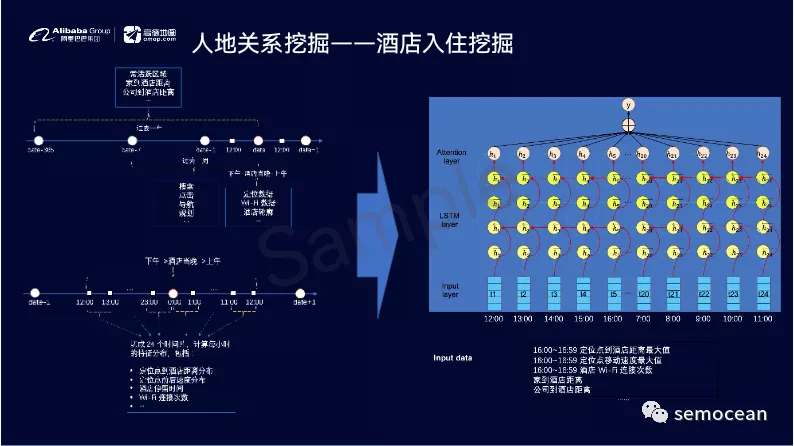
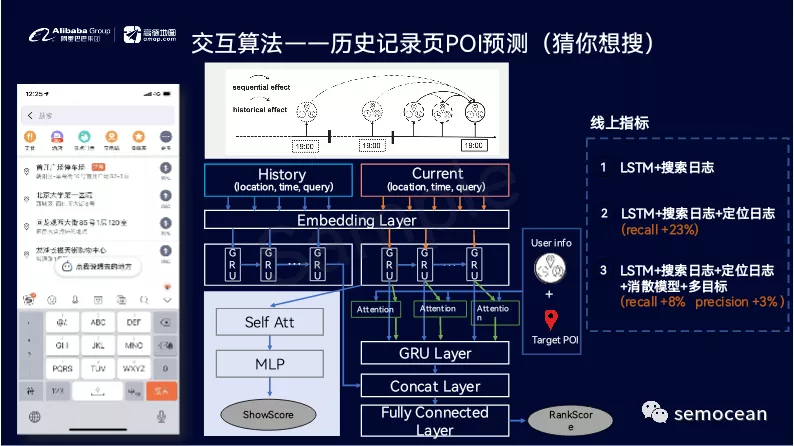
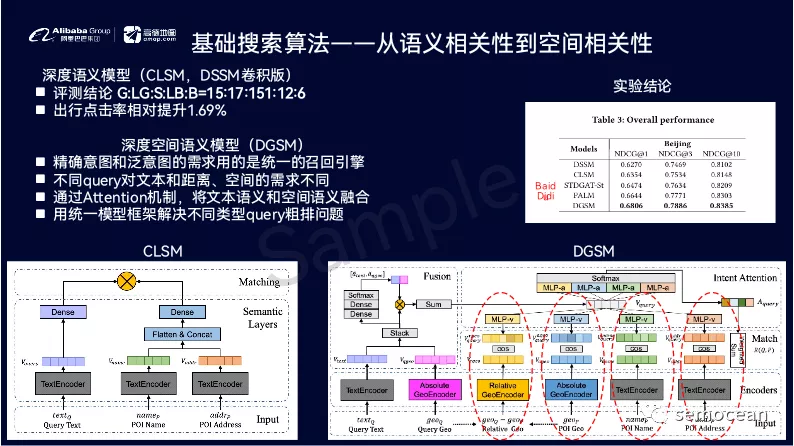
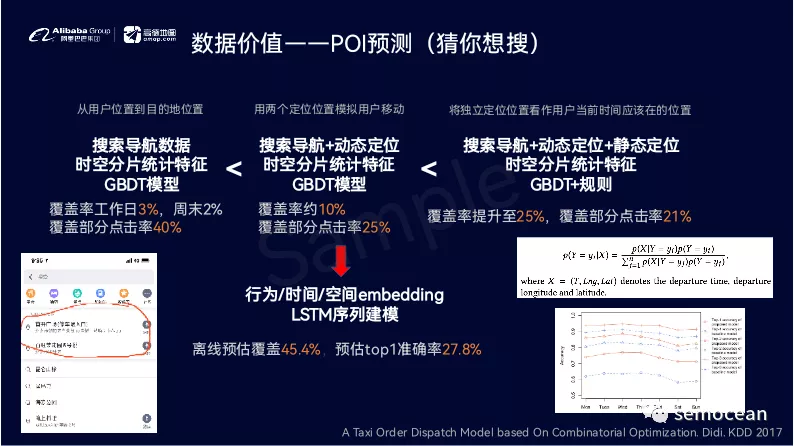
先打个广告: 团队长期招p6~p9数据,工程,算法; 业务发展快。 感兴趣的同学可直接关注以下公众号获取岗位信息:

管理,都和人相关,所以很多时候都是在讲心理学, 无论是更加了解自己, 还是更加了解别人。 同时发现一个比较有意思的现象, 就是中式心理学更关注自己的内心,中式心理学更关注了解自己,提升自己的修养;而西式心理学似乎更功利一些, 不仅探究内心,更在乎如何去影响他人。
今天听了一场讲座,里面提到一个比较有意思的概念,叫知识的诅咒。今天就跟大家聊聊这个概念。

先说一下什么是知识的诅咒,指的是一旦当你掌握某种知识,你就会认为这个事很容易,但是这反过来就会让你去教授或者讲解该内容的时候变得很困难,别人想听懂你教授知识的难度,比你想象中,听众掌握该知识的难度要高得多。
是不是没有理解以上我所说的话?这也是一个知识的诅咒:)
举个形象的例子,网上经常流传着一些段子,就是家长在鸡娃的时候都很崩溃,突然就觉得自己家的娃变傻了,那么简单的问题都不会?
