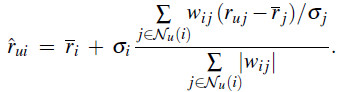在设计实现推荐系统,选择推荐算法时, 肯定会考虑协同过滤(CF)的使用,而CF中经常使用的两种方法包括: neighbour-based方法和因式分解。 作为一个搜索推荐系统,百度关键词系统中也使用了CF(包括neighbour-based和因式分解方法)为用户推荐流量,考虑到可解释性和工程上在hadoop上实现的便利性,最终主要使用了neighbour-based中的item-based方法。但学术上,因式分解会从全局考虑用户投票的影响,所以理论和实践上效果都会更好。本文主要结合之前对因式分解的调研理解及调研demo代码, 介绍因式分解实现协同过滤的方法, 同时感兴趣的同学可以下载源码及MovieLens数据进行实验。
注:
为了方便理解, 以下介绍均使用MovieLens 100K数据进行介绍(公司数据太大, 且包含过多预处理过程, 同时涉及泄密,你懂的:)
文中的代码可从文章最后的参考内容链接中下载。
推荐算法对比基线的建立
要评估一个策略的好坏,就需要建立一个对比基线,以便后续观察算法效果的提升。此处我们可以简单地对推荐算法进行建模作为基线。假设我们的训练数据为: 三元组, 其中user为用户id, item为物品id(item可以是MovieLens上的电影,Amazon上的书, 或是百度关键词工具上的关键词), rating为user对item的投票分数, 其中用户u对物品i的真实投票分数我们记为rui,基线(baseline)模型预估分数为bui,则可建模如下:
其中mu(希腊字母mu)为所有已知投票数据中投票的均值,bu为用户的打分相对于平均值的偏差(如果某用户比较苛刻,打分都相对偏低, 则bu会为负值;相反,如果某用户经常对很多片都打正分, 则bu为正值), bi为该item被打分时,相对于平均值得偏差。 bui则为基线模型对用户u给物品i打分的预估值。该模型虽然简单, 但其中其实已经包含了用户个性化和item的个性化信息, 而且特别简单(很多时候, 简单就是一个非常大的特点, 特别是面对大规模数据时)
基线模型中, mu可以直接统计得到,我们的优化函数可以写为:
其中参数lambda1及之后的式子是为了防止过拟合产生。 其中rui为已知的投票, mu可直接统计, 对每个用户的参数bu, 对每个item的bi可求(相当于AX=B,求X,此处X即为bu, bi,可使用最小二乘法, 例如可使用Numerical Recipes: The Art of Scientific Computing中提供的优化函数) ,当然, 最简单的方法就是直接根据当前的观测值, 直接统计出bu 和bi, 统计方式如下:
其中lambda2, lambda3为手动设定参数(在MovieLens上为20左右效果比较好, 才参数相当于降低投票较少的用户, 以及被投票较少的item对整体预估效果的影响), R(u)为用户u投了的item的rating集合,R(i),为投票给item i的rating集合。
基线实验结果
还有一种更简便的方法, 就是直接使用user,item的rating的平均值直接预估bi,bu,例如直接计算bu = sum(Ru)/len(Ru),其中Ru为用户u投票的集合, sum(Ru)为这些rating值得和, len(Ru)为该集合大小。bi = sum(Ri)/len(Ri), 其中Ri为用户i被投票的集合, sum(Ri)为这些rating的分值之和, len(Ri)为这个集合的大小。我们将此方法记为baseline1,上文描述的方法记为baseline2。 以下为两种方法在不同lambdau,lambdai值下的具体表现(其中两个lambda值在实际应用中可以根据代价进行全空间搜索最优解), 具体分值代表RMSE。
图: 两种基线的RMSE效果表现
可以看到,随着lambdai和lambdau的增长, 两种方法的RMSE均在下降, 且效果上, baseline2 优于baseline1。
基线源代码
源码文件对应为RecBaseLine.h,其中RecBaseLine封装了baseline1的实现, RecBaseLineAdv封装了baseline2策略的实现, 而每个推荐算法均继承自RecTask, 所有每个推荐算法除了接受该算法特有的参数外,还必须提供以下接口。
其中代码在上传时添加了部分注释。
因式分解实现协同过滤
上文中实现的两种基线算法,仅仅孤立地去考虑user, item的投票偏差, 并没有将二者建立内在联系。此时我们可以对这种内在联系通过隐主题进行建模。 最经常使用的方式莫过于SVD。
以MovieLens电影推荐为例,SVD(Singular Value Decomposition)的想法是根据已有的评分情况,分析出评分者对各个因子的喜好程度以及电影包含各个因子的程度,最后再反过来根据分析结果。
使用SVD对问题进行建模
