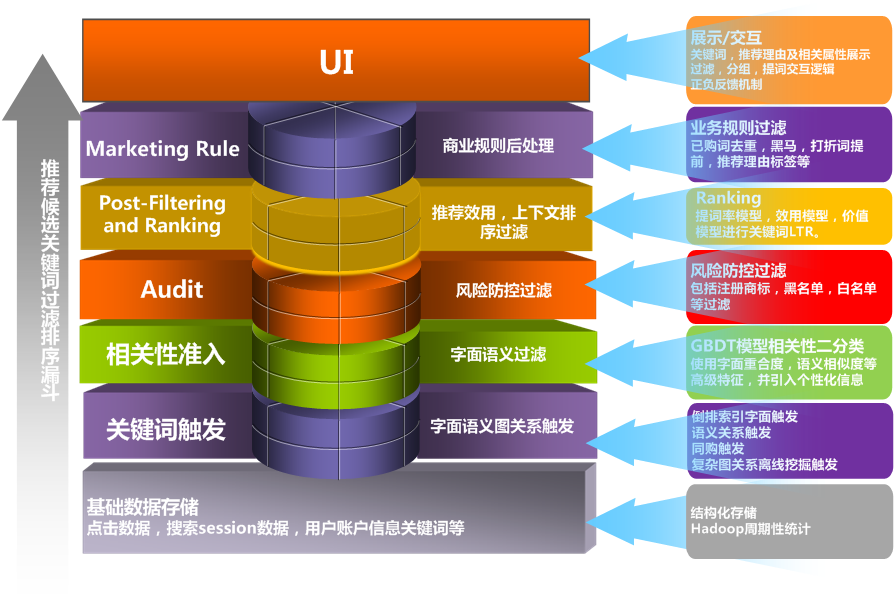
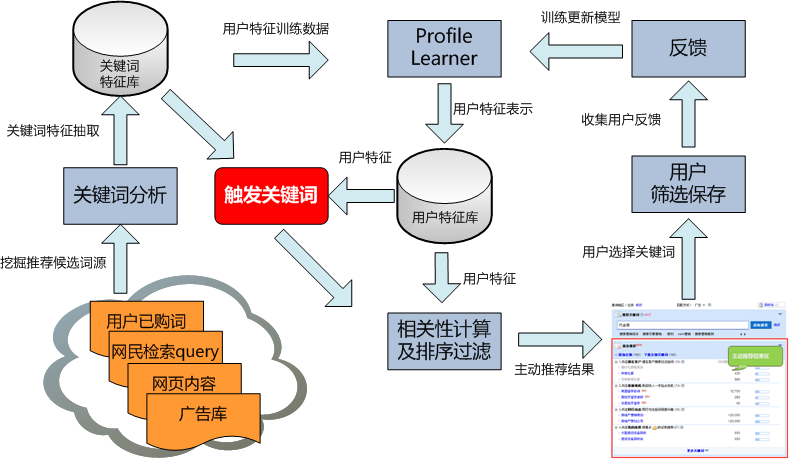
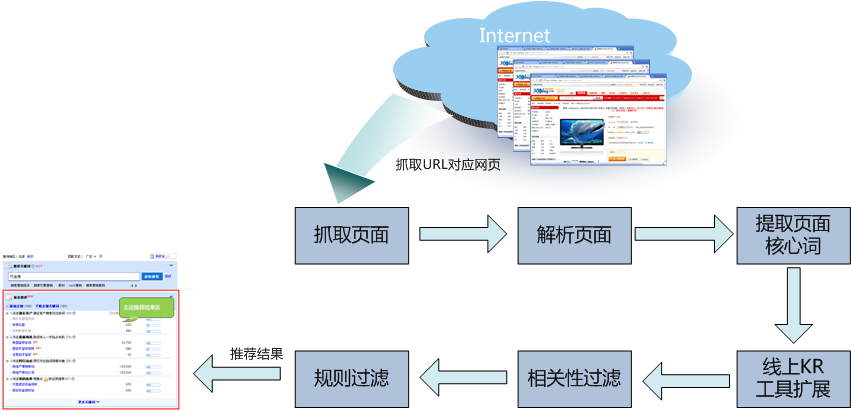
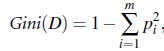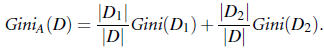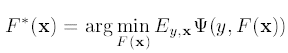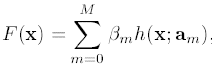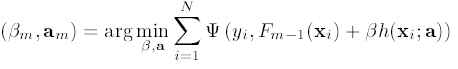背景介绍
在推荐系统,或者移动广告变现业务中,抛开内容的生产,用户的增长等挑战后,从算法的角度存在以下几个比较有挑战的技术点:
- 冷启动问题(Cold Start):新的用户如何处理
- 新广告探索(Exploitation&Exploration):没有历史统计信息的item或者广告如何快速确定其效果,既不能再新Ads上浪费过多流量,也不能每次都采用贪心算法仅关注短期利益
- 转化延迟产生建模问题(Modelling Delay Feedback):从点击到最终效果的产生中间有较长时间的间隔,如何对该问题进行建模。具体问题描述和解决方案可参见《移动端转化延迟相关CPI转化率模型建模方法》
- 点击率预估(CTR),包括单点的《推荐系统,变现系统CTR&CVR预估算法演进-模型》,以及《推荐系统,变现系统CTR&CVR预估算法演进-多任务算法》
这些问题解决的好坏都会严重影响系统的效果,而且每一个问题在工业界&学术界都有较多的研究。
下文主要对第4个问题:点击率预估近几年的发展进行简单总结,供大家参考。
广告和推荐算是比较经典老牌的大数据落地的业务场景,而其中的核心技术点CTR预估中使用的技术,也从最经典的LR,逐步发展到树模型,FM等,而近几年随着深度学习技术的发展成熟,现在CTR预估(包括转化率预估)也逐渐开始使用深度学习,并且在各大公司的业务场景中均已经得到较大程度的效果提升。下文就对近期出现的和深度学习相关的CTR预估模型进行总结。方便我个人review也供大家参考。
问题定义
可以简单定义CTR预估问题为预估P(C|X),其中:
- C为是否点击
- X为使用的特征,X在变现中会包含用户profile特征,用户行为特征,广告特征,场景上下文特征
当然,在更复杂的应用场景下,可能我们不仅需要预估CTR,同时还需要预估CVR(转化率),则此时的问题建模为:
ECPM=P(CLK|X) * P(Conversion|CLK,X) * CPA,此处主要讨论P(CLK|X).
LR
传统的方法主要是使用LR来进行CTR预估,该方法能够适用的主要原因是LR相对来说不仅比较简单,更偏记忆的模型,该模型会记忆高频出现的特征,相当于是对历史的exploitation。而且该模型容易进行并行化,线上处理也非常快,因为虽然训练的时候特征空间有数十亿维,但线上真实使用过程中,非0的特征一般也就就是个,所以处理性能较高。当然该模型缺点也比较明显,就是该模型更多是对历史的记忆,但需要很多人工特征组合,否则原特征的维度上可能不能很好地划分问题,同时人工特征组合也相当于增加了模型的个性化描述,效果会更好。
GBDT+LR
该方法是facebook发表的其广告系统中使用的CTR预估算法(参见《深度学习资料》),也算是业界比较经典的算法了。主要思路为:1,使用GBDT进行特征抽特征(进行自动特征组合);2,使用LR对GBDT抽取的特征(规则组合)进行权重学习。3,一般训练的方式为先将GBDT训练好,之后固定树模型并对叶子节点进行编码作为LR特征训练LR。该方式在业界有较为广泛的应用,例如滴滴路况预测中,能够提升有效准确率2%,而美团ETA应用中预估时间的MAE能够下降3.4%(与论文中3%的下降接近).;同时文中对影响CTR模型效果的几个因素进行了分析,得到以下几个结论:
