Applying Deep Learning for Airbnb Search engine
该文章是KDD 2019上发表的Airbnb的搜索引擎主要算法的文章,主要介绍了Airbnb算法的演进历程。还是Airbnb一贯的朴实无华的风格:不在乎有多少创新,更多是工业界结合业务上的算法工程,该文章很难的是文章中不仅介绍了Airbnb的算法,以及使用该算法的出发点和考虑,同时还记录了中间的各种坑,甚至一些失败的实验,真的是经验的无私分享,写作手法更像各大厂内网的技术总结分享文章。对于广大研发有较强的借鉴作用。
再具体到技术细节,Airbnb的场景是低频,且作为平台需要同时考虑需求侧(用户/网民)同时还要考虑供给侧(Airbnb中是民宿),另外民宿预订有很强的地理位置属性,所以文中的算法对于低频场景,LBS场景的搜索推荐都有较强的借鉴意义。低频场景例如飞猪,携程,马蜂窝的酒店,旅游预订;LBS属性例如Google Map,百度地图,高德地图等场景。
Abstract
搜索引擎一直都是airbnb成功的重要的因素,之前的实现主要是使用树模型来实现核心的算法,但是出现了瓶颈,所以后来airbnb就使用深度学习来优化其搜索引擎。
本文不会针对深度学习的算法进行创新,更多的是在使用深度学习的构建核心引擎中的一些细节的探讨。bon voyage
Introduction
搜索场景是airbnb的重要的场景,最开始系统使用的是人工的打分函数。之后使用gbdt进行特征的组合,这是一个比较大的进步,并且经过了比较多的迭代。现在开始转移到深度学习。
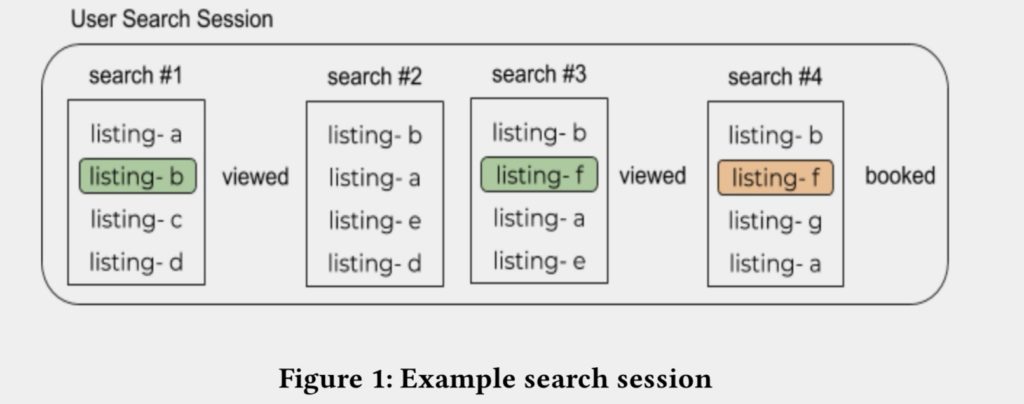
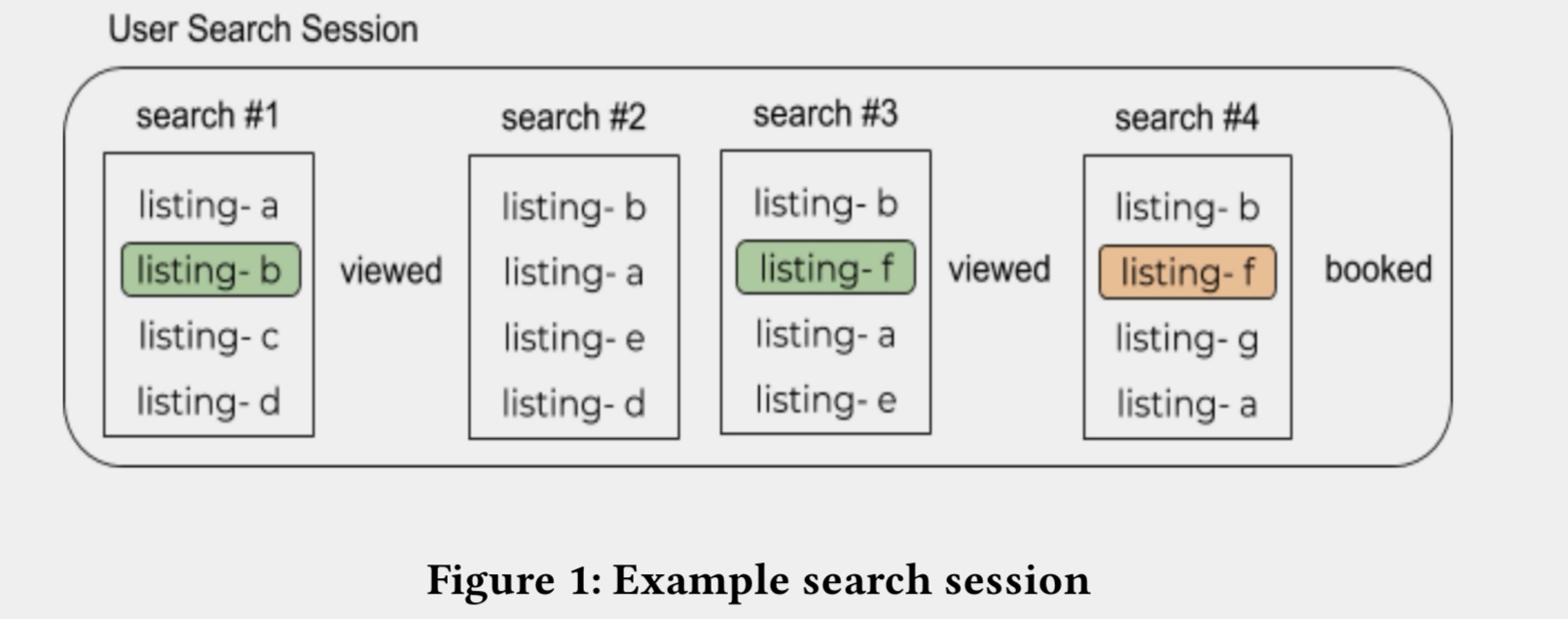
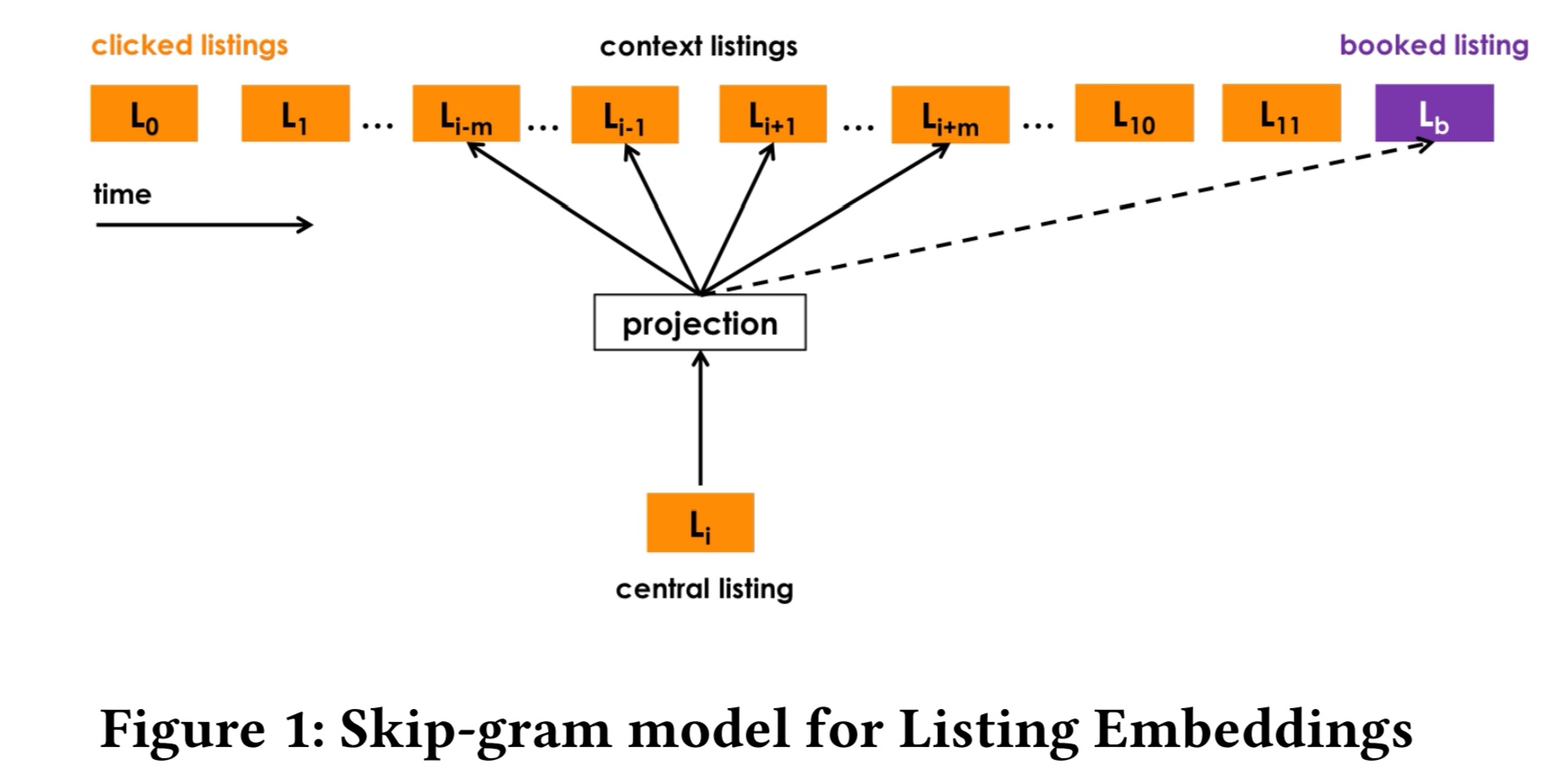
图:搜索session示例
典型的搜索引擎,在用户看了一系列的listing(相当于其它文章中的item)之后,完成了booked的工作。