或者我们在公司跟同事沟通的时候,也老觉得对方为什么听不懂我们说的内容,尽管觉得我们说的很清楚,内容也很简单。
这就是知识诅咒的例子:一旦我们掌握了某个知识,我们就觉得这个知识无比简单,但是我们就永远也无法完全理解没有掌握该知识的人的真实情况,就会导致我们认为:掌握该知识的难度和具体学习的人觉得的难度的偏差非常之大。
所以以后在工作当中,不要轻易的去质疑别人为什么听不懂。大家能在同样一个公司工作,教育背景都很优秀,智商都很高,都是通过高考这种千挑万选,独木桥上留下的人选,最大的可能就是你现在正在经历知识的诅咒。这也是一种非常普遍的认识偏差,或者其实也是人天生的一种偏见。一定要客观的看待他,并且尽量的减少它的影响。
所以你好好观察一下,你身边是不是经常会有这样的人:他的智商似乎没有你高,不过他们和别人沟通非常频繁,就会导致他们推进事情更顺畅以及产出更多,更能得到团队的认可。很多时候,这也是他们尽量避免知识诅咒所带来的缺陷,这也是大家在他们身上值得学习的优点。
所以很多时候我们需要尽量的去换位思考,看我们的沟通对象到底是什么样的人?他是不是已经具有了我们足够多的沟通背景知识?沟通的双方是不是已经真的在同样的一个频道上?如何补齐大家的认知偏差?
这也是我最近几年的一个比较大的感悟:同样一个事儿,你站在不同的角度看,会得到完全不一样的答案,甚至是截然相反的答案,但他们都是对的,只是所看的角度和立场不一样罢了。
比如你可以想一想,‘996福报’是不是对? 不一样的人会有完全不一样的答案,例如公司的角度,公司需要的是拼搏精神,而且很多事都是拼刺刀拼出来的,并且冲在最前边的人大概率会有更多的回报。。。。那就应该996!
当然,如果你说我就是要家庭工作平衡,那是不是就完全不一样?
我是经历过创业型公司的,算是近距离看过创业型公司的老板从白手起家到市值做得非常高,财务自由的过程。这种公司的老板非常之拼,比如经常半夜12点发一个微信过来,说有一个特别好的idea想讨论一下,几天之内就需要验证模式是否OK;或者他们基本上在电梯里,在车上都在讨论问题,都在开会,都在和合作伙伴谈生意。
记得之前有一次,和创业公司的老板连线讨论问题,他在国外是当地的半夜,他一边吃刚泡的白天在外边买的泡面,一边和我们开会,而且说没想到国外桶装泡面当里没有叉子,所以就拿卫生间的梳子当叉子,吃着泡面,和我们讨论问题。 又有多少人能够做到这么拼?