- 模型的自动更新很重要:模型一周不更新,效果下降1%左右,考虑到性能,甚至可以gbdt模型更新频率相对低,lr更新相对快
- 对于gbdt+lr模型,historical特征较为重要(top 10特征均为historical特征),但contextal特征对cold start较为重要
- 参数更新的schedule方法中,per-coordination方式明显好于其他方式
- 在display ads中,训练时可以进行负采样,但后续线上使用的时候需将概率分布转换回原分布:q=1/(p+(1-p)/w),其中q为最终ctr值,p为采样后模型预估值,w为负采样比例
当然,如果只是预估排序而不是具体的CTR值,则可以不做步骤4。
该方式和单纯的LR相比,其实已经包含了自动特征抽取的思路,因为GBDT模型天然就是进行特征组合(抽取特征),之后再使用LR来学习这些组合特征的权重;而该方式的另外一个优点,就是能够很好地处理连续特征,如果单纯使用LR,我们还需要进行特征离散化,而GBDT天然就对连续特征进行处理。

图:GBDT+LR.使用GBDT进行特征自动组合,其实现在使用DNN的主要作用也可以认为是使用DNN自动抽取高维度特征
更进一步,在该算法的基础上逐渐出现了一系列变种,我们可以称为GBDT+LR Plus,其思路和GBDT+LR类似,只是受限于GBDT的结构,GBDT能够很自然地处理连续值特征,但对离散特征的处理不够好,反过来LR能够很好地处理连续值特征,所以后来衍生出来的模型结构, 一方面使用GBDT来提取特征后作为LR的输入,同时仍然保留离散特征作为LR的另一部分输入,这样LR模型就同时具有GBDT特征组合和离散特征。当然该处的LR可以换成FM,或者FFM等模型。具体的实例参见《深度学习资料》中关于CTR部分的Kaggle Criteo Ctr预估介绍:3 Idiots’s Approach for Display Ads Challenge. 为Kaggle上Critero ctr预估第一名使用的方法,主要的思路为:
- 使用GBDT对连续特征,以及出现频率极高的离散特征进行特征组合(类似于FB display ads ctr预估)
- 组合出来的特征,结合离散化后的连续值特征,原有离散特征(共3类特征)
- 使用FFM进行CTR预估,并在得到CTR值后对预估值进行Calibration(简单地加减一个固定值)
图:GBDT+LR Plus:GBDT后,离散特征仍然输入至线性模型,相当于线性模型的特征输入包含两部分:离散特征+GBDT组合特征
总体来说,这个时期大家的工作还都集中在如何使用浅模型让效果最优,例如很多公司在推荐系统中使用FM(例如头条的推荐系统),而类似于Kaggle这样的专门比赛的场景,则更倾向于ensemble的算法,例如《深度学习资料》介绍的Kaggle Avazu CTR预估:4 Idiots’s Approach for Display Advertising Click-through Rate Prediction. 另一个Kaggle上的display ads ctr prediction 比赛,冠军组使用的方法介绍中,有两个关键点:1,ensemble,目前已经成为competition的标配;2,feature engineering,文中使用了较多单独构造的feature,例如user /deviceid count, hourly impression count; user installed app bagging, user click action的编码等。最终获奖的模型为20个ffm的ensenbling
