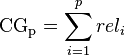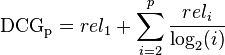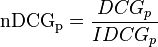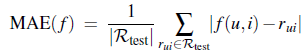推荐系统涉及到前端交互设计,后台算法选取优化, 所以在设计推荐系统时,不能单纯使用accuracy对推荐效果进行衡量,需要根据推荐系统的具体应用场景,使用对象,解决的问题使用多指标对其进行衡量。而且很多时候这些指标都是一个上涨其他跌,需要彼此间做权衡(例如在设计百度关键词推荐引擎时,就需要在关键词的召回和准确性之间进行权衡,同时要考虑用户操作的便利性,推荐关键词的多样性等)。 下边就对这些指标进行介绍:
User Preference
用户是否喜欢该RS(Recommender System)的设计。最简单的方法就是让用户选择, 实验那种算法/交互设计用户更喜欢, 然后被投票较多的一种胜出。
中间会涉及几个问题:
- A算法和B算法比,假设A算法胜出了, 而投票给A的人相对于B只是稍微喜欢A一点点。 但投票给B的人却非常不喜欢A,则这种情况下,有可能最终仍然需要选择B。
- 每一票的权重,也可能是不同的,例如在百度关键词推荐系统中,消费较高,买词较多的客户相对于新客户更专业,他们的选择一般更科学,说以权重需要高一些。
Prediction Accuracy
很多推荐算法都是基于数据挖掘或是机器学习, 所以很多时候, 也会使用数据挖掘和机器学习的accuracy衡量标准。我们可以简单粗暴地默认accuracy越高, 推荐算法的效果越好。
推荐算法中可以将accuracy的衡量标准分为3类:
- Rating Prediction
- Usage Prediction
- Accuracy of Ranking Items
Rating Prediction
例如在Netflix,douban中预测user对某个item(电影or音乐)的打分,为了评估算法预测的效果及偏差,可以使用RMSE(Root Mean Squared Error)或MAE(Mean Absolute Error)进行评估。数值越大表示偏差越大。
Usage Prediction
例如在百度关键词推荐引擎中, 更多需要考虑的是推荐出候选关键词后, 客户是否采纳该关键词(use),此时就不适合使用RMSE或是MAE进行衡量了。该场景下使用经典的Precision/Recall方式衡量更为合适,即一方面需要考虑推荐结果是否合适,另外一方面也需要考虑是否所有适合该客户该场景的结果都被推荐出来。
Precision=tp/(tp+fp)
recall=tp/(tp+fn)
更多时候可以直接使用AUC进行衡量刻画
Ranking Measures
例如在百度关键词推荐系统中,推荐出来的结果是关键词的list,排在前边的结果用户更容易看到,用户选择的代价也就更小,所以需要尽可能将更相关的结果往前排。此时就需要使用Ranking的标准衡量推荐结果list的结果。
Coverage
即推荐的覆盖率, 最简单的方法就是评估推荐系统推荐的item占item全集的比例,同时评估推荐系统能够推荐给总用户的比例。 例如电商有100W种商品,推荐系统能够覆盖80W, 则可以简单地认为该推荐系统的Coverage为80%;又如网站用户为100W,推荐系统能够覆盖50W用户,则可以简单定义用户覆盖面为50%
该方式的缺点显而易见: item有重要和不重要,热门和长尾的区分,例如,在国外,哈利波特深受大家喜欢,该书/音像制品的关注度非常高,该商品被购买的概率较大,所以推荐一个哈利波特后被购买的概率, 可能是推荐一个冷门商品的N倍(例如推荐一个了冷门的‘舵机’),所以在计算Coverage的时候,需要考虑item的冷热程度。