系统运行中间的日志都被记录下来,之后使用离线的方式训练新的模型模型,尽量的将booked的listing的排序排到最靠前。之后在线上使用ab test的方式进行验证。
本文叙述的方式是从feature engineering和system engineering的方式进行的介绍。最后再对内容进行回顾。
Model Evolution
模型的迭代也是一步接一步的。深度学习是顶峰的表现,是最终逐步迭代后的结果,过程中也走了很多弯路。
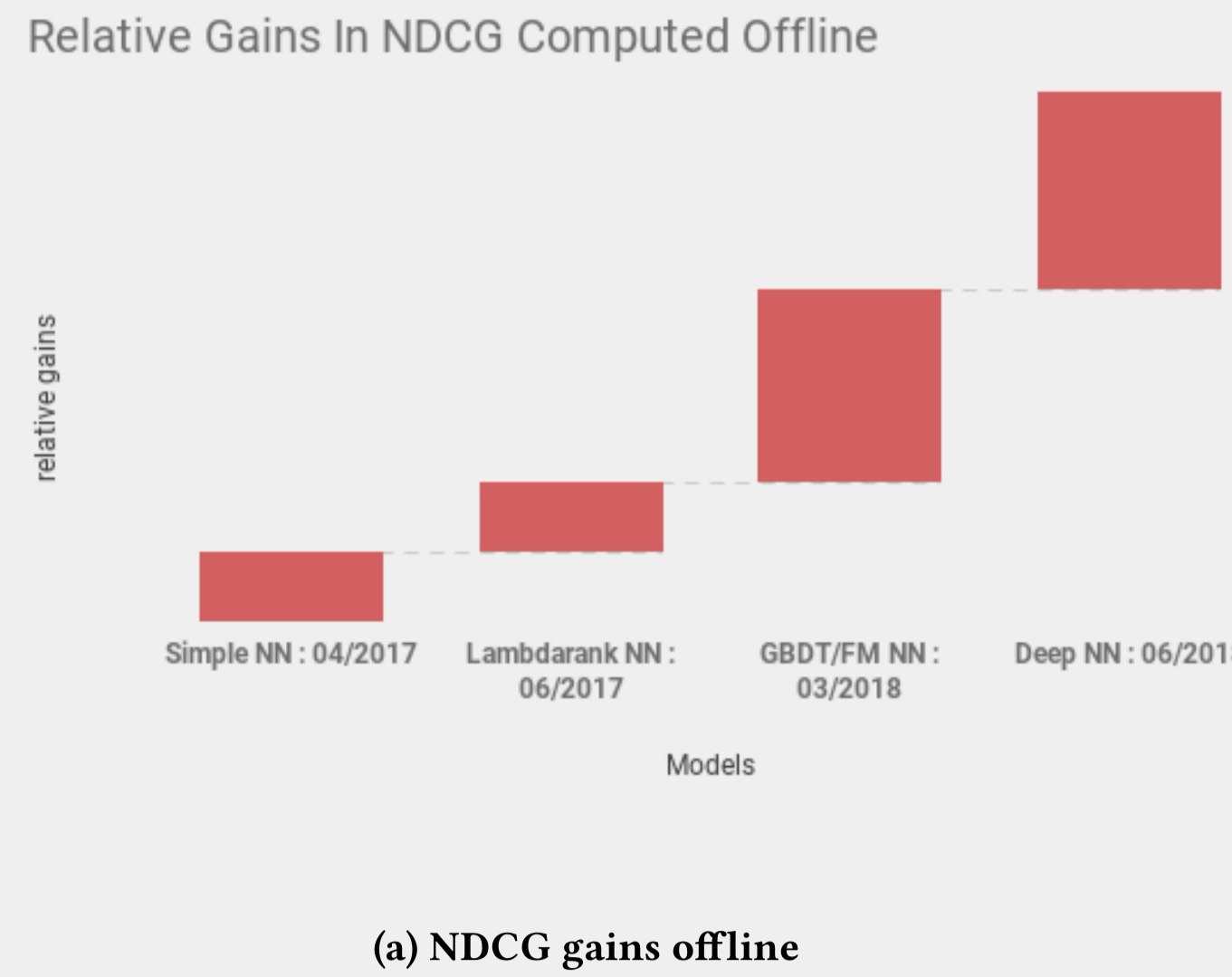
图:展示了在各个模型迭代上离线ndcg的提升幅度:
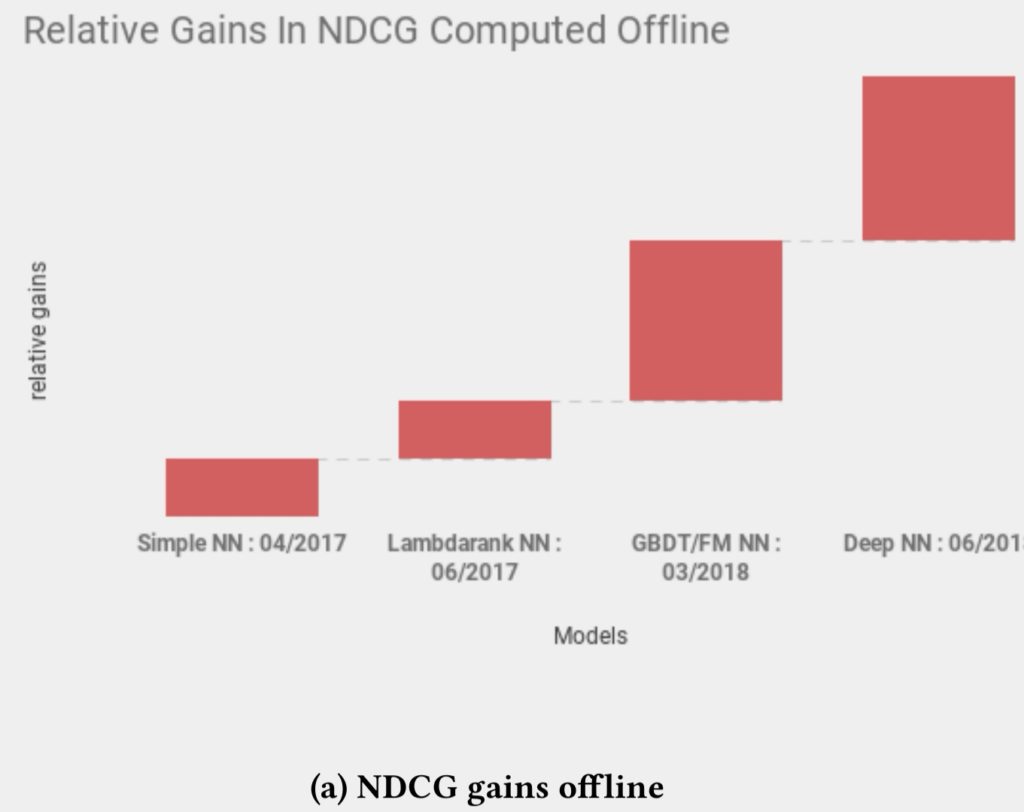
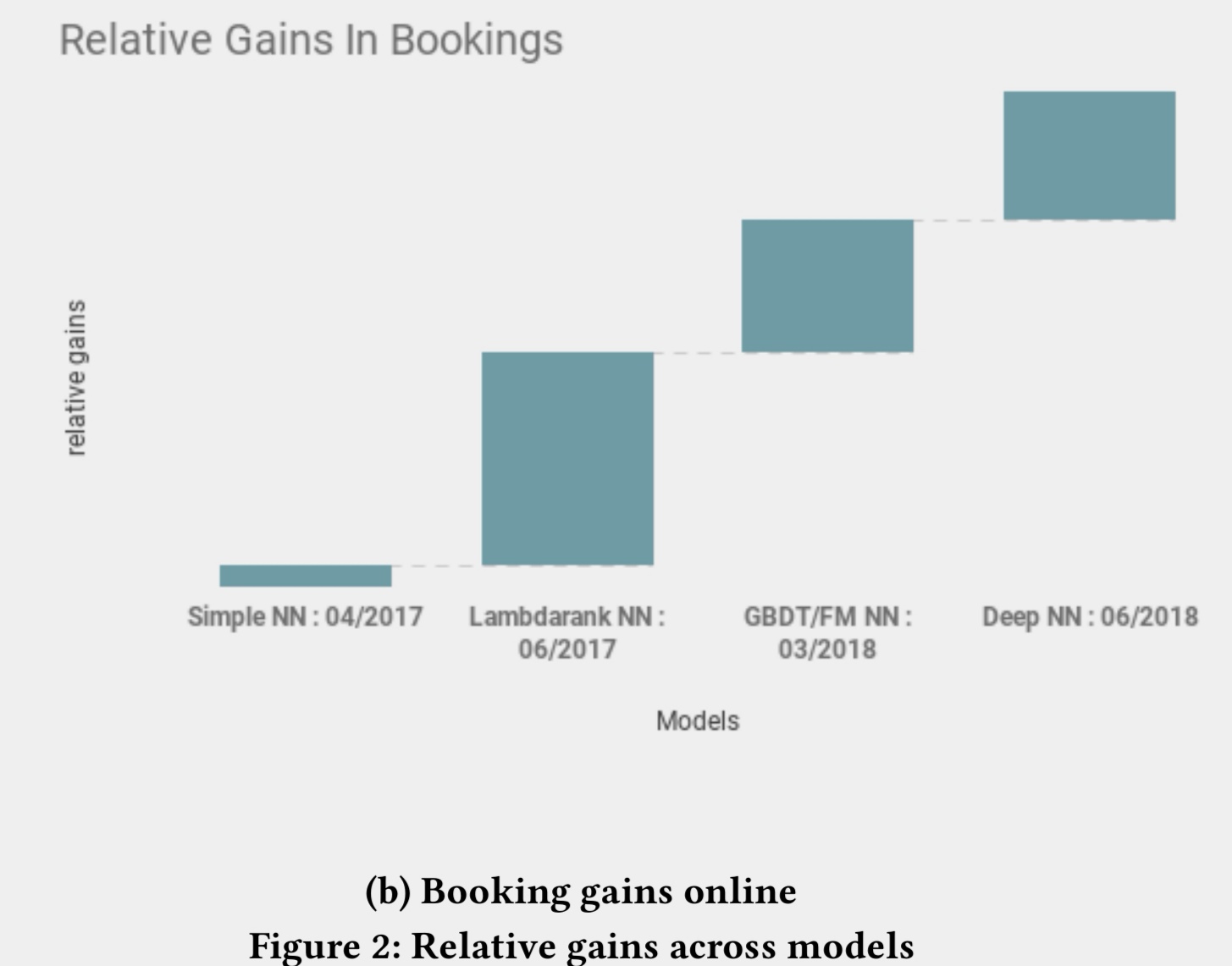
图:展示了各个模型在线转化的相对提升幅度:
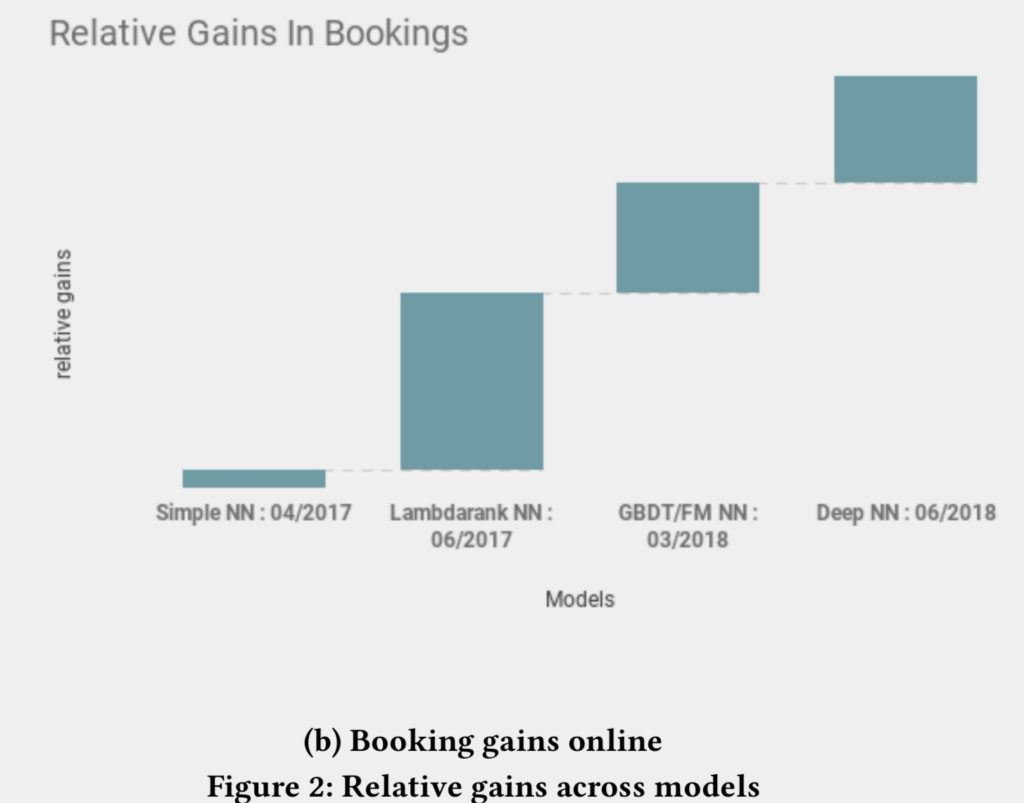
Dustinsea: 可以看到,在全面DeepNN前,就已经拿到了比较多的受益,DeepNN让效果更上一层楼