Wide&Deep
之后很长时间,工业界使用的方法都是类似于GBDT+LR,FM,FFM之类的浅模型;如果是比赛场景,则更多会在这些模型的基础上进行essemble。而对于深度学习,大家基本上都持观望态度,一方面是大家会有一个初步的判断,就是深度学习更多适用于信息完全且格式规范化的问题,例如图像(输入图像中包含所有信息,格式统一),而能不能应用在信息稀疏的场景有待验证;另一方面是深度学习对计算资源的要求比较高,一般没有GPU卡基本上不用去尝试,速度非常慢,而GPU卡的成本又非常高,所以很多公司并不会投入那么高的成本去尝试一个未知的东西,特别是创业型公司或者业务驱动的公司。直到2016年,随着GooglePlay app推荐场景,以及Youtube视频推荐场景下google在深度学习推荐上取得明显效果,且论文发布后,深度学习在这个领域的应用才得到更多的关注。
以GooglePlay app推荐为例,GooglePlay App推荐:《深度学习资料》:Cheng H T , Koc L , Harmsen J , et al. Wide & Deep Learning for Recommender Systems[J]. 2016.提出了Wide&Deep方法(同时可参见《lbs工业界eta应用及滴滴wdr技术》),主要思路是使用Wide线性部分作为Memorization,对历史信息进行exploit,而使用Deep部分,对特征进行自动的更高层次的组合与抽象(个人理解和NLP中的模式类似,Deep部分能够学习复杂计算,同时对特征进行组合并生成embedding)进行自动特征组合,并进行更高层次的泛化,相当于对训练数据中的信息进行explore。该方法同时解决了wide需要进行手动特征组合的缺点,以及Deep有可能过拟合的缺点;而训练的方式为进行Jointly training,其中wide部分使用ftrl训练,deep部分使用adagrid后adam进行训练...Note…P.S. 目前Wide&Deep已经作为一个标准Framework解决分类和回归问题,例如滴滴ETA模型,我们使用Wide&Deep&Recurrent的WDR方法进行ETA预估(可参见《lbs工业界eta应用及滴滴wdr技术》)
图:Wide&Deep:离散特征进行embedding之后和连续特征进行concat作为deep输入
W&D变种
Wide&Deep推出后,基本上就作为业界的一个baseline的算法框架使用,在这个过程中也会有比较多的网络改进。改进的思路也基本上是在弥补Wide&Deep的各种不足。而优化的方向,基本上就是两个:要么优化wide部分的能力,要么优化deep部分的能力和效果。
Deep Cross Network
例如:Wang R, Fu B, Fu G, et al. Deep & cross network for ad click predictions[C]//Proceedings of the ADKDD’17. ACM, 2017: 12. 提出的DCN,在DNN的基础上,增加使用cross network对特征进行交叉。文中cross network有两个特点:
- 能够限定特征交叉的阶数(bounded order),且可以认为cross network的depth数,就是特征交叉的阶数
- 每次进行特征交叉的时候,相当于同时在做和第一层输入的交叉,同时在学习上一层的残差。最后cross network再和dnn进行combination。和deepfm相比:相同点是网络结构比较类似。不同点在于cross network从理论上能够从cross network的网络层数控制feature intesection的阶数..Note..