SVD的想法抽象点来看就是将一个N行M列的评分矩阵R(R[u][i]代表第u个用户对第i个物品的评分),分解成一个N行F列的用户因子矩阵P(P[u][k]表示用户u对因子k的喜好程度)和一个M行F列的物品因子矩阵Q(Q[i][k]表示第i个物品的因子k的程度)。用公式来表示就是
R = P * T(Q) ,其中T(Q)表示Q矩阵的转置
下面是将评分矩阵R分解成用户因子矩阵P与物品因子矩阵Q的一个例子。R的元素数值越大,表示用户越喜欢这部电影。P的元素数值越大,表示用户越喜欢对应的因子。Q的元素数值越大,表示物品对应的因子程度越高。分解完后,就能利用P,Q来预测Zero君对《七夜》的评分了。按照这个例子来看,Zero君应该会给《七夜》较低的分数。因为他不喜欢恐怖片。
图: 推荐问题的因式分解建模
实际上,我们给一部电影评分时,除了考虑电影是否合自己口味外,还会受到自己是否是一个严格的评分者和这部电影已有的评分状况影响。例如:一个严格评分者给的分大多数情况下都比一个宽松评分者的低。你看到这部电影的评分大部分较高时,可能也倾向于给较高的分。在SVD中,口味问题已经有因子来表示了,但是剩下两个还没有相关的式子表示。因此有必要加上相关的部分,提高模型的精准度。改进后的SVD的公式如下:
其中mu表示所有电影的平均分,bu表示用户评分偏离mu的程度,bi表示电影评分偏离mu的程度,P,Q意思不变。特别注意,这里除了mu之后,其它几个都是向量。其中qi, pu的维度, 就是隐主题的维度。
分解完后,即(1)式中的五个参数都有了正确的数值后,就可以用来预测分数了。假设我们要预测用户u对电影i的评分:
加入了防止过拟合的lambda参数后, 我们的优化函数为:

有了这个优化目标函数后, 就可以使用较多的手段来进行优化了。
以下主要使用梯度下降法解优化目标函数。具体的公式推导可参见论文。同时还可以使用ALS算法进行求解(该方法已经融合进mahout,后续会有专门文章对该算法进行介绍并给出实验结果)
最终推导出的求解公式为:
在实现时, 设定最大的迭代次数, 以及收敛的误差, 即可经过迭代球接触bu, bi, qi, pu
因式分解同过滤代码实现
因式分解的实现使用了RecTask, 故封装使用了一致的接口。具体感兴趣的同学可直接review source code
图:使用梯度下降求解因式分解CF推荐。
因式分解CF效果对比
此处就仅给出两组程序直接运行出来的结果及对应参数, 可以看到, 在latent factor的维度为30, 设定gama和lambda后, RMSE就降低至0.903105,效果比较明显。
以下为具体配置参数:
task:SGD30,mae:0.687782,rmse:0.903105
mu:3.528350,lambda:0.200000,gama:0.020000,min_res_err:0.010000,max_iter_num:10000,fea_dim:30
上文描述算法的hadoop版本未上传网盘, 如感兴趣可以邮件沟通。
参考文献:
Koren Y. Factorization meets the neighborhood: a multifaceted collaborative filtering model[C]//Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2008: 426-434.
Zhou Y, Wilkinson D, Schreiber R, et al. Large-scale parallel collaborative filtering for the netflix prize[M]//Algorithmic Aspects in Information and Management. Springer Berlin Heidelberg, 2008: 337-348.
Bell R, Koren Y, Volinsky C. Modeling relationships at multiple scales to improve accuracy of large recommender systems[C]//Proceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2007: 95-104.
Shapira B. Recommender systems handbook[M]. Springer, 2011.
MovieLens数据集: http://grouplens.org/datasets/movielens/
文中描述算法代码实现及评测框架参见:http://pan.baidu.com/share/link?shareid=2198676312&uk=1493671608
也可关注我的微博: weibo.com/dustinsea
或是直接访问: http://semocean.com