第一阶段:simple NN
论文12提到don't be a hero,但是我们一开始就从复杂的nn模型出发,到最后只是得到了复杂结构,还有花时间的循环。
在nn上也也花了比较多的时间,gbdt模型输出作为nn模型的输入。该过程最重要的贡献,就是把特征的pipeline给建立起来。
第二阶段:lambdarank nn
使用lambda rank,直接对离线的ndcg进行优化。
第三阶段:gbdt/fm nn
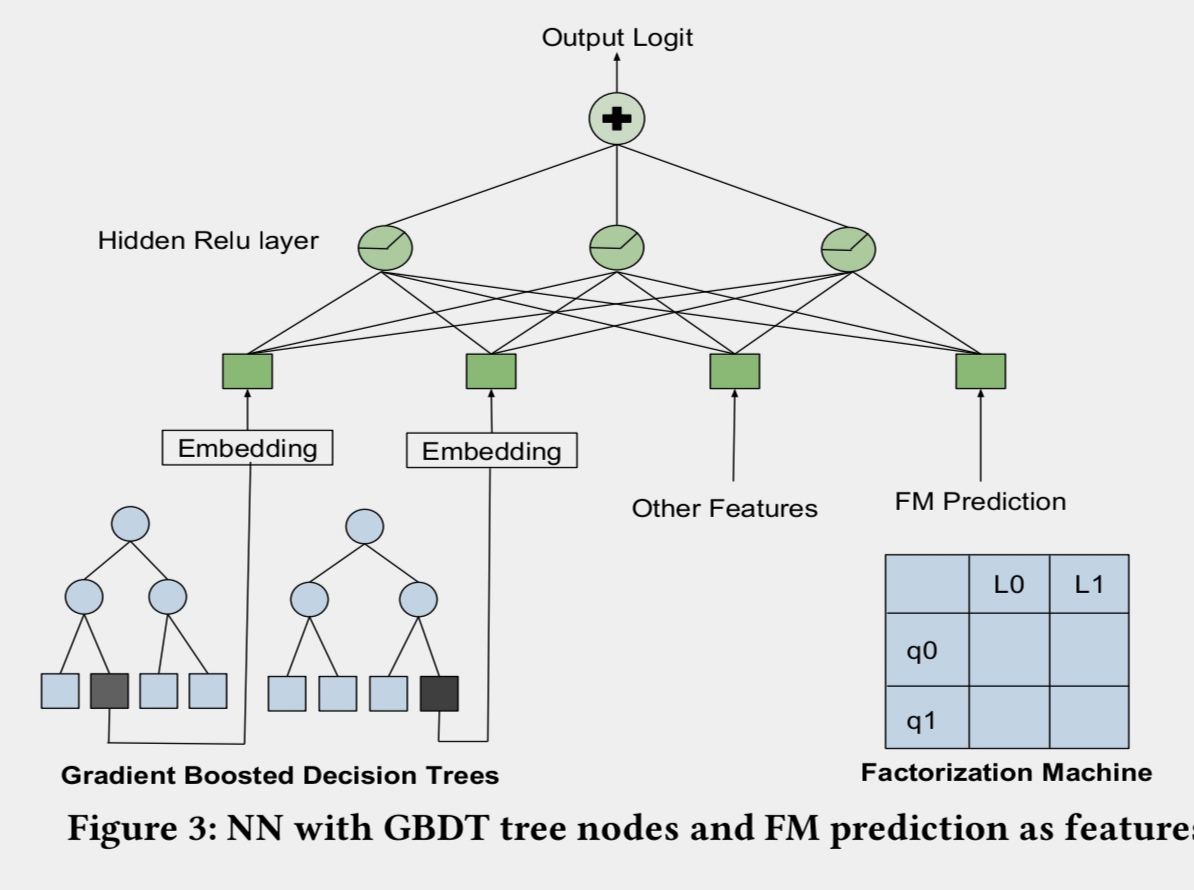
gbdt作为另外一条线,在进行优化中间发现一个有意思的现象:从指标上gbdt的效果和nn的效果比较类似,但是他们排序出来的结果是不一样的。受这一现象的启发,将gbdt/fm和nn的架构进行了融合,FM的最终输出直接作为nn的特征,同时树模型的节点index作为nn的特征输入(和2014年facebook发表论文中gbdt+lr的思路异曲同工)。模型结构图如下:
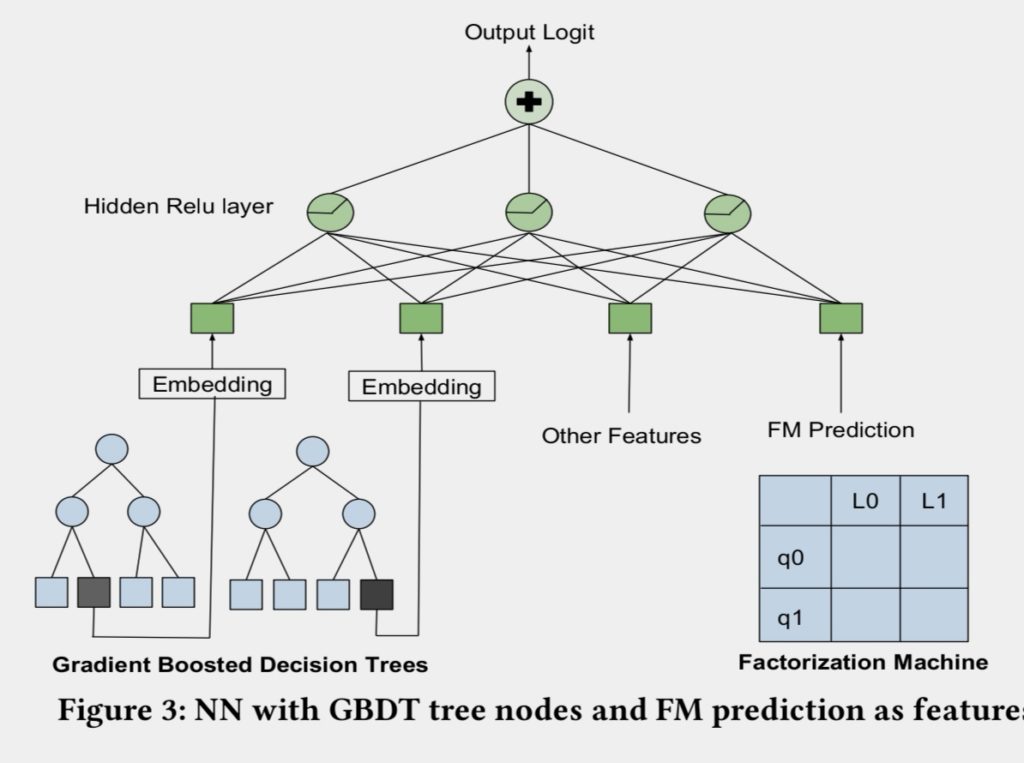
图:NN和GBDT模型融合方法示例
第四阶段:DEEP NN
模型
最终使用具有两个隐藏层的nn。配置如下:

特征
大部分的特征都直接进行输入,没有进行太多的feature enginering,少部分的特征作为其他模型的输出,会进行特殊的处理。
price特征:使用模型进行处理。
similarity features:使用功现的embedding进行处理。
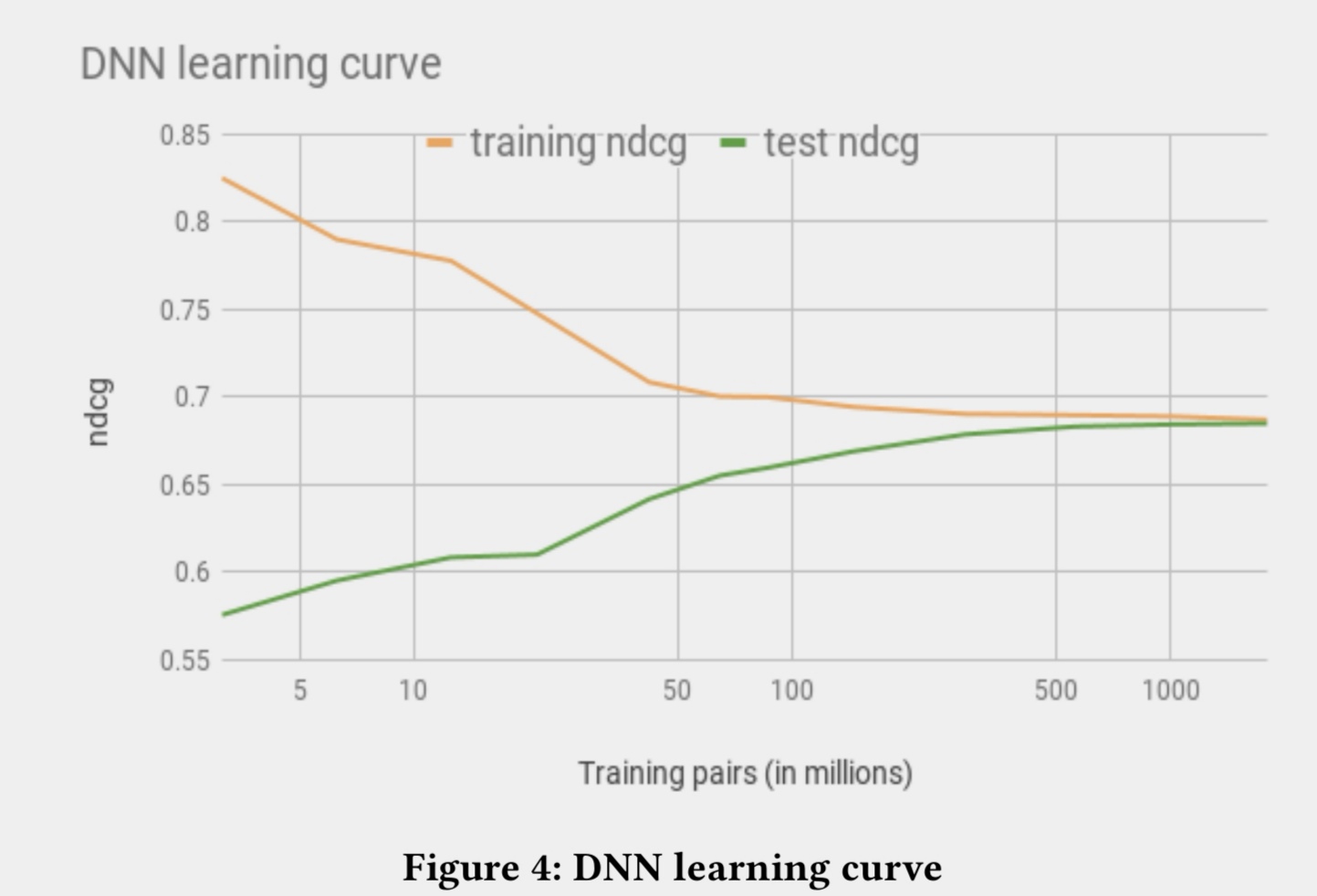
使用17亿样本进行训练,以ndcg作为评估指标的情况下,能够达到收敛的效果。
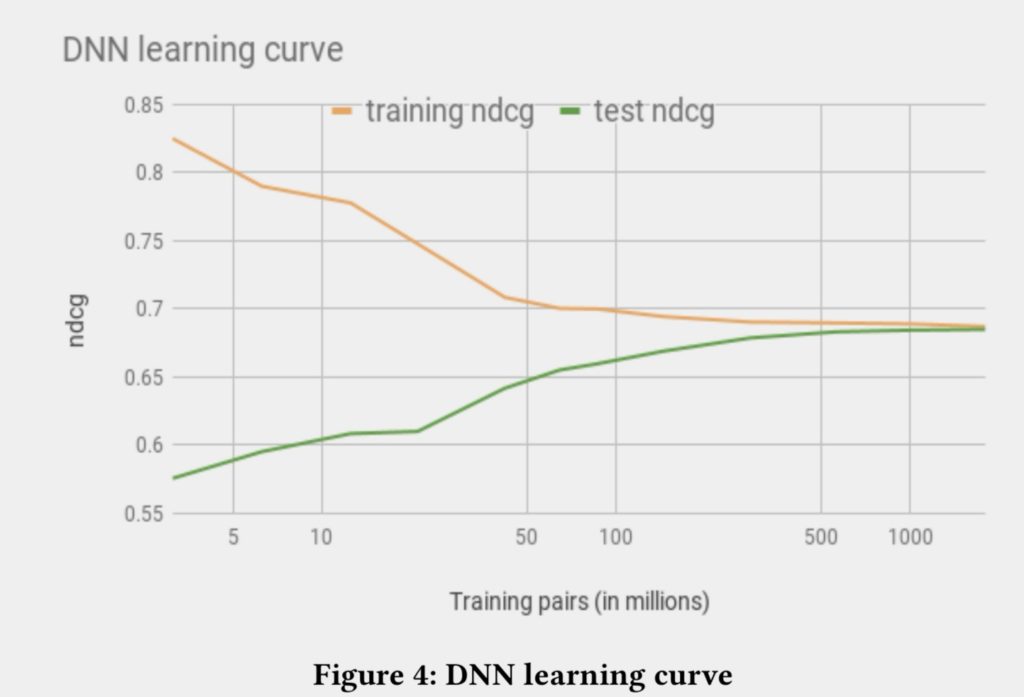
在评估过程中一个非常困难的点就是我们如何评判模型的结果和人的认知评判的结果的效果的对比。在图像中人是可以作为一个评判标准的绝对增值进行评价的,但是在我们的数据里边却看不出来绝对的增值,因为这些绝对的因素都是隐藏的比较深的。这和video或者audio领域不一样。
