决策树是经典高效的机器学习分类算法, 非常适用于线性模型效果不能满足需求, 规则描述分布比较合适的场景。而决策树与传统bagging, boosting思想结合在一起, 就形成集成树模型方法, 包括Random Forest,GBDT等方法。 在百度搜索关键词搜索推荐系统策略中,实验证明集成树模型具有非常高的预估分类准确性。
决策树模型
举一个简单例子(引自公司pengzhiming同学的PPT): 老妈让自己相过多次亲的女儿再次去相亲, 女儿简单问了下对方的条件, 以判断是否去; 根据男方条件(特征)对去与不去进行分类的过程, 就是一个CART决策树。
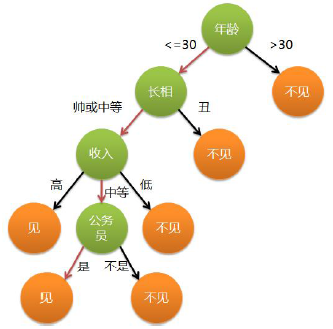
例如:

母女对话如下:
如果将女儿的历史相亲经历看成是训练样本(男方条件为特征,女儿到对方后觉得是否靠谱作为label),将女儿积累到现在的相亲经验则是一个CART模型: 根据老妈的描述,就可以判断出是否有必要去见男方。
当然, 决策树模型也可以再细分, 包括经典的ID3,C4.5, CART。 不同的决策树具有不同的树结构,以及不同的节点拆分算法及拆分标准。
树模型的优缺点
总体来说,树类算法都是使用贪心算法, 选择当前最合适属性进行拆分建立整棵决策树,该类模型比较适用于能够用复杂规则描述的应用场景。
以下为树模型的优点:
- 实现较为简单, 且容易实现并行化
- 训练速度较快, 且一般效果也比较好
- 能够处理离散连续值特征(和LR类似的模型相比), 不用对特征做归一化即能取得较好效果
- 能够处理缺失值
- 能够处理高维特征
- 训练完毕后, 能够给出哪些特征比较重要;而且很多情况下,即使最终使用其他模型, 也可以使用树模型选择特征
当然, 所有的模型都有其弊端:
- 树模型容易过拟合, 所以需要进行剪枝(以及使用后续将描述的集成学习方法解决)
- 不能表示复杂结构和运算: 树模型原则上天然表示‘与’操作, 所以不能表示类似于‘异或’的操作
因为树模型的以上优点, 树模型在很多场景均会被选用
树模型训练框架
以下为使用数据集D,属性(特征)集合attribute_list产生决策树的算法框架。该算法未包含任何剪枝。