图:DCN示意图:DNN的同时,增加cross network
具体推导公式为:

图:DCN网络交叉方式:每一层均和输入进行交叉学习残差。同时可以认为cross network的层数,就是特征交叉的阶数
DeepFM
另一种比较常见的模型结构是DeepFM. 2017 Huawei App Recommender Ctr Prediction:Guo H , Tang R , Ye Y , et al. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction[J]. 2017.华为App应用市场发布的推荐方法,基于Wide&Deep,区别在于两点:
将Google的Wide部分的LR模型换为FM,用于学习特征二阶交叉
不同于其他Deep的模型,FM和Deep部分使用的特征的Embedding是相同的,相当于low &hight order feature intesection都会反映到Embedding中在Wide部分和Deep部分进行共享,且训练速度和FNN(FM与训练V作为Deep Model Embedding参数初始化),PNN(Embedding和First Hiden Layer之间进行一次inner production,效果不错但增加了全连接规模导致训练较慢)要好。PS.在滴滴ETA模型中,我们就借鉴了DeepFM思路,不过其中的Deep部分会比较复杂,同时在最终的融合部分,增加了初始Additive ETA Model…..Note。该方式与传统的Wide&Deep方式相比的优势是,对于Wide部分,模型不用再使用太多人工特征,可以认为FM能够很好地完成低阶(二阶)特征组合
图:DeepFM网络结构图:1,wide部分使用FM代替;2,embedding wide&deep共享
Deep Interest Network
Zhou G , Song C , Zhu X , et al. Deep Interest Network for Click-Through Rate Prediction[J]. 2017.目前deep learning在CTR&CVR预估上,使用较多的方法是Embedding&MLP的方式,思路是对原来稀spase features先进行embedding,之后进行feature group wise的pooling,例如sum或者average,之后得到定长的vector再输入MLP(MLP可以有很多变种,例如res-net思路)。该方式在淘宝上的缺点是:user的兴趣可能不止一个,例如年轻妈妈可能关注自己喜欢的时尚衣服,同时也在购买婴儿用品,故直接sum/average的user featrues pooling方式存在信息损失,既进行pooling后,在embedding空间中得到的向量可能和该用户的众多兴趣距离都较远。故Deep Interest Network将user behavioral embeddings与ads的embedding使用local network的方式进行学习,最大程度上根据用户historical 的behavioral feature体现与ads的相关性,从网络结构的角度,我们可以认为是每个ads去和最相近的user behavior embedding来进行权重分配,以便突出地体现和该广告相关的用户行为…Note..
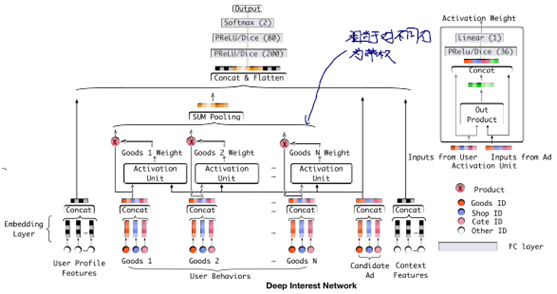
图:DIN(Deep Intresting Network)
FM深度化
CTR预估模型的另外一个发展方向是在原来FM的基础上,引入深度学习的思想,将二者结合起来,者可以认为是FM的扩展或者能力的增强
例如Attention Factorization Machine
Xiao J, Ye H, He X, et al. Attentional factorization machines: Learning the weight of feature interactions via attention networks[J]. arXiv preprint arXiv:1708.04617, 2017.网络结构中的设计思想是认为FM中,每个特征对应的隐变量(embedding)在使用过程中的权重都相同(均为1)是不合理的。特征在进行交叉的时候,权重应该不一样。故在FM结构中增加attention network来学习特征embedding进行element-wise交叉时候的权重。该方法一方面能够提升效果,另一方面,也能够根据特征交叉过程中的权重,分析交叉特征的重要性:通过分析网络产生的attention score,能够观测到哪些特征的组合重要性更高(和未做attention的fm相比)。而文中通过先固定attention score训练fm embedding,之后再固定embedding训练attention权重的方式,也验证了在传统fm上增加attention network的确对最终的效果有正向作用..Note..