别人所吃的苦是我们很难想象的,当然,别人所拥有的财富也是我们所难想象的。
沟通视窗4象限
对于我们在沟通方面的认知,可以使用沟通视窗为4个象限来描述
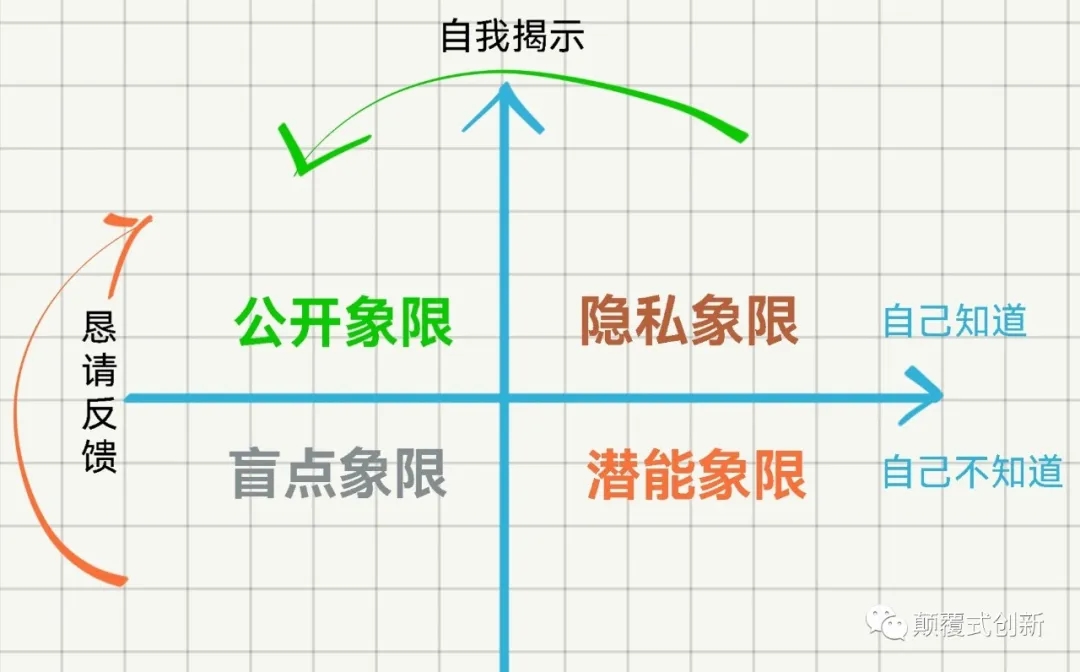
图:沟通视窗4象限
公开象限
每个人都有自己的公开象限,就是别人知道自己到底是一个什么样的人。这个象限的大小,我们是可以控制的,不能说它是越大越好,还是越小越好。这个象限的大小有他的作用,也有它的弊端。
一般情况下,公众人物的这个象限是比较大的,这也会为他们带来好处,例如,他们可以塑造自己正面,积极,阳光的形象,为他们带来名声,之后就会产生相应的利益。
我们看市面上有各种各样的成功学,或者说各种CEO老板的传记,其实他们都在放大自己的公开象限,而且专挑好的说,这些文章或者书籍,也许你在看的时候不知不觉就这些人带来流量作为他们变现的工具,但从你的角度,你可能还以为自己学到了别人成功的经验。是不是很搞笑的一件事?
当然,公开象限比较大,也会带来它的弊端,例如你的隐私会变少,或者会不会你苦心经营或者伪装的人设在瞬间崩塌? 这样的例子其实非常多,比如打工皇帝唐骏,或者各种崩塌的明星。
隐私象限
隐私象限,这个象限和公开象限是相对的,这个象限具体对每个人的大小是可以控制的,到底要公开多少,每个人都会有自己的选择。有些人就会让隐私上线比较大这样这个人就会显得比较低调,这样的人一般不容易出事儿,但是因为别人对你不太了解,所以跟你就会产生距离感。
盲点象限
这个上线也是很大的每个人都有,而且很多时候处理不好是很致命的.一般的人有网点上线可能更多的是因为自己的认知偏差,很多绝顶聪明,并且又有非常多阅历的人,也经常会陷入盲点象限, 特别是当他们位高权重掌握各种利益分配权利的时候。
举个例子,在袁世凯的晚期,他所有的手下都在骗他,甚至手下还专门出了一份供袁世凯看的报纸,全北京这份报纸就只给袁世凯看,让他以为他称帝是民心所向。。多么恐怖的一件事。
但比较搞笑的是,我之前听百度的同事也提到,之前百度信息流有一个专门供李彦宏看的版本,老板看到的内容跟其他用户看到的是不一样的。。。历史是何等相似且在不断重复,真是细思极恐。
所以不管是谁,忠言逆耳,兼听则明。人性都是喜欢听好话,但当听到别人说自己不好的一方面时,那最好先冷静下来想一想,是不是别人正在说自己的盲点象限。
潜能象限
这是一个非常大的象限,每个人的潜能象限都特别大,而且我们每个人一生都致力于开发潜能象限。记得之前听到一种说法,好像说是字节,张一鸣说的:姜子牙80多岁才辅助周武王平定天下那他之前在干什么呢?主要就在读书和锻炼身体,我们可以认为他就是在不断的开发潜能上限。
而对于我们这些寻常人来说,确实,随着年龄的增长,身体的机能和精力是在下降的,但是如果保持一个年轻的心态,不断学习,不断探索,其实我们永远能够取得超乎我们想象的成绩。
在阿里,大家不断的在提升,大家的压力也非常大,环境也逼着大家不断的去挑战自己,也经常说一句土话,今天最好的表现是明天最低的要求,其实我觉得背后也是要把大家的潜能逼出来。
特别是很多问题,我们需要放在时间的维度去考虑。例如我到阿里之后,其实我从来没有去过健身房,也没有刻意的锻炼,但我觉得我的身体素质是是在变好的,随便爬个十多层的楼梯,可以小跑的速度上去,原因很简单,每天坚持做50个俯卧撑,几分钟就搞定。 简单却并不容易,坚持下来, 会发现很不一样。
所以大家一定要保持一个年轻的心态,就像小孩一样的求知欲。