以上伪代码中(2)~(5)行用来处理数据中都是相同label及无属性拆分的情况,剩余代码使用贪心算法选择最合适的属性后,进行拆分,并递归建立子节点。
在上述伪代码中涉及到attribute_selection_method逻辑, 也就是决策树节点拆分标准的问题。
树模型节点分裂标准
如上所述,决策树使用贪心算法进行拆分, 选择当前认为最优的拆分特征进行树节点的分裂。 这就涉及到选择何种属性作为拆分的标准。一般说来, 经常使用的树节点拆分标准主要有以下几类:
一般情况下, 在决策树中, 使用信息增益(information gain)作为节点分裂的选择标准。
要定义信息增益, 我们需要定义‘信息’,我们将信息定义为: 对于数据集合D,我们需要对D中的各种类别进行编码的字节编码数,即:
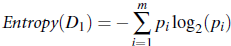
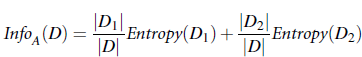
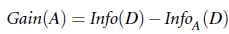
信息量, 也被称为熵(entropy),用于描述不稳定性或多样性。 对样本集合D中, 假设对于某一维度的特征, 该特征A有v种取值, 而每种取值对应的数据样本数为Dj, 则在知道了某属性A的各种取值,并将符合各v值得样本进行分类后, 需要将样本集合D完全分开所需要的信息量为:
其中Dj为符合每个A的取值(假设A为离散可数种取值)的子样本集合。infor(Dj)为完全划分子样本集合所需要的信息量。 此时可定义信息增益:
在ID3算法中, 使用信息增益进行分裂特征的选择, 算法会使用贪心算法选择信息增益最大的特征进行树节点的分裂。 但信息增益有一个缺点: 会选择有众多值的特征进行节点分裂, 极端情况, 对于ID类特征(利用用户ID, 或是item ID), ID的个数与待分类的样本数一样, 这样的分裂是没有意义的, 此时, 使用gain ratio作为节点拆分标准, 能避免该问题。
为了解决信息增益偏向于选择属性值较多的特征问题, 在c4.5中引入了gain ratio。 首先定义:
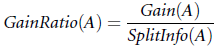
注意splitinfo_A 与info_A的不同: splitinfo的第二项受到的是符合特征A下每种取值的样本数量影响; info_A则受到特征A下每种取值的样本包含的信息的影响。注意参考entropy的定义, 当分布越是不均匀时, 描述这种状态所需要的信息量约小, 分布越是散时, 需要的信息量越大(info值越大), 所以当拆分特征的值越多时, splitinfo会越大。
此时我们定义gainratio, 分母为splitinfo 起到抑制拆分多值特征的倾向。
在CART中, 使用gini index作为节点拆分的标准, gini系数的定义如下:
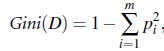
其中pi为样本集合D中各类的占比(总共有m类, pi=Di/D, 其中Di为D中属于类别i的的样本数量)
定义:
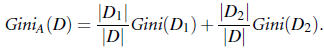
即使用属性A来对样本进行节点拆分后时的gini index, 此时可使用gini_A来对A进行拆分判定, 选择gini系数值下降最快的属性进行拆分。
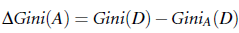
一般说来information gain,gain ratio, gini index就是最常使用的三种拆分指标。结合前述树模型构建方法, 再加上构建树的过程中/后的限定条件及剪枝, 即可构建出实际中高效的决策树。
集成学习方法
集成学习方法是将bagging,boosting思路与树模型结合的高效学习方法。
bagging的思路比较简单, 就是汇集多个模型进行投票, 每个模型的票的权重一样, 获得票数最多的预估类胜出, 该类获得的票数与总票数的比值可以作为置信度。 如果是回归问题, 则多模型预估值得平均值作为bagging结果。
boosting方法在bagging的思想上前进了一步: boosting在训练时会更在乎分类错误的样本, 给予分类错误的样本更高的权重训练模型, 并将这些权重不一的模型根据权重进行bagging。boosting更像是是医疗专家诊断病情一样: 诊断容易出错的病情正确率更高的专家的话语权更高。 具体adaboost的介绍可参见《adaboost》
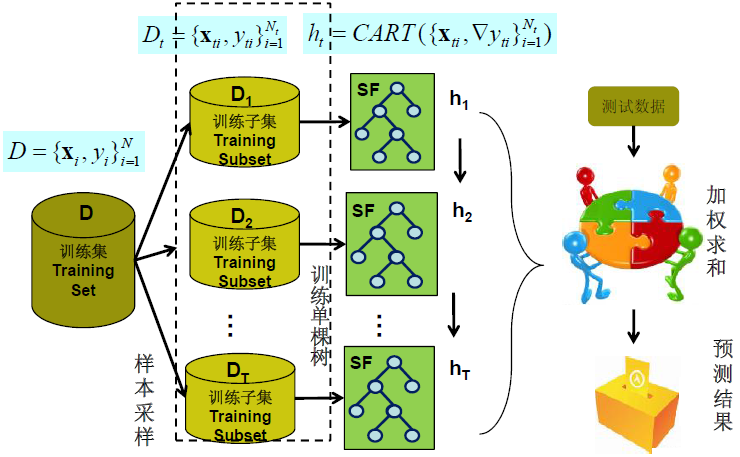
bagging方法, 特别是adaboost方法一般都会使用非常简单的弱分类器进行bagging和boosting, 随着计算机处理能力的增强, 可以使用更加复杂的模型进行bagging&boosting, 而过将弱分类器使用更加复杂的树模型, 就形成‘集成树模型’。比较常用的‘集成树模型’包括Random Forest和GBDT。