图:添加了Attention的FM,背后的intuition是fm进行二阶交叉时,特征的重要性是不一样的,通过Attention来捕捉该差异
又例如在Neural Factorization Machine中,He X, Chua T S. Neural factorization machines for sparse predictive analytics[C]//Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval. ACM, 2017: 355-364.在FM后增加了隐藏层,以便在原有FM线性二阶交叉的基础上增加非线性的更多特征交叉。这类方法我们都可以认为是在FM的基础上,使用DNN的思路,对FM进行能力的增强。
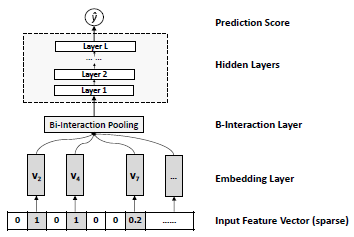
图:Neural Factorization Machine在FM进行二阶embedding交叉后,引入DNN进行更高阶交叉
Spatio&Temporal Net
指在NN的基础上,充分考虑推荐场景下Spatio&Temporal特征,此处空间时间维度的特征在不同场景下含义可以不一致,例如在论文《Deep Spatio-Temporal Neural Networks for Click-Through Rate Prediction》中,主要思想还是使用深度学习进行高维特征交叉。创新点在于该点击率模型同时考虑了空间关系和时间关系对点击率的影响。
该处的空间关系指即将展现的候选广告之前的作为上下文的广告,作为该ad的context,而该用户历史上点击过&未点击的ads则作为空间时序上用户的兴趣表达(该思想和DIN类似)
在具体实施时,文中使用了递进的三种模型:1,特征embedding后直接进行sum pooling;2,解决加入attention机制解决sum pooling带来的信息丢失问题;3,引入context和target的交叉解决context对多个广告不变的问题
总体文章的思路比较直接,最重要创新就是同时引入上下文和用户时间维度上的兴趣表达
总结
当前的CTR预估已经大规模使用深度学习,而且在工业界和学术界仍然在不断地有新的网络结构出现,所以不出意外这些新的网络结构的研究应该还能火两三年。但今年去加拿大参加NeuraIPS时发现一个趋势,就是很多研究人员,以及类似于Google这样的公司都在大力投入到AutoML中,也就是使用机器学习的方法,类似于搭积木似的去寻找最优化的网络结构(超参数)组合,所以会不会两三年后,网络结构的创新,会被AutoML所取代?这个不得而知
参考文献
- 《深度学习资料》
- 《lbs工业界eta应用及滴滴wdr技术》
- Practical Lessons from Predicting Clicks on Ads at Facebook[J]. 2014:1-9..
- Mcmahan H B , Holt G , Sculley D , et al. Ad click prediction:a view from the trenches[C]// Acm Sigkdd International Conference on Knowledge Discovery & Data Mining. ACM, 2013
- Cheng H T , Koc L , Harmsen J , et al. Wide & Deep Learning for Recommender Systems[J]. 2016.
- 3 Idiots’s Approach for Display Ads Challenge.
- 4 Idiots’s Approach for Display Advertising Click-through Rate Prediction.
- Guo H , Tang R , Ye Y , et al. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction[J]. 2017.
- Zhou G , Song C , Zhu X , et al. Deep Interest Network for Click-Through Rate Prediction[J]. 2017.
- Chapelle O. Modeling delayed feedback in display advertising[C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014: 1097-1105.
- Wang R, Fu B, Fu G, et al. Deep & cross network for ad click predictions[C]//Proceedings of the ADKDD’17. ACM, 2017: 12.
- Xiao J, Ye H, He X, et al. Attentional factorization machines: Learning the weight of feature interactions via attention networks[J]. arXiv preprint arXiv:1708.04617, 2017. He X, Chua T S. Neural factorization machines for sparse predictive analytics[C]//Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval. ACM, 2017: 355-364.