失败的模型
一般大家在叙事的时候都是在讲成功的案例,但这其实只是整个过程的很少的一部分,下面就向大家介绍一下失败的尝试,因为失败的尝试比较多,所以这个地方挑了两个模型。

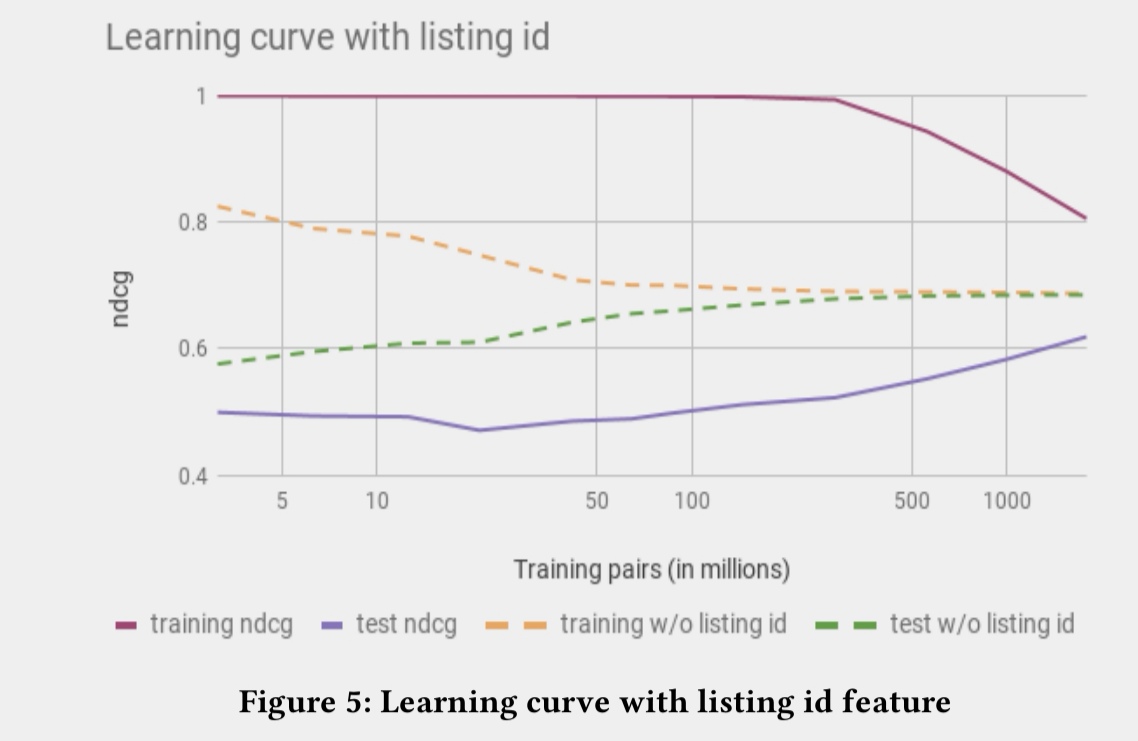
第一种失败尝试:直接使用listing ids embedding
在nlp中或者电商视频推荐中,对于item的embedding使用是比较成熟的,并且证明效果比较好。但在airbnb的环境中,因为数据量比较稀少,就算最火的民宿一年也只能有365个预定,更多的民宿数据都是非常少的,所以很难学出稳定的embedding,基本上都是Over fitting,所以listing ids使用会失败。
Dustinsea:所以Airbnb进行embedding的时候,更多是对人群/POI群进行embedding,而非用户/单个POI进行embedding.