虽然单个树模型学习能力有限(拟合复杂的数据分布能力有限), 但多个树模型放到一起, 就能够高精度拟合出复杂的分布(如上图所示), 这就是集成学习的强大之处。
Random Forest(RF)是典型的bagging树模型的方法。 其思路就是使用随机的部分样本/特征构建树模型, 之后使用bagging思想进行分类。
RF不仅对特征集合进行采样, 同样也可以对样本进行采样, 例如在进行单个cart训练时, 对每个模型,随机使用这种方式一方面充分利用了所有样本, 特征的贡献, 另一方面, 又能避免部分噪音带来的过拟合。设置合适的样本随机采样率(例如0.6表示每个模型选择60%的样本进行训练)以及何时的特征随机采样率(例如0.6表示每个模型选择特征集合60%的特征进行训练)进行RF训练。

在进行分类时, 根据样本和特征抽样训练出来的模型使用bagging方法进行投票。
相对于boosting会依赖于前一模型分类正确or错误调整样本权值的思路, RF更容易实现并行化, 因为RF中各子树的训练过程是完全独立的不会相互影响。
Grandent Boosting(GB)是将梯度下降思路融入boosting方法中, 不同于传统boosting每一步对分错样本进行加权(或对分对样本进行加权),GB定义整个模型的损失函数。
算法的每一步沿着损失函数下降最快的方向建立新的模型,这样使得算法在每一步均沿着下降最快的方向收敛。 直到满足要求, 建立满足要求的若干组合加权子模型。
Gradient Boosting将问题进行建模,定义loss function为
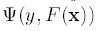
则对于训练样本集合{y, x}, 我们的任务是寻找最小化loss的函数F*(x):
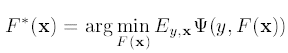
而gradient boosting的思路是将映射模型函数表示为以下形式:
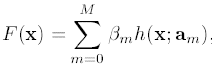
其中h(x;am)为简单函数/模型, am 为h的参数, 此时, belta, a, 就为我们要预估的最小化loss下的参数:
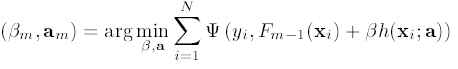
同时Fm与F_m-1的关系为

之后可以求belta和a序列参数, 求解过程如下:

在第i个样本点, 第m个模型里边的伪残差求解方法为:
要构建模型h(x,am), 最快的方法, 就是让所有的样本点处, 损失函数都沿着最快的方向下降。

也就是:
利用最小二乘法求解am后, 即可求解belta_m
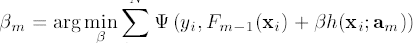
依次求解所有am, belta_m后, 即得到最终模型F*(x)
树模型在百度关键词搜索推荐中的应用及实验结果
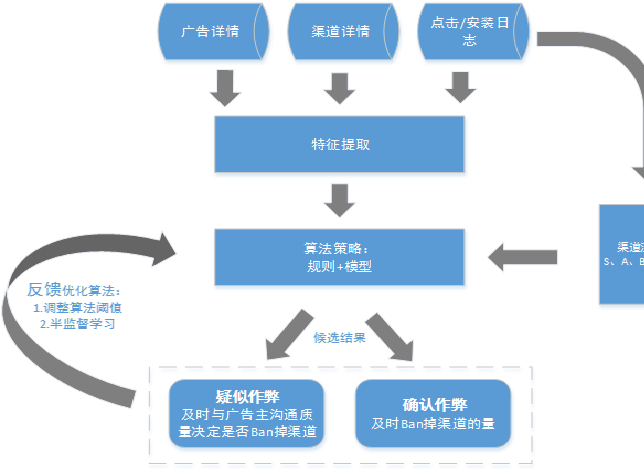
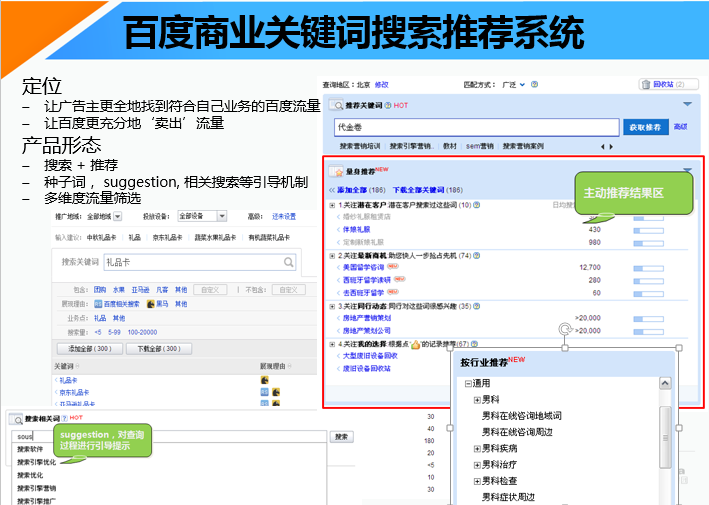
当然, 很多时候我们不会直接去修改模型, 在应用中, 更多地是使用模型作为工具解决具体问题。 例如在百度关键词搜索推荐中, 我们更多是构建相关性判断的特征样本, 之后对模型参数进行搜索: 例如样本采样率, 特征采样率等参数。 具体效果参见实验部分。百度关键词搜索推荐介绍及交互流程参见《百度关键词搜索推荐系统交互流程》
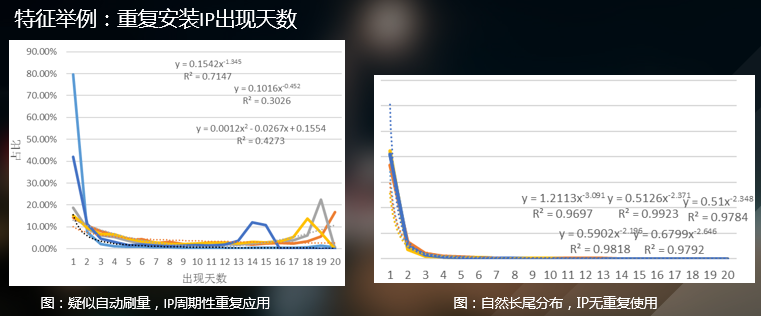
一下为具体应用标注负样本示例,例如‘水仙花’, 从搜索引擎商业价值角度考虑, 是具体描述水仙花这个商品, 而不一样是信息型舞蹈名字query'紫蝶广场舞水仙花开':
具体GBDT在百度关键词搜索推荐中, 相关性判断的应用方法(包括特征选取和实验结果), 参见《分类模型在关键词搜索推荐中的应用》, 使用树模型, 在没有任何样本,特征调整的情况下, 准确性直接提升了5个点 ,效果惊人。
同时, 正如前述: 树模型还有一个显著优点, 就是在模型建立时, 能够清晰分析出哪些特征对分类贡献大, 哪些对分类影响小(常用的指标包括特征的贡献度, 特征在分裂时的使用频率), 一般情况下特征贡献度和特征使用频率均是越大越好。 例如百度关键词搜索中, 对关键词相关性模型(使用分类模型判断两个关键词是否相关)使用17维特征。 使用Random Forest保留贡献最高的5维特征时, 在交叉验证情况下, 准确性基本保持不变, 召回也就下降1个百分点。
而在排序任务重, 使用衍生GBrank对百度关键词搜索推荐结果进行排序, 一般情况下,效果随着树的深度增长而提升, 但树深度达到8后, 就不再提升。


随着叶子节点书的增长, 效果仍然在提升, 所以在应用中,如果效率允许, 可以让最大叶子节点数多一些。
在实际应用中, 理论上可以对众多参数进行全参数搜索, 找到最优参数。 实际应用中会快速找到比较好的参数后, 策略即上线进行实验。
参考文献:
- Friedman J H. Stochastic gradient boosting[J]. Computational Statistics & Data Analysis, 2002, 38(4): 367-378.
- Quinlan J R. Induction of decision trees[J]. Machine learning, 1986, 1(1): 81-106.
- Breiman L, Friedman J, Stone C J, et al. Classification and regression trees[M]. CRC press, 1984.
- 分类模型在关键词搜索推荐中的应用
百度关键词工具介绍参见:http://support.baidu.com/product/fc/4.html?castk=24b18bi7062c720d0d596
也可关注我的微博: weibo.com/dustinsea
或是直接访问: http://semocean.com