例如在百度关键词推荐系统中,我们可以简单地考虑推荐系统所能覆盖的关键词数量的比例,但其实考虑推荐关键词所能覆盖的pv的比例,更合理。 或者在专门推荐长尾流量的出口使用关键词数量覆盖比例。
推荐用户所能覆盖的比例也是一个需要慎重考虑得问题: 一般情况下,有些客户是不适宜覆盖的,例如新用户的profile还没有建立的时候,过早地对其进行推荐,虽然覆盖率上去了, 却不能保证正确性。 所以经常需要在准确性和覆盖率上做权衡(例如不同的应用场景可以选用不同的覆盖率,准确性标准, 或是在交互上进行提示,告诉用户:仅供参考)
Confidence
推荐的置信度,很多时候,使用模型方法时,都可以产生一个置信度, 我们甚至可以根据置信度, 选择推荐样式, 或是是否展现结果给用户。 例如,当系统产生一个置信度较低的结果时,可以选择不进行推荐。
Trust
即:能否博取用户的信任。需要从心理学的角度去进行设计,例如推荐时可以掺杂一些确信的用户喜欢的item,或是推荐的时候写明推荐的理由(这点非常重要,就是‘给一个理由先’, 给了理由,说服力立马倍增)
但Trust很难定量衡量, 更多是进行调研得到调研分析结果。
Novelty
什么是Novelty?所谓Novelty,就是需要推荐新的东西,用户已经关注,已经购买的东西,再推荐就没有多少价值了。 举个例子,我经常上amazon.cn买东西,但之前经常发现一个问题: 我要买一口炒锅, 浏览了很多炒锅相关的item,之后下单买了口爱仕达的炒锅, 回头再上amazon的时候,他竟然仍然向我推荐各种品牌的炒锅。 这就是Novelty做的不好。
Serendipity
就是要推荐一些有惊喜的东西,例如我经常看某一个演员的电影,推荐系统给我推荐一部该演员演的我没看过的电影,算是Novelty; 如果给我推荐一部不是该演员演的但是风格和这些电影类似的电影,就属于Serendipity。
一个比较特别的的例子:
“假设一名用户喜欢周星驰的电影,然后我们给他推荐了一部叫做《临歧》的电影(该电影是1983年刘德华、周星驰、梁朝伟合作演出的,很少有人知道这部有周星驰出演的电影),而该用户不知道这部电影,那么可以说这个推荐具有新颖性。但是,这个推荐并没有惊喜度,因为该用户一旦了解了这个电影的演员,就不会觉得特别奇怪。但如果我们给用户推荐张艺谋导演的《红高粱》,假设这名用户没有看过这部电影,那么他看完这部电影后可能会觉得很奇怪,因为这部电影和他的兴趣一点关系也没有,但如果用户看完电影后觉得这部电影很不错,那么就可以说这个推荐是让用户惊喜的。这个例子的原始版本来自于Guy Shani的论文”
简单地说,就是让用户感觉到‘毫无理由地’喜欢
以上例子内容来自于项亮同学所著《推荐系统实践》
Diversity
最经典的例子, 在百度上搜索关键词‘苹果’,如果我们认为用户大概率是要搜手机相关的内容就不出水果的搜索结果, 那就是一个diversity较低的例子; 又如旅游推荐时,如果都是推荐一个地方的同类旅游景点时,也是diversity的一个反例,当然diversity很多时候需要和precision做trade-off
Utility
即推荐系统的效用。效用可以从两个角度考虑: 推荐系统对用户的效用及推荐系统对网站(owner)的效用,从两个角度来看,可能会得到不同的结果。 以百度关键词推荐系统为例,从用户的角度看,我们需要推荐和用户推广意图相关的关键词, 且这些关键词能够带来最高的ROI;而从百度的角度看,推荐的关键词应该带来最大的消费(至少短期的衡量标准是这样,长期考虑还是需要提升用户的ROI),针对不同的效用就需要建立不同的模型。
例如从公司的utility考虑,需要建立题词率模型(最大化推荐结果的采用率模型)及点击率模型; 从用户的角度,需要建立模型最大化ROI。 一般系统都是综合考虑这些效用决定最终结果。
也可关注微博: weibo.com/dustinsea
或是直接访问: http://semocean.com