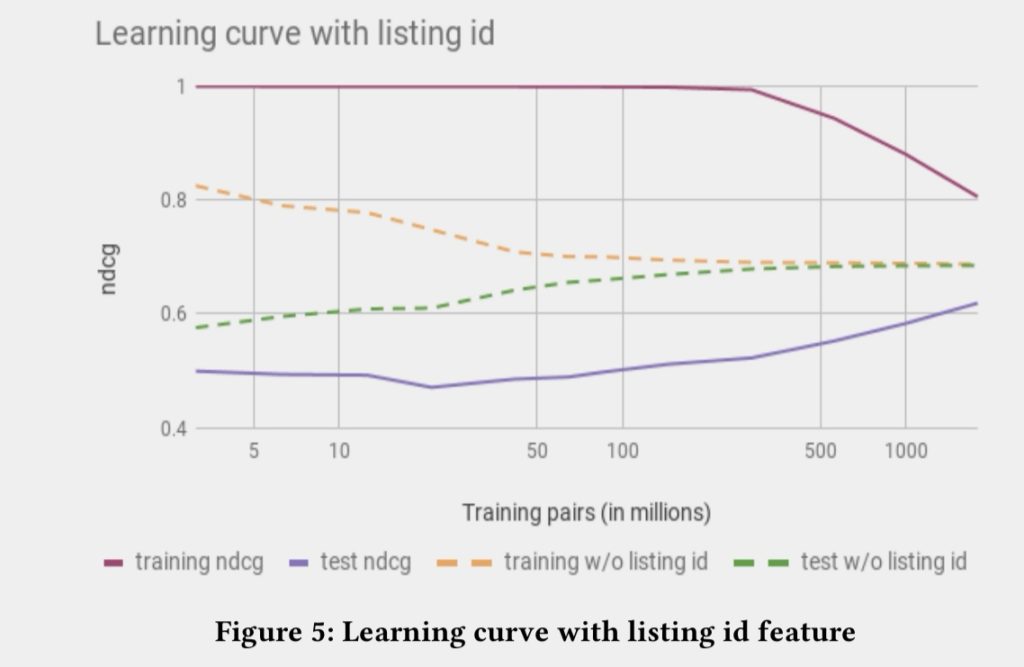
图:增加listing id embedding后,over fitting问题明显严重
第二种:multi-task learning
多任务是现在很多推荐搜索场景中常用的技术,多任务是现在比较fancy的技术,听起来也是make sense的。Airbnb也进行了尝试。
进一步讲,在文中尝试的方向:是认为浏览时间比较长的listing应该会和booked行为有比较强的相关性。所以进行了多任务的学习,在学习的过程当中有两个子任务,一个是booked的子任务,另外一个是预估用户浏览时长的子任务。
多任务模型在低层共用embedding,在上层分成两个任务,并且在loss function中将booked的样本进行加权。线上使用的时候只使用booked子任务进行预估。
但最终线上的结果是用户的浏览是浏览市场的确变长,但是预定基本上没有什么变化,经过分析可能的原因如下
第一是推荐出来的内容描述会比较长,或者描述中带有一些比较独特的东西,或者甚至是比较搞笑,这样用户浏览的时间就变成了,但是并不会影响到对应的预定。
第2个可能的原因,是模型倾向于推荐价格比较高的listing,这样用户会进行浏览,但是最后也没有预定。所以多任务是一个比较有挑战的方向,需要继续进行研究。
Dustinsea: multi-task learning是大趋势,从理论上也是符合逻辑的,但真正应用的时候,需要的投入也比较多,包括对于问题的细致分析,所以可以作为系统成熟阶段需要突破的手段,但在系统的拓荒阶段,不一定是很好的选择。
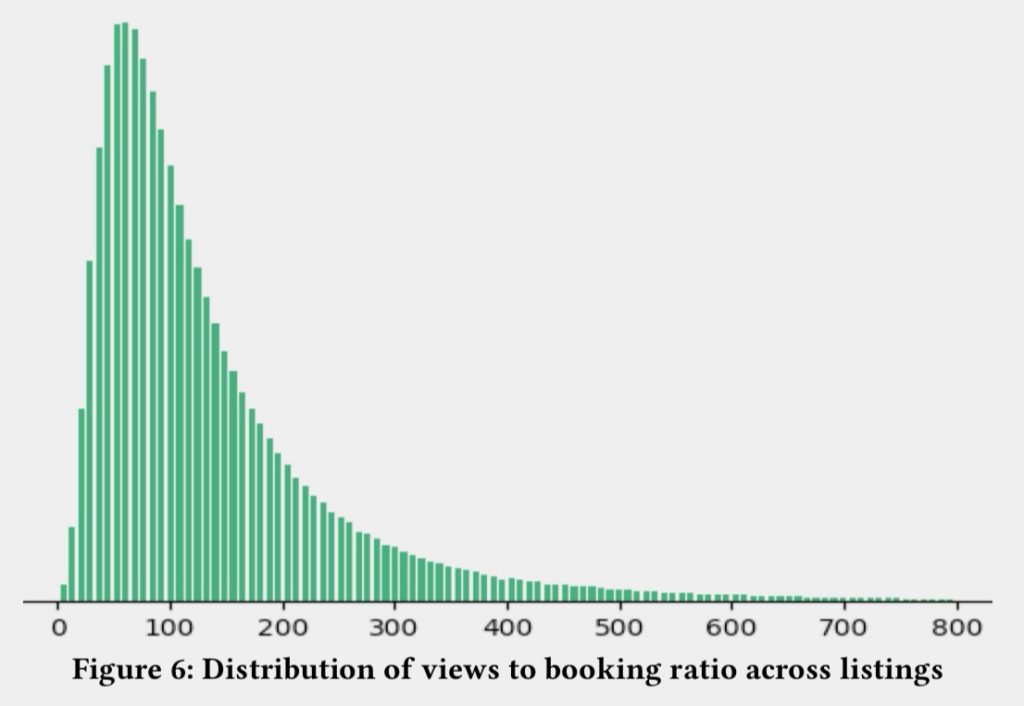
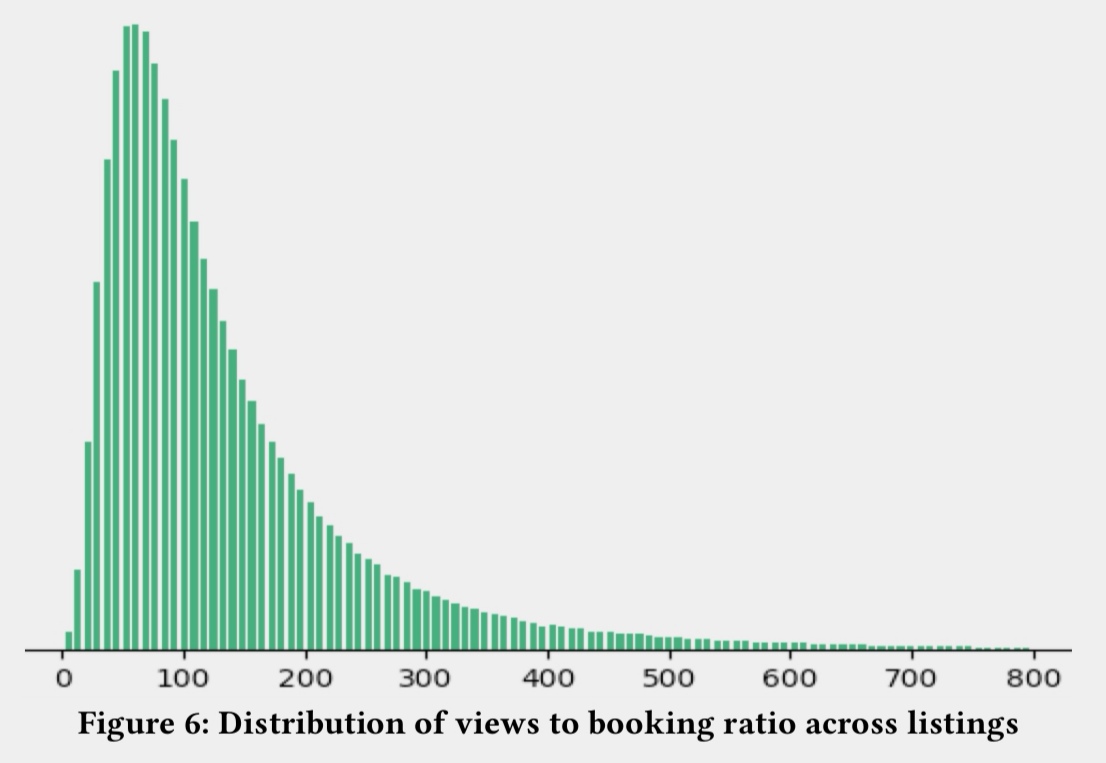
图:下单率分布
特征工程
传统的feature engineering需要很多的时间以及经验,并且中间有很多的tricks才能提升目前的效果,但是这些经验和方法不一定还适用于最新的变化的数据(因为用户的行为是动态变化的,之前人工feature engineering的人工经验知识可能已经迁移)
nn的一个优势就是它能对特征进行自由的组合,不过我们还是需要一部分的特征工程,只是我们的特种工程不再聚焦在我们选择以及如何进行特征变化,更多的是对数据进行统一的预处理,这样nn能够更正确的对特征进行转换和组合。
feature nomalization
gbdt值和特征的相对顺序有关,但是nn会和特征的值有关,所以进行特征的规范化。

图:特征归一化方法
第1种相对进行z score的处理
第2种,如果分布符合指数分布,则进行log的处理
feature distribution
从特征的角度保证特征是平滑的,是比较重要的。因为如果一般特征不平衡,都是存在问题。检查特征是否平滑,有以下好处:
检查数据种是否有bugs
检查如何进行特征变换,例如文中将lng/lat转变为用户和listing的distance
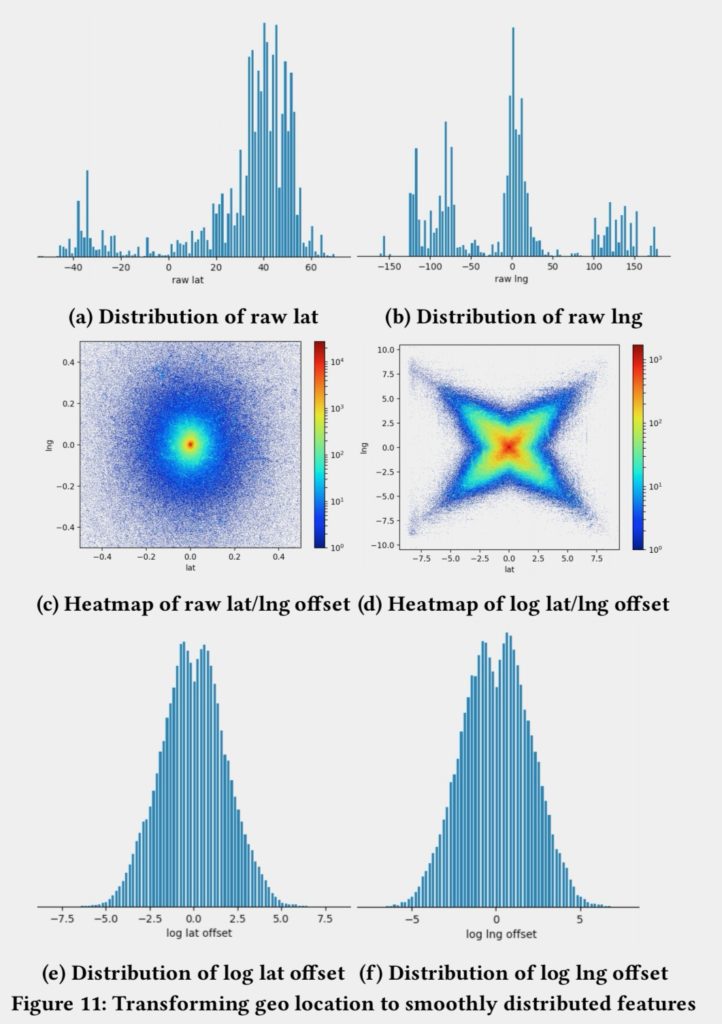
图:经纬度特征分布
超参数
dropout: 一般dropout在nn中都是防止过你和的标配,但在该场景中效果不佳,文中给出的解释是dropout比较像数据增强,相当于引入噪音。文中后续引入了人工构造的噪音, 线下ndcg有1%提升,但线上无变化
initialization:使用xavier initialization方法,比参数默认置0好
Optimizer:文中最后使用的是LazyAdamOptimizer,因为实验中使用Adam发现效果很难再优化
文中最后还是推荐dnn是一个方向,因为能够让大家很大程度上摆脱特征工程,而站到更高的角度上去考虑优化目标的问题。但是整个过程也是比较耗时的,作者认为他们DNN的工作也才刚刚开始。
图:发展历程
reference
原论文参见:https://pan.baidu.com/s/1C0I6AhEWB9h3PV5ZmSPcbQ 提取码:56l4
更多内容参见: www.semocean.com
P.S. 急招推荐,搜索,语音算法人才,阿里P6~P8,欢迎推荐和自荐,简历请发至 haibo.lihaibo@alibaba-inc.com